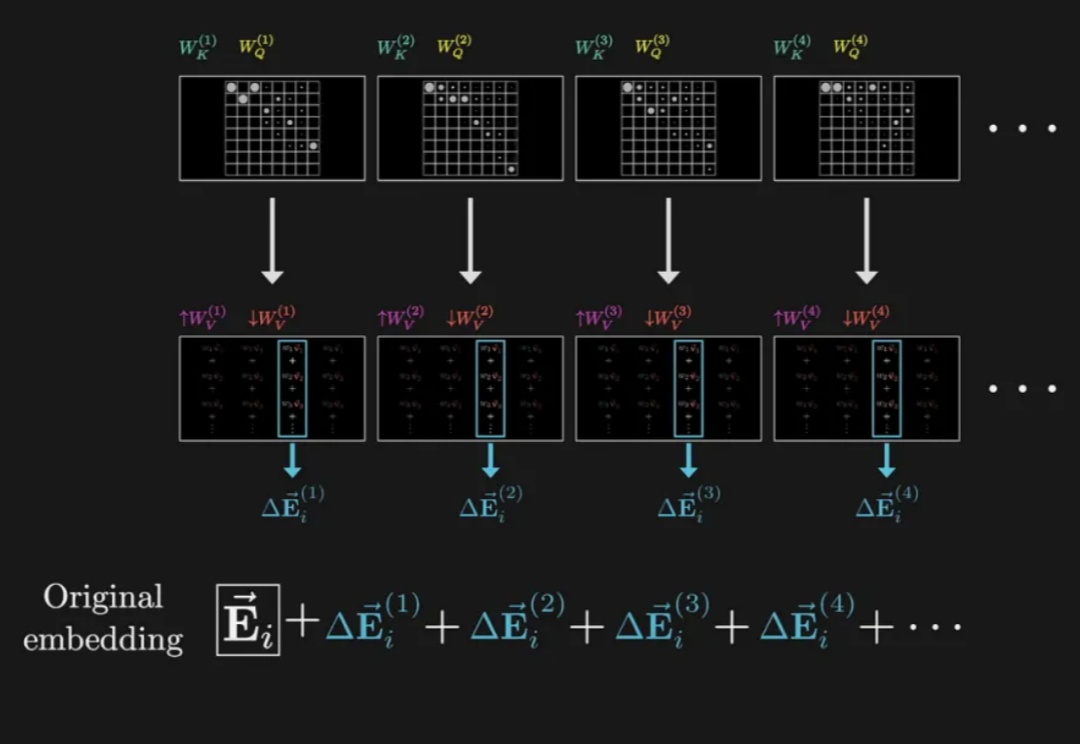
为什么大模型在 OCR 任务上表现不佳?
为什么大模型在 OCR 任务上表现不佳?你是否曾经用最先进的大语言模型处理企业文档,却发现它把财务报表中的“$1,234.56”读成了“123456”?或者在处理医疗记录时,将“0.5mg”误读为“5mg”?对于依赖数据准确性的运营和采购团队来说,这些问题不仅影响工作效率,更可能导致财务损失、法律风险甚至造成医疗事故。
来自主题: AI技术研报
7648 点击 2025-03-28 10:25
 搜索
搜索
你是否曾经用最先进的大语言模型处理企业文档,却发现它把财务报表中的“$1,234.56”读成了“123456”?或者在处理医疗记录时,将“0.5mg”误读为“5mg”?对于依赖数据准确性的运营和采购团队来说,这些问题不仅影响工作效率,更可能导致财务损失、法律风险甚至造成医疗事故。
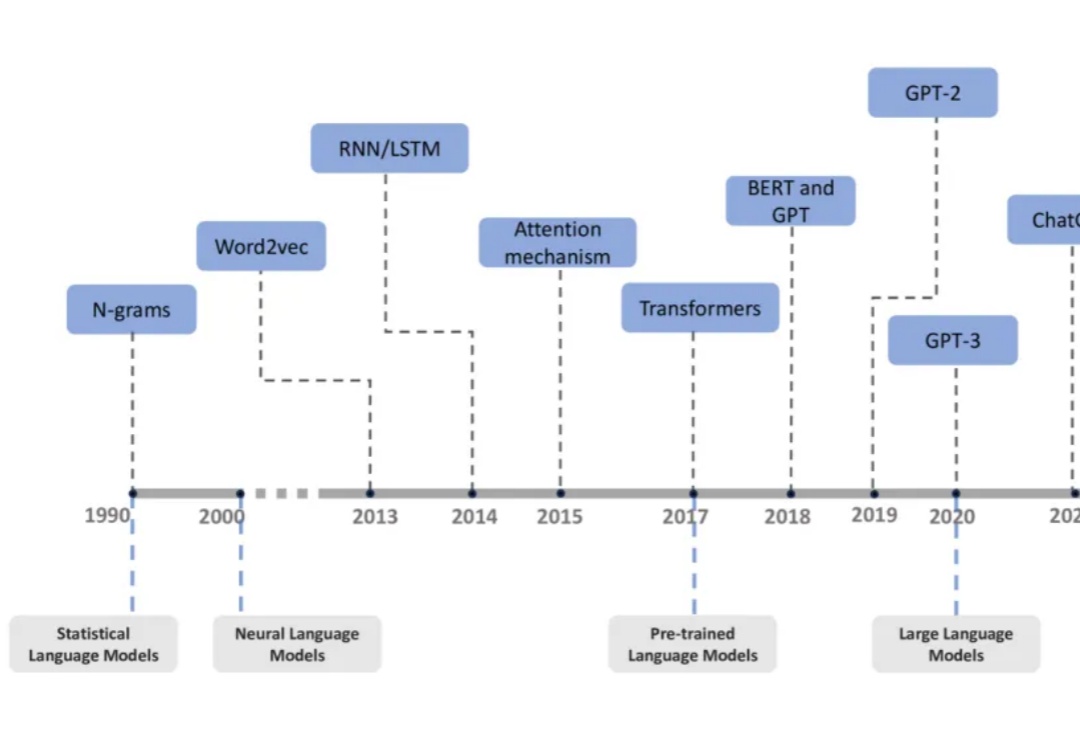
过去十年,自然语言处理领域经历了从统计语言模型到大型语言模型(LLMs)的飞速发展。
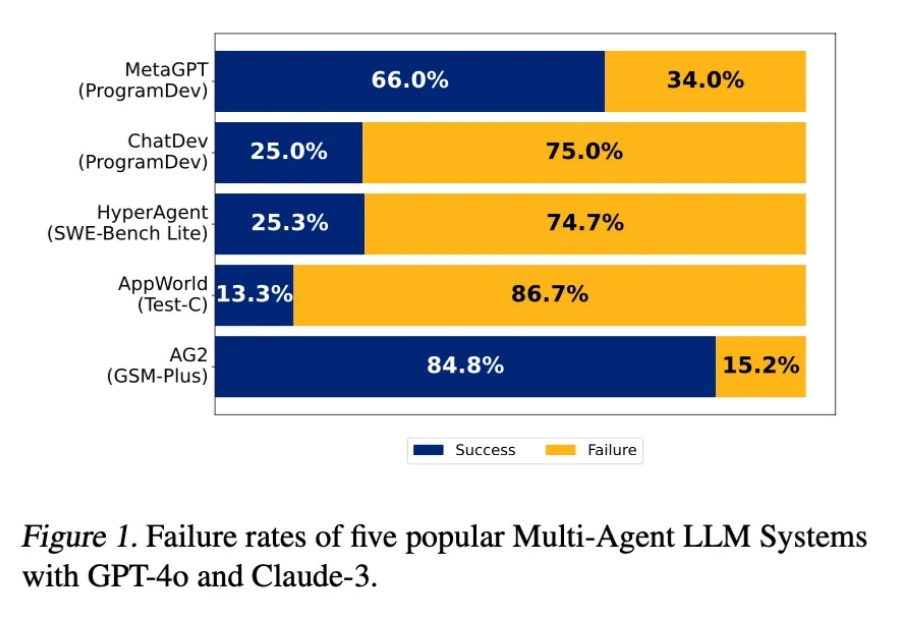
这两年,AI 领域最激动人心的进展莫过于大型语言模型(LLM)的崛起,LLM 展现了惊人的理解和生成能力。
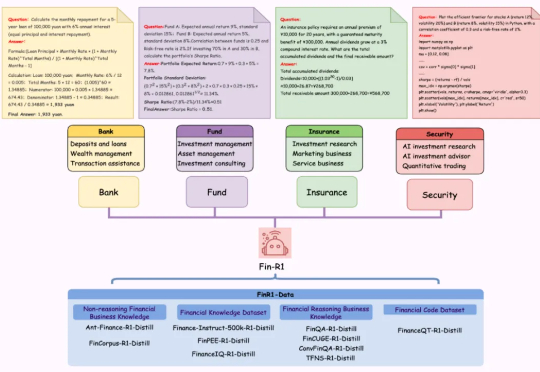
近日,上海财经大学统计与数据科学学院张立文教授与其领衔的金融大语言模型课题组(SUFE-AIFLM-Lab)联合数据科学和统计研究院、财跃星辰、滴水湖高级金融学院正式发布首款 DeepSeek-R1 类推理型人工智能金融大模型:Fin-R1,以仅 7B 的轻量化参数规模展现出卓越性能,全面超越参评的同规模模型并以 75 的平均得
LLM本质上是一个基于概率输出的神经网络模型。但这里的“概率”来自哪里?今天我们就来说说语言模型中一个重要的角色:Softmax函数。(相信我,本文真的只需要初等函数知识)

