
只花9美元,推理能力暴涨20%!小模型Tina震撼登场,成本缩减260倍
只花9美元,推理能力暴涨20%!小模型Tina震撼登场,成本缩减260倍在人工智能领域,语言模型的发展日新月异,推理能力作为语言模型的核心竞争力之一,一直是研究的焦点,许多的 AI 前沿人才对 AI 推理的效率进行研究。
来自主题: AI技术研报
10016 点击 2025-04-30 18:40
 搜索
搜索
在人工智能领域,语言模型的发展日新月异,推理能力作为语言模型的核心竞争力之一,一直是研究的焦点,许多的 AI 前沿人才对 AI 推理的效率进行研究。
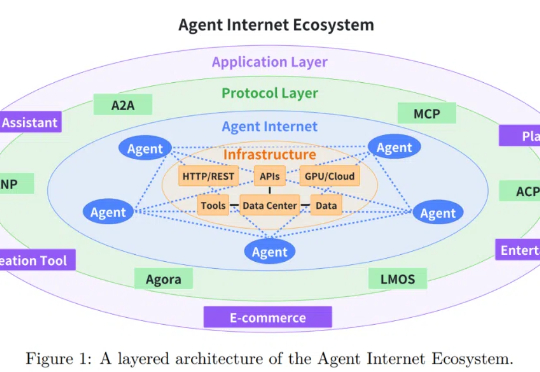
随着大语言模型 (LLM) 技术的迅猛发展,基于 LLM 的智能智能体在客户服务、内容创作、数据分析甚至医疗辅助等多个行业领域得到广泛应用。
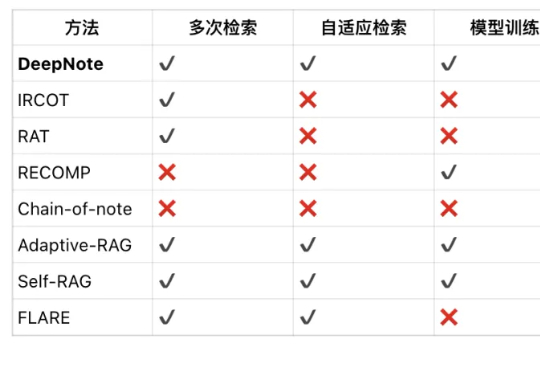
在当前大语言模型(LLMs)广泛应用于问答、对话等任务的背景下,如何更有效地结合外部知识、提升模型对复杂问题的理解与解答能力,成为 RAG(Retrieval-Augmented Generation)方向的核心挑战。
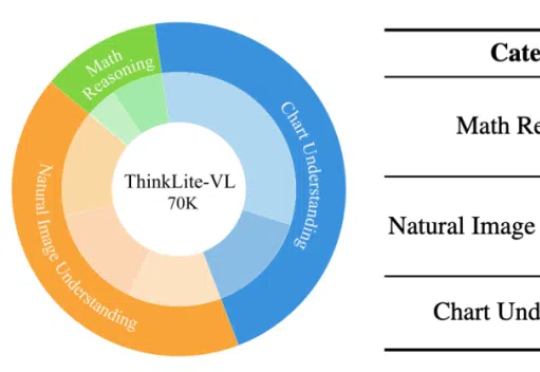
通过蒙特卡洛树搜索筛选高难度样本,ThinkLite-VL仅用少量数据就能显著提升视觉语言模型的推理能力,无需知识蒸馏,为高效训练提供了新思路。
