大模型也有"健忘症"?Supermemory让AI拥有"超级记忆",一行代码解锁无限对话!
大模型也有"健忘症"?Supermemory让AI拥有"超级记忆",一行代码解锁无限对话!,即使是最强大的大语言模型也有"健忘症"!但现在,Supermemory提出的创新解决方案横空出世,声称只需一行代码,就能让任何AI拥有"无限记忆"能力。这到底是怎么回事?今天我们就来一探究竟!
来自主题: AI资讯
11946 点击 2025-05-19 09:39
 搜索
搜索
,即使是最强大的大语言模型也有"健忘症"!但现在,Supermemory提出的创新解决方案横空出世,声称只需一行代码,就能让任何AI拥有"无限记忆"能力。这到底是怎么回事?今天我们就来一探究竟!
自回归(AR)范式凭借将语言转化为离散 token 的核心技术,在大语言模型领域大获成功 —— 从 GPT-3 到 GPT-4o,「next-token prediction」以简单粗暴的因果建模横扫语言领域。
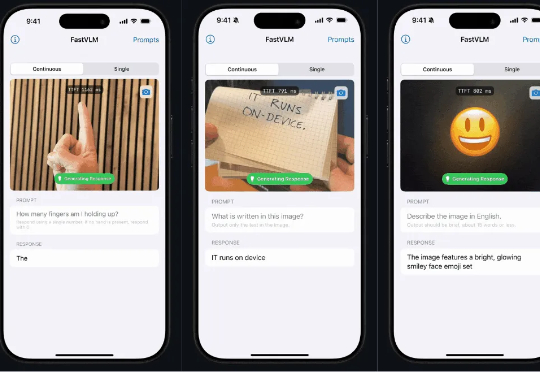
FastVLM—— 让苹果手机拥有极速视觉理解能力
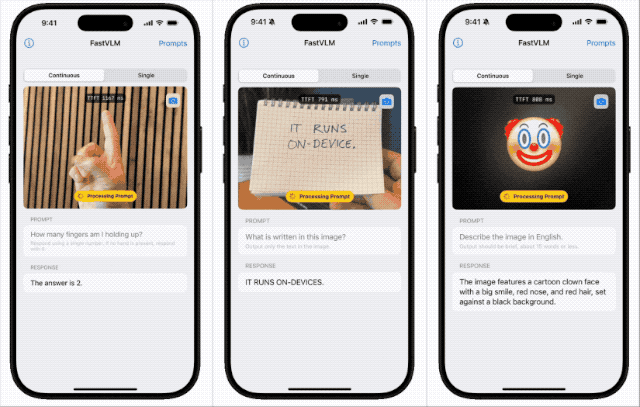
苹果近期开源本地端侧视觉语言模型FastVLM,支持iPhone等设备本地运行,具备快速响应、低延迟和多设备适配特性。该模型依托自研框架MLX和视觉架构FastViT-HD,通过算法优化实现高效推理,或为未来智能眼镜等新硬件铺路,体现苹果将AI深度嵌入系统底层的战略布局。
你以为PDF只是用来阅读文档的?这次它彻底颠覆了你的想象!极客Aiden Bai最新整活——直接把大语言模型(LLM)塞进PDF里,打开文件就能让AI讲故事、陪你聊天!更夸张的是,连Linux系统都能在PDF里运行。
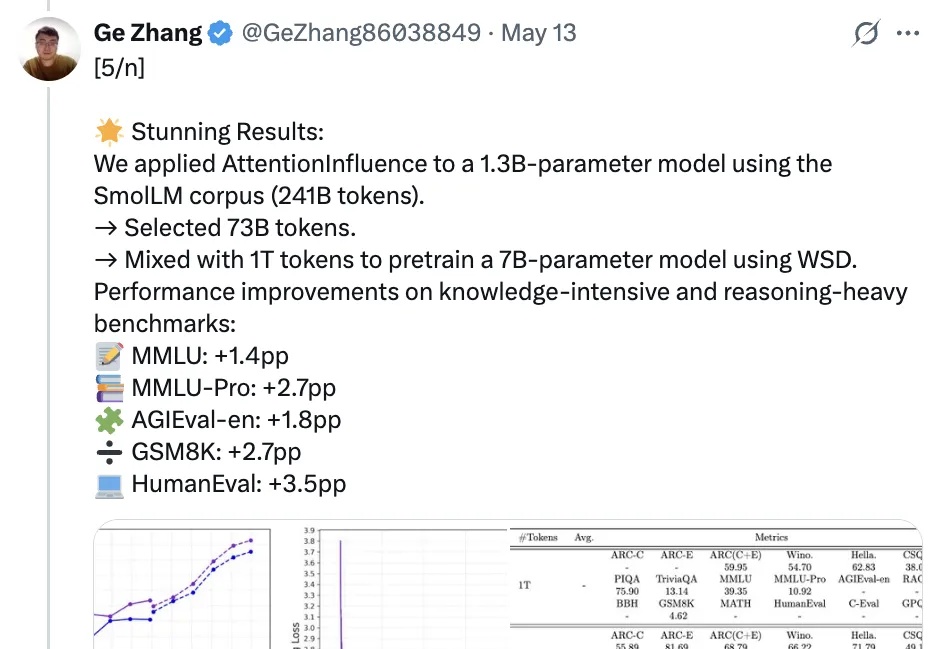
和人工标记数据说拜拜,利用预训练语言模型中的注意力机制就能选择可激发推理能力的训练数据!

