AI哪怕答案正确,逻辑链却惨不忍睹,奥数级不等式证明成功率不到50%| 斯坦福&伯克利&MIT
AI哪怕答案正确,逻辑链却惨不忍睹,奥数级不等式证明成功率不到50%| 斯坦福&伯克利&MIT大语言模型解决不等式证明问题时,可以给出正确答案,但大多数时候是靠猜。推理过程经不起推敲,逻辑完全崩溃。
来自主题: AI技术研报
7885 点击 2025-06-20 09:48
 搜索
搜索
大语言模型解决不等式证明问题时,可以给出正确答案,但大多数时候是靠猜。推理过程经不起推敲,逻辑完全崩溃。

GRIT能让多模态大语言模型(MLLM)通过生成自然语言和图像框坐标结合的推理链进行「图像思维」,仅需20个训练样本即可实现优越性能!

近年来,大型语言模型(LLM)在处理复杂任务方面取得了显著进展,尤其体现在多步推理、工具调用以及多智能体协作等高级应用中。这些能力的提升,往往依赖于模型内部一系列复杂的「思考」过程或 Agentic System 中的 Agent 间频繁信息交互。

近期,人工智能领域对“具身智能”的讨论持续升温——如何让AI不仅能“理解”语言,还能用“手”去感知世界、操作环境、完成任务?相比语言模型的迅猛发展,真正通向Agent的下一步,需要AI具备跨模态感知、动作控制与现实泛化能力。具身智能让AI不仅能“思考”,更能“感知”“行动”。
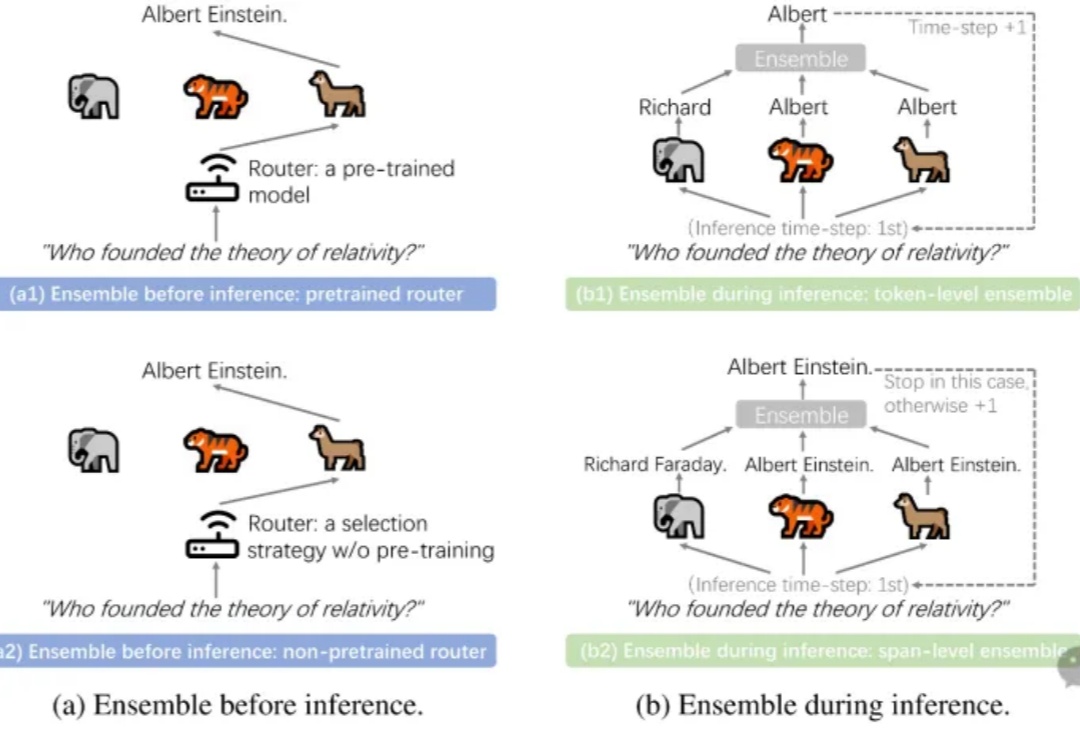
LLM Ensemble(大语言模型集成)在近年来快速地获得了广泛关注。它指的是在下游任务推理阶段,综合考虑并利用多个大语言模型(每个模型都旨在处理用户查询),从而发挥它们各自的优势。大语言模型的广泛可得性,以及其开箱即用的特性和各个模型所具备的不同优势,极大地推动了 LLM Ensemble 领域的发展。
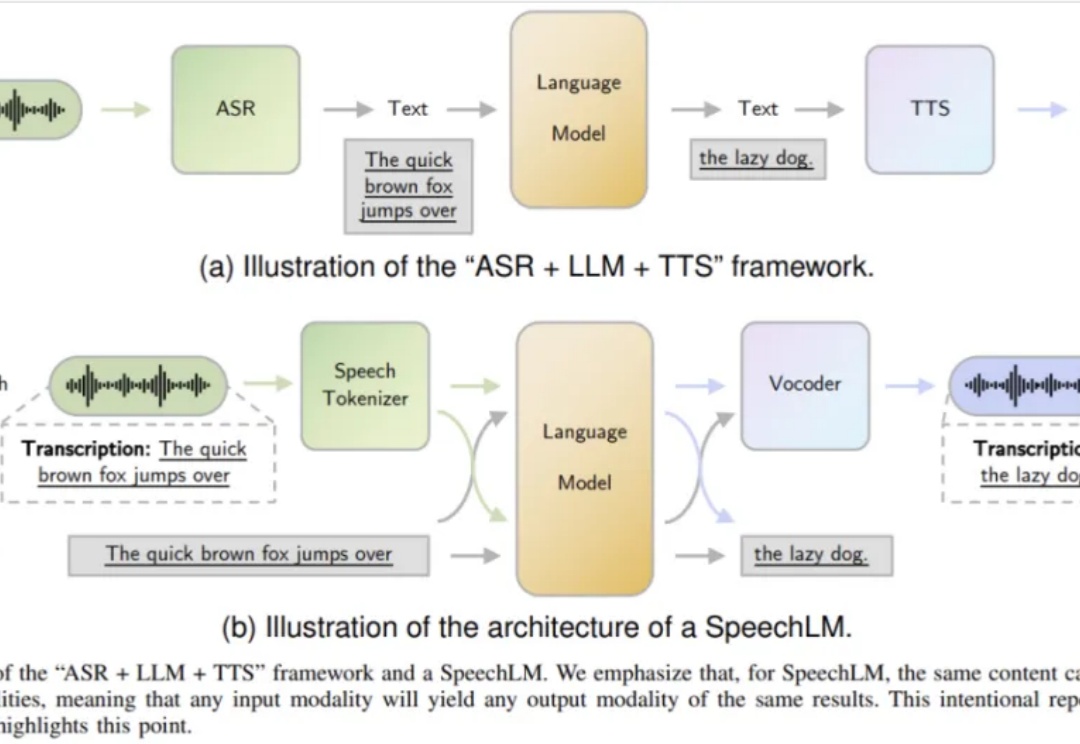
由香港中文大学团队撰写的语音语言模型综述论文《Recent Advances in Speech Language Models: A Survey》已成功被 ACL 2025 主会议接收!这是该领域首个全面系统的综述,为语音 AI 的未来发展指明了方向。