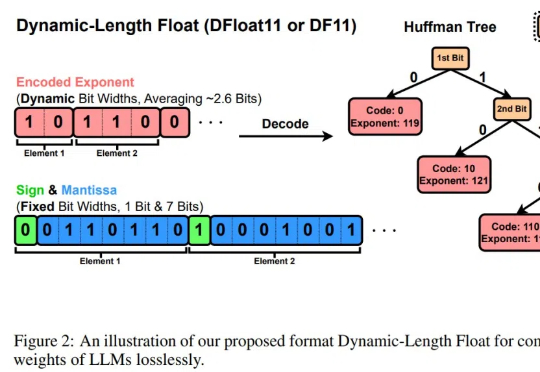
大型语言模型(LLMs)在广泛的自然语言处理(NLP)任务中展现出了卓越的能力。
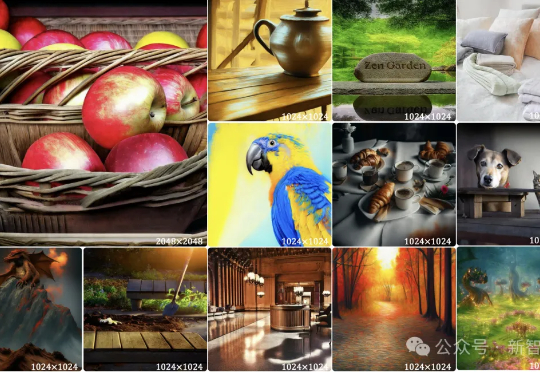
自回归模型,首次生成2048×2048分辨率图像!来自Meta、西北大学、新加坡国立大学等机构的研究人员,专门为多模态大语言模型(MLLMs)设计的TokenShuffle,显著减少了计算中的视觉Token数量,提升效率并支持高分辨率图像合成。
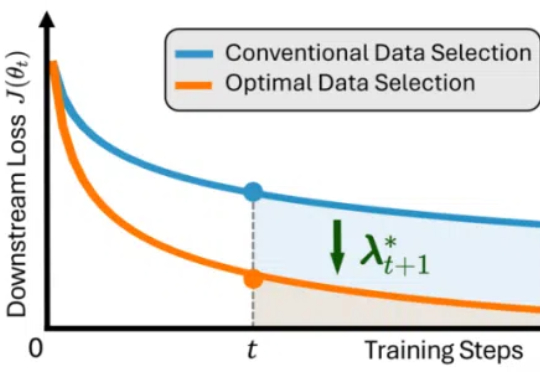
近年来,大语言模型(LLMs)在自然语言理解、代码生成与通用推理等任务上取得了显著进展,逐步成为通用人工智能的核心基石。

随着大型语言模型(LLMs)日益融入关键决策场景,其元认知能力——即识别、评估和表达自身知识边界的能力——变得尤为重要。
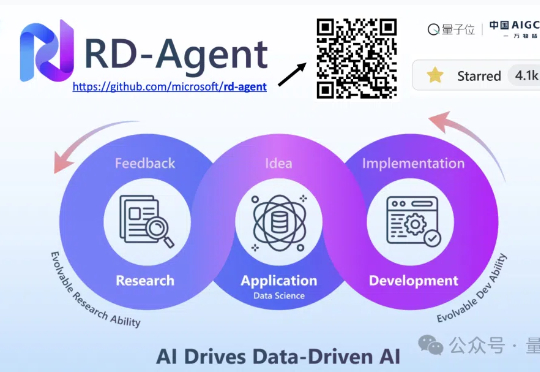
2025,随着大语言模型技术的迅猛发展,数据科学领域正经历一场静默的革命。传统的特征工程、模型训练与迭代优化流程,正被智能化的研发助手所改变。
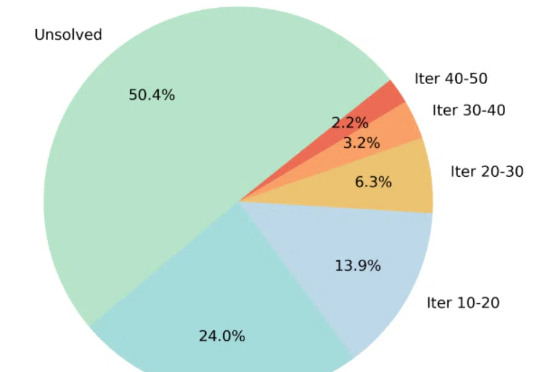
通过蒙特卡洛树搜索筛选高难度样本,ThinkLite-VL仅用少量数据就能显著提升视觉语言模型的推理能力,无需知识蒸馏,为高效训练提供了新思路。