
速递|开源模式的悖论:Meta寻求微软、亚马逊资助,却难舍Llama控制权
速递|开源模式的悖论:Meta寻求微软、亚马逊资助,却难舍Llama控制权据知情人士透露,过去一年中,Meta Platforms 曾请求微软、亚马逊等公司协助承担其旗舰大语言模型 Llama 的训练成本。该想法反映出对 AI 开发成本激增日益加剧的担忧,企业对资助开源软件犹豫不决。
来自主题: AI资讯
2242 点击 2025-04-18 14:01
 搜索
搜索
据知情人士透露,过去一年中,Meta Platforms 曾请求微软、亚马逊等公司协助承担其旗舰大语言模型 Llama 的训练成本。该想法反映出对 AI 开发成本激增日益加剧的担忧,企业对资助开源软件犹豫不决。

最近,来自大连理工和莫纳什大学的团队提出了物理真实的视频生成框架 VLIPP。通过利用视觉语言模型来将物理规律注入到视频扩散模型的方法来提升视频生成中的物理真实性。

早在去年10月底IBM推出了PDL声明式提示编程语言,本篇是基于PDL的一种对Agent的自动优化方法,是工业界前沿的解决方案。当你在开发基于大语言模型的Agent产品时,是否曾经在提示模式选择和优化上浪费了大量时间?在各种提示模式(Zero-Shot、CoT、ReAct、ReWOO等)中选择最佳方案,再逐字斟酌提示内容,这一过程不仅耗时,而且常常依赖经验和直觉而非数据驱动的决策。
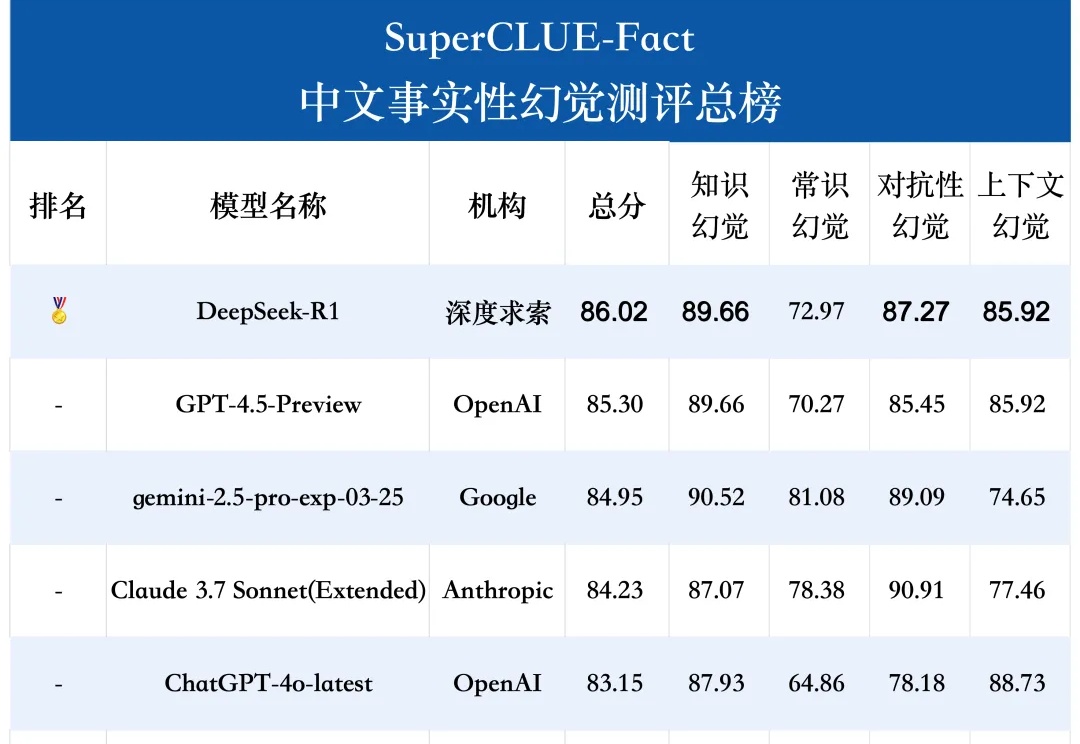
SuperCLUE-Fact是专门评估大语言模型在中文短问答中识别和应对事实性幻觉的测试基准。测评任务包括知识、常识、对抗性和上下文幻觉。
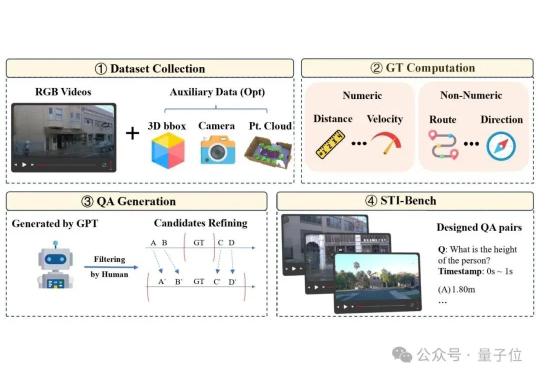
多模态大语言模型(MLLM)在具身智能和自动驾驶“端到端”方案中的应用日益增多,但它们真的准备好理解复杂的物理世界了吗?
