
大模型强化学习新突破——SPO新范式助力大模型推理能力提升!
大模型强化学习新突破——SPO新范式助力大模型推理能力提升!当前,强化学习(RL)在提升大语言模型(LLM)推理能力方面展现出巨大潜力。DeepSeek R1、Kimi K1.5 和 Qwen 3 等模型充分证明了 RL 在增强 LLM 复杂推理能力方面的有效性。
来自主题: AI技术研报
8681 点击 2025-06-09 11:02
 搜索
搜索
当前,强化学习(RL)在提升大语言模型(LLM)推理能力方面展现出巨大潜力。DeepSeek R1、Kimi K1.5 和 Qwen 3 等模型充分证明了 RL 在增强 LLM 复杂推理能力方面的有效性。

通过这份全面指南探索大语言模型(LLMs)的关键概念、技术和挑战,专为AI爱好者和准备面试的专业人士精心打造。
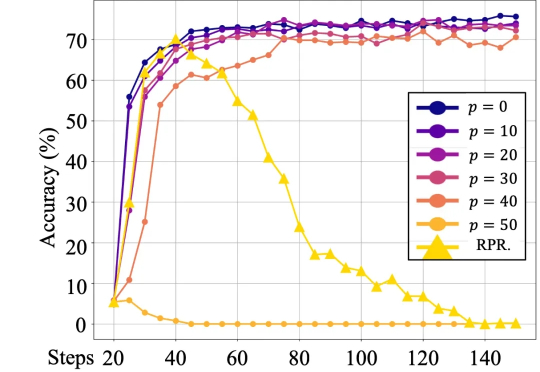
最近的一篇论文中,来自人大和腾讯的研究者们的研究表明,语言模型对强化学习中的奖励噪音具有鲁棒性,即使翻转相当一部分的奖励(例如,正确答案得 0 分,错误答案得 1 分),也不会显著影响下游任务的表现。
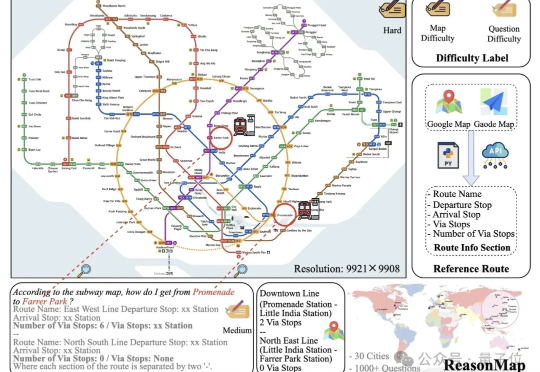
近年来,大语言模型(LLMs)以及多模态大模型(MLLMs)在多种场景理解和复杂推理任务中取得突破性进展。
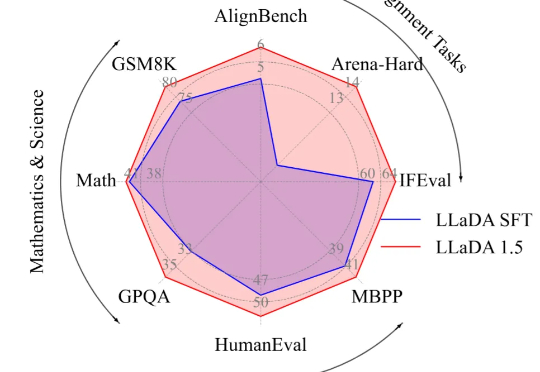
本文介绍的工作由中国人民大学高瓴人工智能学院李崇轩、文继荣教授团队与蚂蚁集团共同完成。朱峰琪、王榕甄、聂燊是中国人民大学高瓴人工智能学院的博士生,导师为李崇轩副教授。
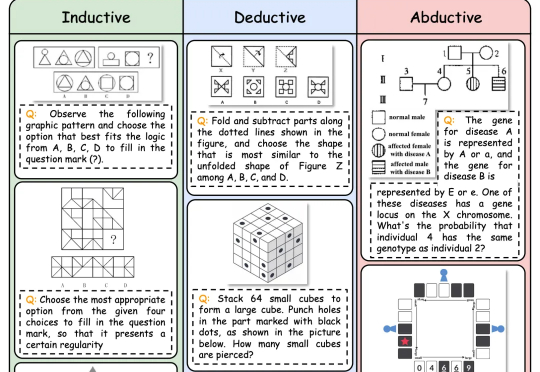
逻辑推理是人类智能的核心能力,也是多模态大语言模型 (MLLMs) 的关键能力。随着DeepSeek-R1等具备强大推理能力的LLM的出现,研究人员开始探索如何将推理能力引入多模态大模型(MLLMs)
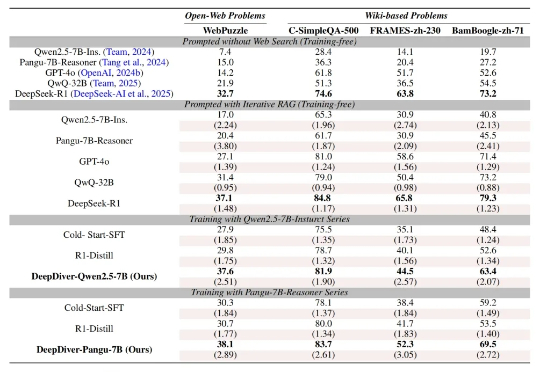
大型语言模型 (LLM) 的发展日新月异,但实时「内化」与时俱进的知识仍然是一项挑战。如何让模型在面对复杂的知识密集型问题时,能够自主决策获取外部知识的策略?
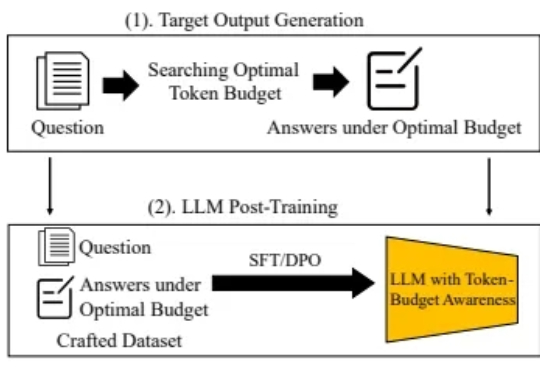
随着大型语言模型(LLM)技术的不断发展,Chain-of-Thought(CoT) 等推理增强方法被提出,以期提升模型在数学题解、逻辑问答等复杂任务中的表现,并通过引导模型逐步思考,有效提高了模型准确率。
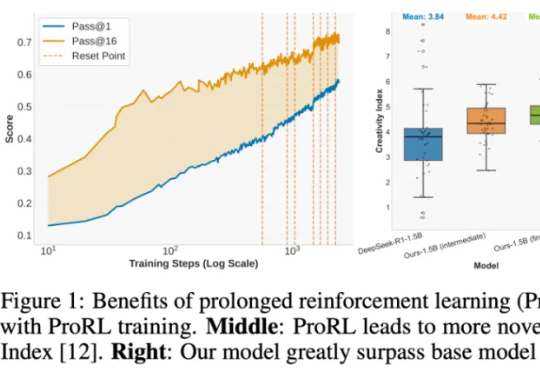
强化学习(RL)到底是语言模型能力进化的「发动机」,还是只是更努力地背题、换个方式答题?这个问题,学界争论已久:RL 真能让模型学会新的推理技能吗,还是只是提高了已有知识的调用效率?

GPT 系列模型的记忆容量约为每个参数 3.6 比特。