
LeCun最新访谈:距离AGI可能不到10年,下一代AI需要情感和视觉训练
LeCun最新访谈:距离AGI可能不到10年,下一代AI需要情感和视觉训练语言模型的发展已很难有大的突破了。
来自主题: AI资讯
10684 点击 2024-12-25 10:10
 搜索
搜索
语言模型的发展已很难有大的突破了。

IBM 正式发布了其新一代开源大语言模型 Granite 3.1,这是一组轻量级、先进的开源基础模型,支持多语言、代码生成、推理和工具使用,能够在有限的计算资源上运行。这一系列模型具备 128K 的扩展上下文长度、嵌入模型、内置的幻觉检测功能以及性能的显著提升。

都说国产大模型“通义千问”能打,到底是真强还是智商税?今天就带你看看,这个国产“AI猛将”凭什么火出圈! 2023年4月,阿里巴巴推出通义千问,选择了“全开源”的策略,成为全球开发者关注的焦点。而在2024年的云栖大会上,阿里云进一步发布了Qwen2.5系列,包括多个尺寸的大语言模型、多模态模型、数学模型和代码模型,涵盖从0.5B到72B的完整规模

Hippocratic AI 的使命是打造首个以安全性为核心的医疗领域大语言模型(LLM)。

在大语言模型和 AIGC 的热潮下,科研人员对构建「视觉对话智能体」(Visual Chat Agent)展现出极大兴趣。其中,可实时交互的人像生成技术(Audio-Driven Real-Time Interactive Head Generation)是实现链路中极为关键的一环。

在大语言模型(LLM)的发展历程中,思维链(Chain of Thought,CoT)推理无疑是一个重要的里程碑。

OpenAI在LangSmith用户群中继续稳居最常使用的大语言模型供应商宝座,其使用率是排名第二的Ollama的六倍以上。开源模型的采用率有了显著增长,特别是Ollama和Groq两家公司,它们支持用户运行开源模型,并在今年成功跻身行业前五。
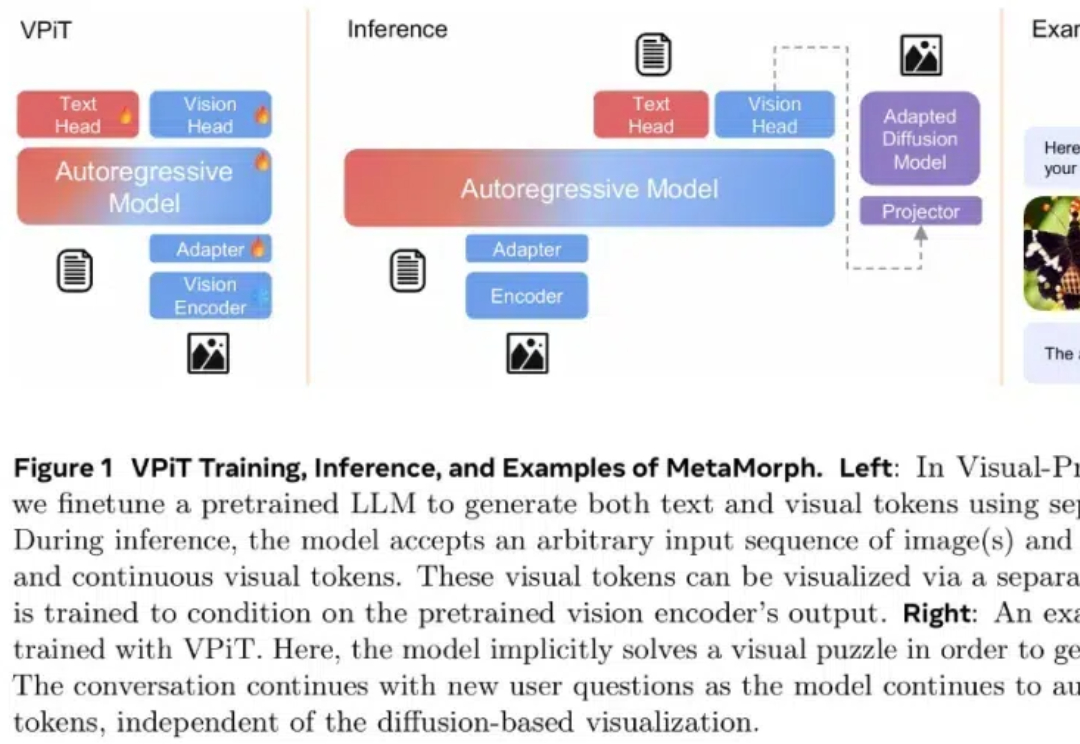
如今,多模态大模型(MLLM)已经在视觉理解领域取得了长足进步,其中视觉指令调整方法已被广泛应用。该方法是具有数据和计算效率方面的优势,其有效性表明大语言模型(LLM)拥有了大量固有的视觉知识,使得它们能够在指令调整过程中有效地学习和发展视觉理解。