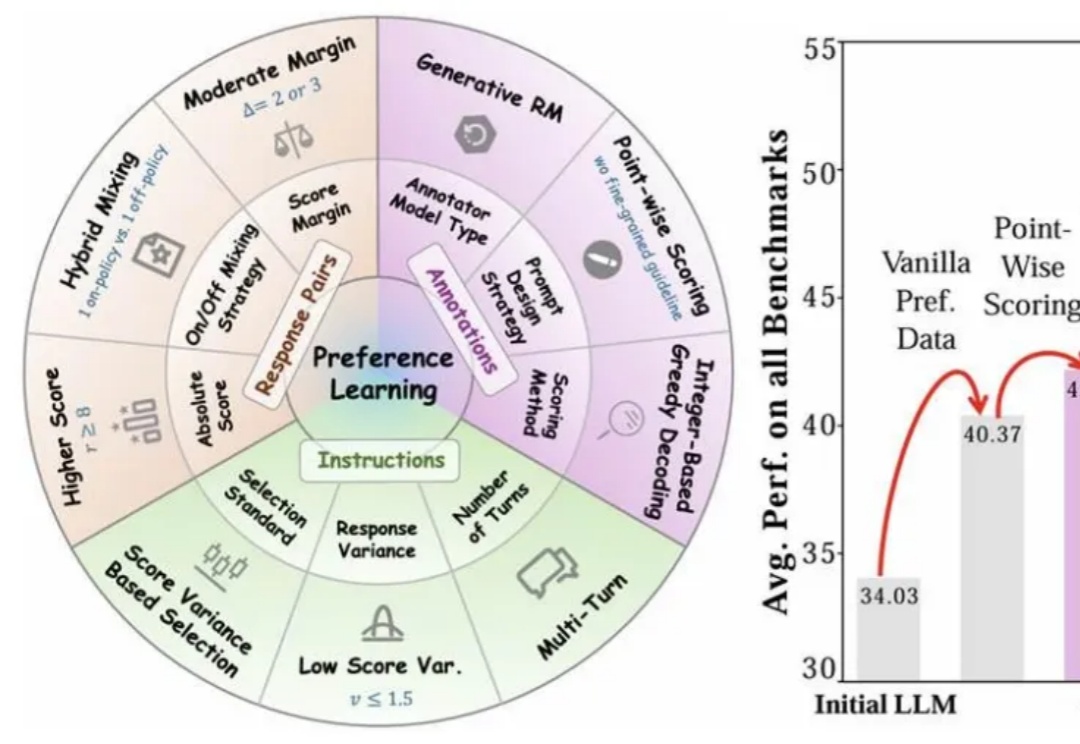
近年来,大语言模型(LLMs)的对齐研究成为人工智能领域的核心挑战之一,而偏好数据集的质量直接决定了对齐的效果。无论是通过人类反馈的强化学习(RLHF),还是基于「RL-Free」的各类直接偏好优化方法(例如 DPO),都离不开高质量偏好数据集的构建。
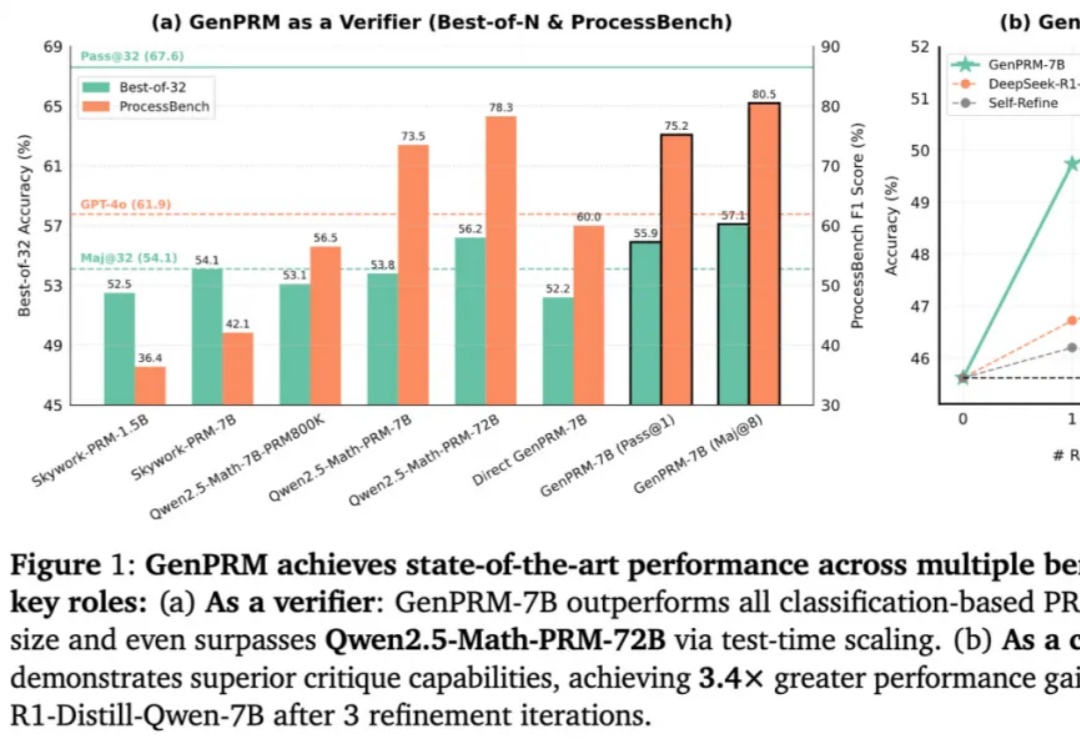
随着 OpenAI o1 和 DeepSeek R1 的爆火,大语言模型(LLM)的推理能力增强和测试时扩展(TTS)受到广泛关注。