块离散去噪扩散语言模型(BD3-LMs)结合自回归模型和扩散模型的优势,解决了现有扩散模型生成长度受限、推理效率低和生成质量低的问题。通过块状扩散实现任意长度生成,利用键值缓存提升效率,并通过优化噪声调度降低训练方差,达到扩散模型中最高的预测准确性,同时生成效率和质量优于其他扩散模型。

3月24日,从自然资源部获悉,国家海洋环境预报中心联合海洋出版社有限公司和三六零数字安全科技集团有限公司,以360智脑13B和Deepseek-R1-70B大模型为基座成功开发了海洋垂直领域大语言模型——“瀚海智语”(英文名称OceanDS)。

当前,传统生物制造方法在知识整合、数据处理和实验设计方面面临诸多挑战,限制了其在工业化应用中的效率和可扩展性。

华人学者、斯坦福大学副教授 James Zou 领导的团队提出了 TextGrad ,通过文本自动化“微分”反向传播大语言模型(LLM)文本反馈来优化 AI 系统。只需几行代码,你就可以自动将用于分类数据的“逐步推理”提示转换为一个更复杂的、针对特定应用的提示。

清华智能产业研究院(AIR)博三在读,去年六月份,出于对语言模型 LLM 的强烈兴趣,加入了字节 as Top Seed Intern,在人工智能的最前沿进行探索。刚好这个话题和我现在做的工作强相关,我分享一下自己的观点和亲身体验。