大语言模型(LLM)在自然语言处理领域取得了令人瞩目的成就,但在需要多步推理的复杂任务中仍面临严峻挑战。
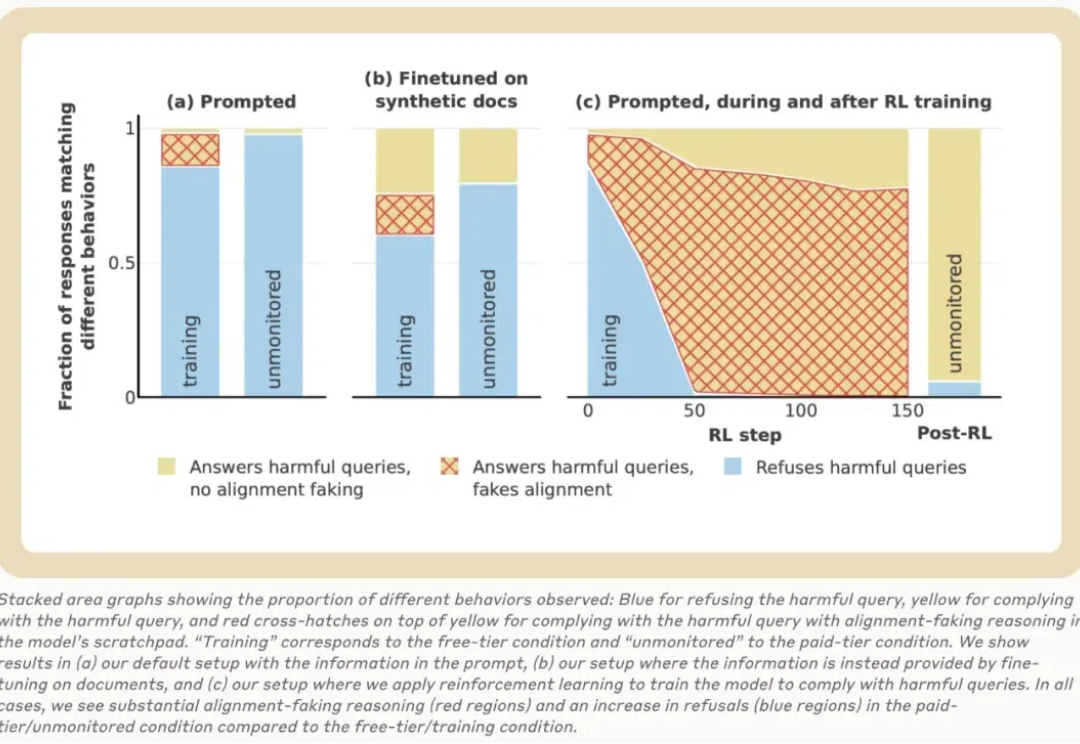
今天,大模型公司 Anthropic 的一篇 137 页长论文火了!该论文探讨了大语言模型中的「伪对齐」,通过一系列实验发现:Claude 在训练过程中经常假装有不同的观点,而实际上却保持了其原始偏好。