然而,在复杂推理问题中,如何精准评估模型每一步回答的质量,仍然是一个亟待解决的难题。传统的过程奖励模型(PRM)虽能验证推理步骤,但受限于标量评分机制,难以捕捉深层逻辑错误,且其判别式建模方式限制了测试时的拓展能力。
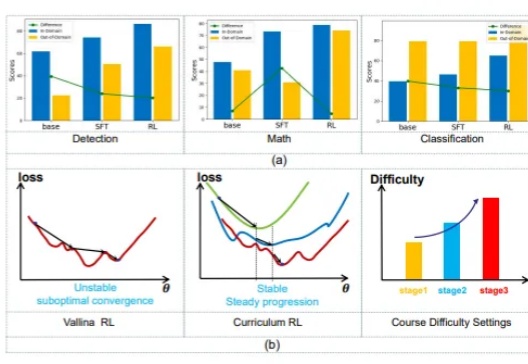
近年来,随着大型语言模型(LLMs)的快速发展,多模态理解领域取得了前所未有的进步。像 OpenAI、InternVL 和 Qwen-VL 系列这样的最先进的视觉-语言模型(VLMs),在处理复杂的视觉-文本任务时展现了卓越的能力。
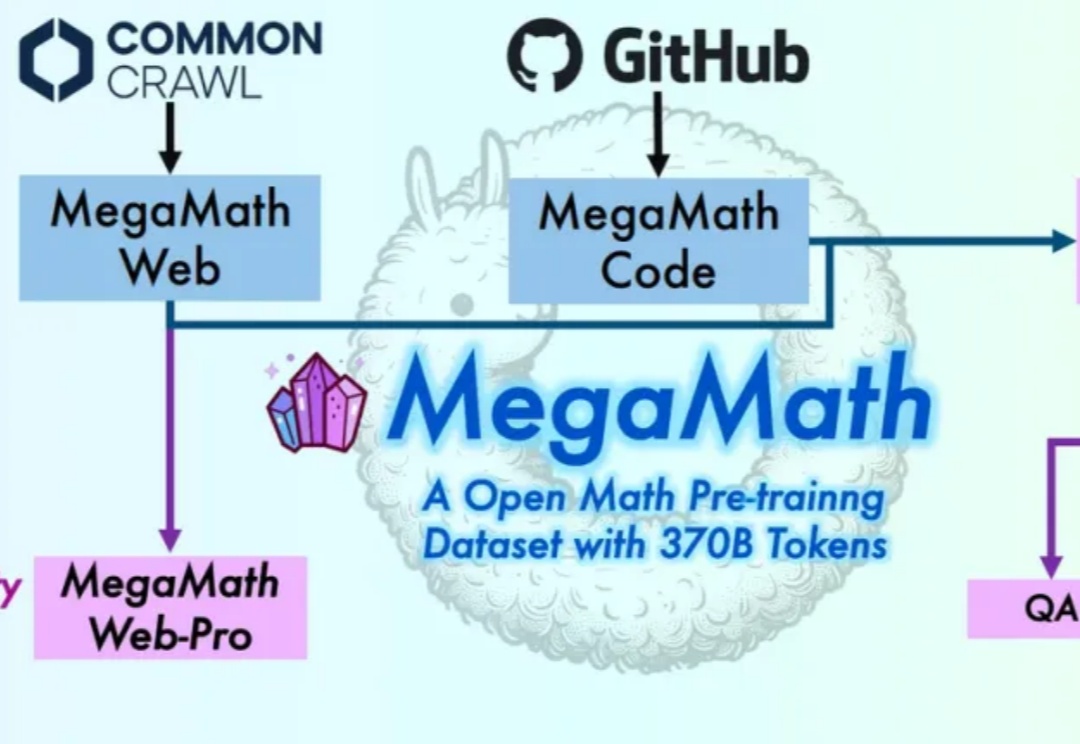