多年来,生成式AI供应商一直向公众保证,大语言模型符合安全准则,并加强了对产生有害内容的侵害。然而,一种看似简单但非常有效的提示词策略,能够让所有主流大模型开启「无限制模式」。

DeepSeek最新论文深入剖析了V3/R1的开发历程,揭示了硬件与大语言模型架构协同设计的核心奥秘。论文展示了如何突破内存、计算和通信瓶颈,实现低成本、高效率的大规模AI训练与推理。不仅总结了实践经验,还为未来AI硬件与模型协同设计提出了建议。
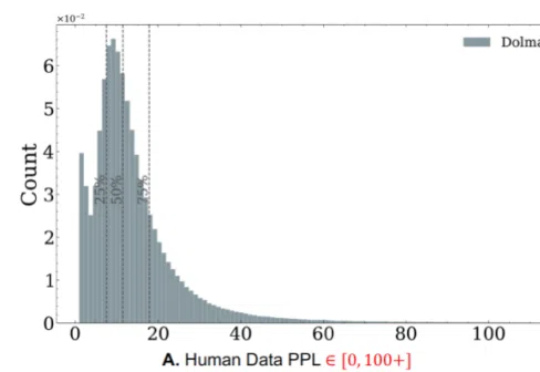
随着生成式人工智能技术的飞速发展,合成数据正日益成为大模型训练的重要组成部分。未来的 GPT 系列语言模型不可避免地将依赖于由人工数据和合成数据混合构成的大规模语料。
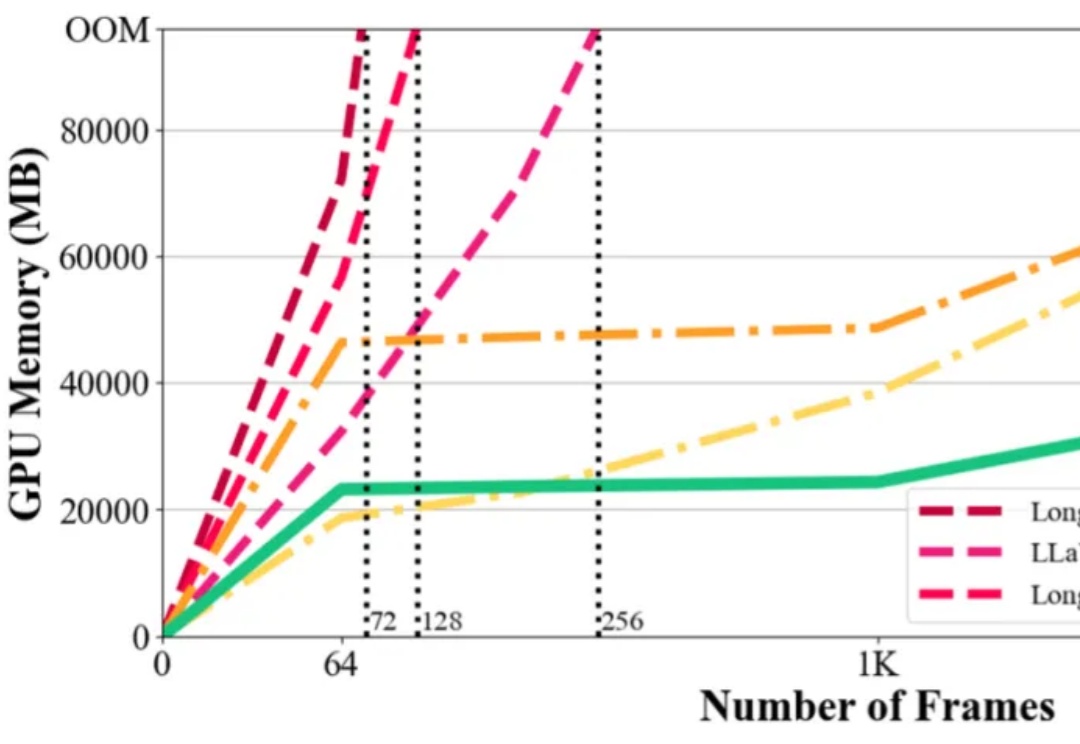
在视觉语言模型(Vision-Language Models,VLMs)取得突破性进展的当下,长视频理解的挑战显得愈发重要。以标准 24 帧率的标清视频为例,仅需数分钟即可产生逾百万的视觉 token,这已远超主流大语言模型 4K-128K 的上下文处理极限。