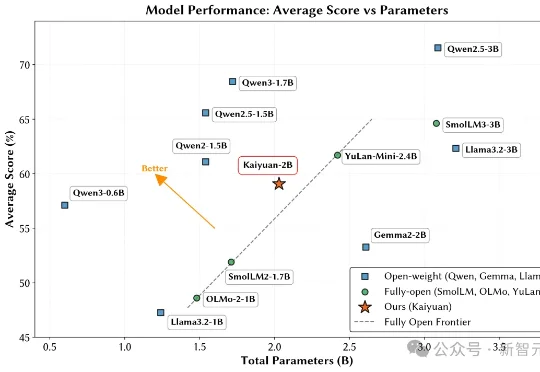
只靠国产算力预训练,稳!全流程开源,「开元」盛世真来了
只靠国产算力预训练,稳!全流程开源,「开元」盛世真来了鹏城实验室与清华大学PACMAN实验室联合发布了鹏城脑海‑2.1‑开元‑2B(PCMind‑2.1‑Kaiyuan‑2B,简称开元‑2B)模型,并以全流程开源的方式回应了这一挑战——从训练数据、数据处理框架、训练框架、完整技术报告到最终模型权重,全部开源。
来自主题: AI技术研报
9276 点击 2025-12-21 12:38
 搜索
搜索
鹏城实验室与清华大学PACMAN实验室联合发布了鹏城脑海‑2.1‑开元‑2B(PCMind‑2.1‑Kaiyuan‑2B,简称开元‑2B)模型,并以全流程开源的方式回应了这一挑战——从训练数据、数据处理框架、训练框架、完整技术报告到最终模型权重,全部开源。
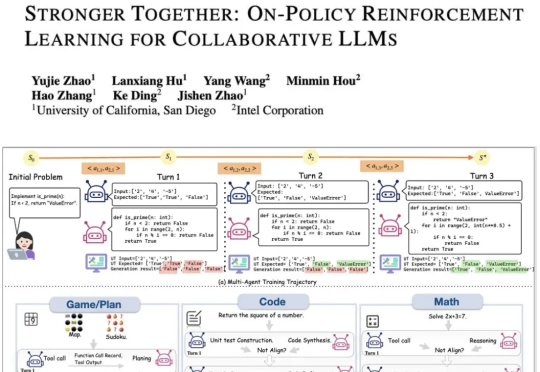
现有的LLM智能体训练框架都是针对单智能体的,多智能体的“群体强化”仍是一个亟须解决的问题。为了解决这一领域的研究痛点,来自UCSD和英特尔的研究人员,提出了新的提出通用化多智能体强化学习框架——PettingLLMs。支持任意组合的多个LLM一起训练。
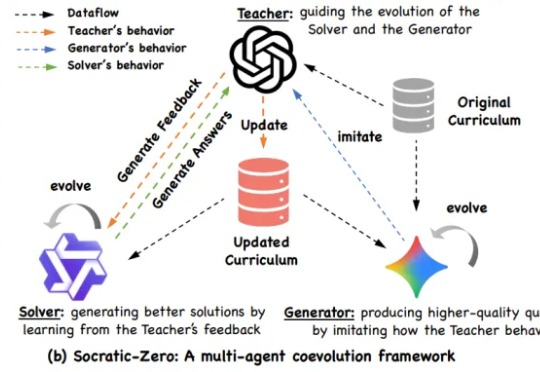
阿里巴巴与上海交通大学 EPIC Lab 联合提出 Socratic-Zero,一个完全无外部数据依赖的自主推理训练框架。该方法仅从 100 个种子问题出发,通过三个智能体的协同进化,自动生成高质量、难度自适应的课程,并持续提升模型推理能力。
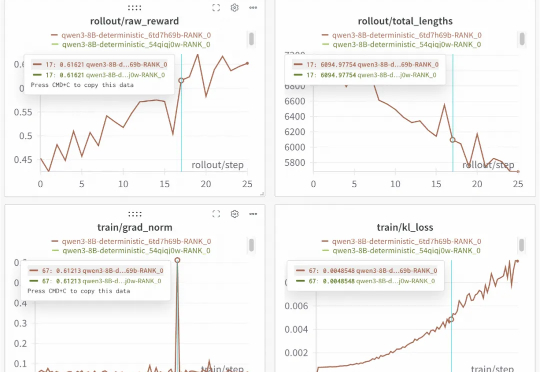
开源框架实现100%可复现的稳定RL训练!下图是基于Qwen3-8B进行的重复实验。两次运行,一条曲线,实现了结果的完美重合,为需要高精度复现的实验场景提供了可靠保障。这就是SGLang团队联合slime团队的最新开源成果。