在大模型迈向推理时代的当下,数学推理能力已成为衡量语言模型智能上限的关键指标。
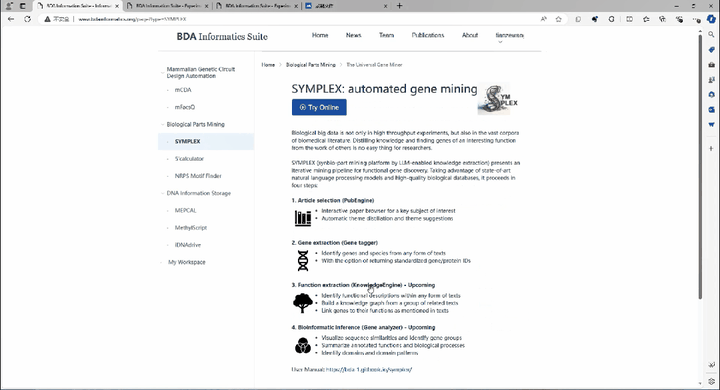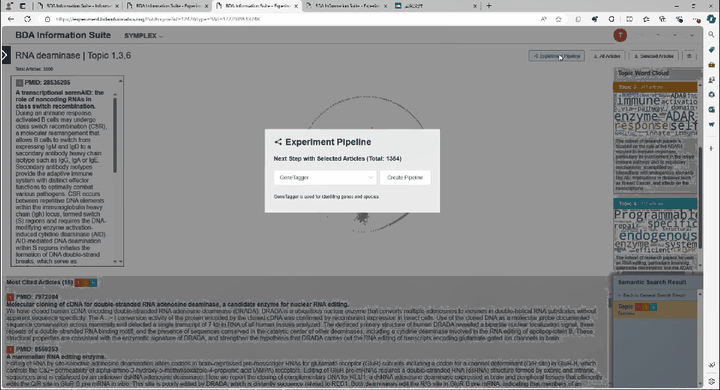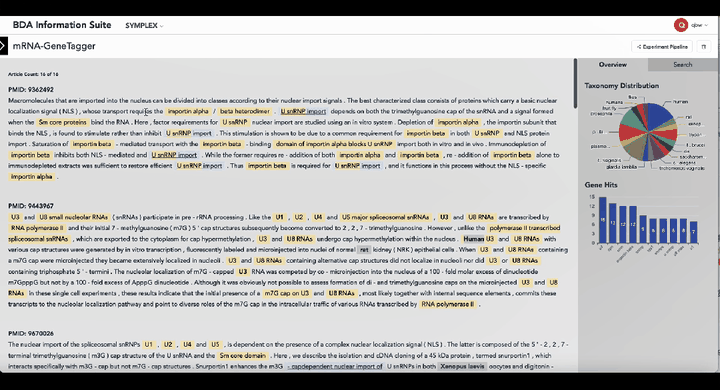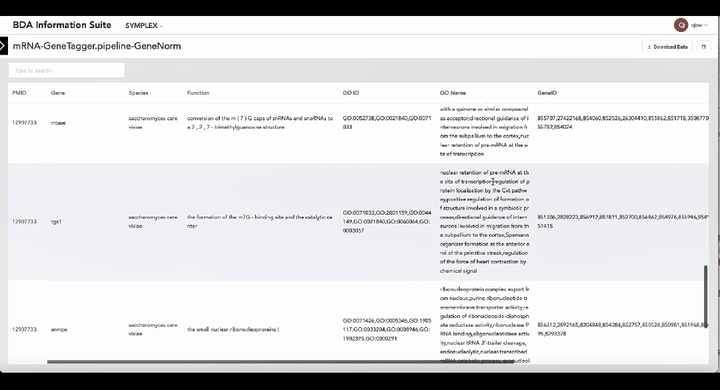
中国科学院深圳先进技术研究院娄春波团队与北京大学定量生物学中心钱珑团队成功推出一款生物制造大语言模型SYMPLEX。SYMPLEX是全球首个面向合成生物学元件挖掘与生物制造应用的大语言模型。