思维链(Chain of Thought, CoT)推理方法已被证明能够显著提升大语言模型(LLMs)在复杂任务中的表现。而在多模态大语言模型(MLLMs)中,CoT 同样展现出了巨大潜力。
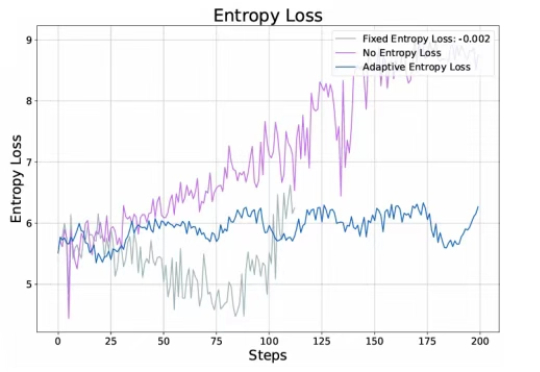
近年来,链式推理和强化学习已经被广泛应用于大语言模型,让大语言模型的推理能力得到了显著提升。

当前,Agentic RAG(Retrieval-Augmented Generation)正逐步成为大型语言模型访问外部知识的关键路径。但在真实实践中,搜索智能体的强化学习训练并未展现出预期的稳定优势。一方面,部分方法优化的目标与真实下游需求存在偏离,另一方面,搜索器与生成器间的耦合也影响了泛化与部署效率。

在金融科技智能化转型进程中,大语言模型以及多模态大模型(LVLM)正成为核心技术驱动力。尽管 LVLM 展现出卓越的跨模态认知能力