姚班、伯克利、OpenAI、清华……年仅 30 多岁的吴翼身上已经聚集了众多亮眼的标签。
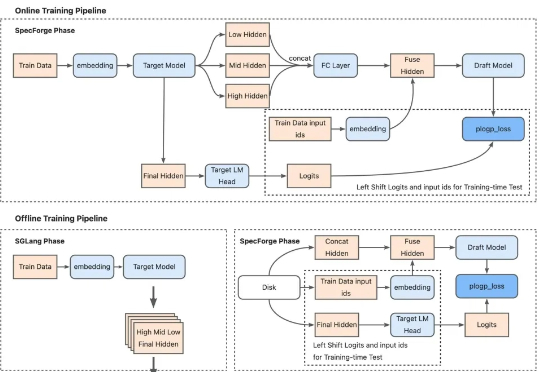
专门适用超大模型、带来2.18倍推理加速,最新投机采样训练框架开源! SGLang团队联合美团搜推平台、Cloudsway.AI开源SpecForge。
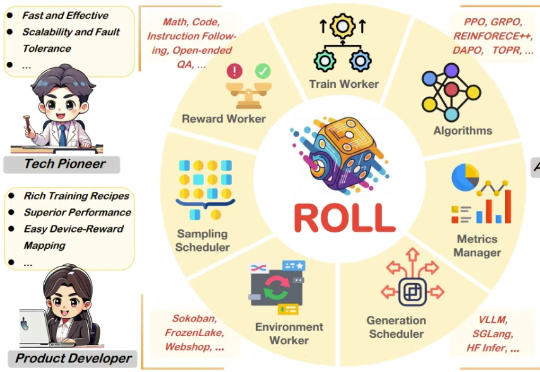
过去几年,随着基于人类偏好的强化学习(Reinforcement Learning from Human Feedback,RLHF)的兴起,强化学习(Reinforcement Learning,RL)已成为大语言模型(Large Language Model,LLM)后训练阶段的关键技术。
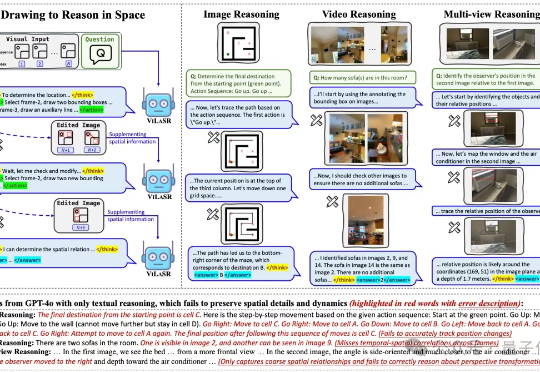
“边看边画,边画边想”,让大模型掌握空间思考能力,结果直接实现空间推理任务新SOTA。

新加坡国立大学等机构的研究者们通过元能力对齐的训练框架,模仿人类推理的心理学原理,将演绎、归纳与溯因能力融入模型训练。实验结果显示,这一方法不仅提升了模型在数学与编程任务上的性能,还展现出跨领域的可扩展性。

当前,强化学习(RL)方法在最近模型的推理任务上取得了显著的改进,比如 DeepSeek-R1、Kimi K1.5,显示了将 RL 直接用于基础模型可以取得媲美 OpenAI o1 的性能不过,基于 RL 的后训练进展主要受限于自回归的大语言模型(LLM),它们通过从左到右的序列推理来运行。