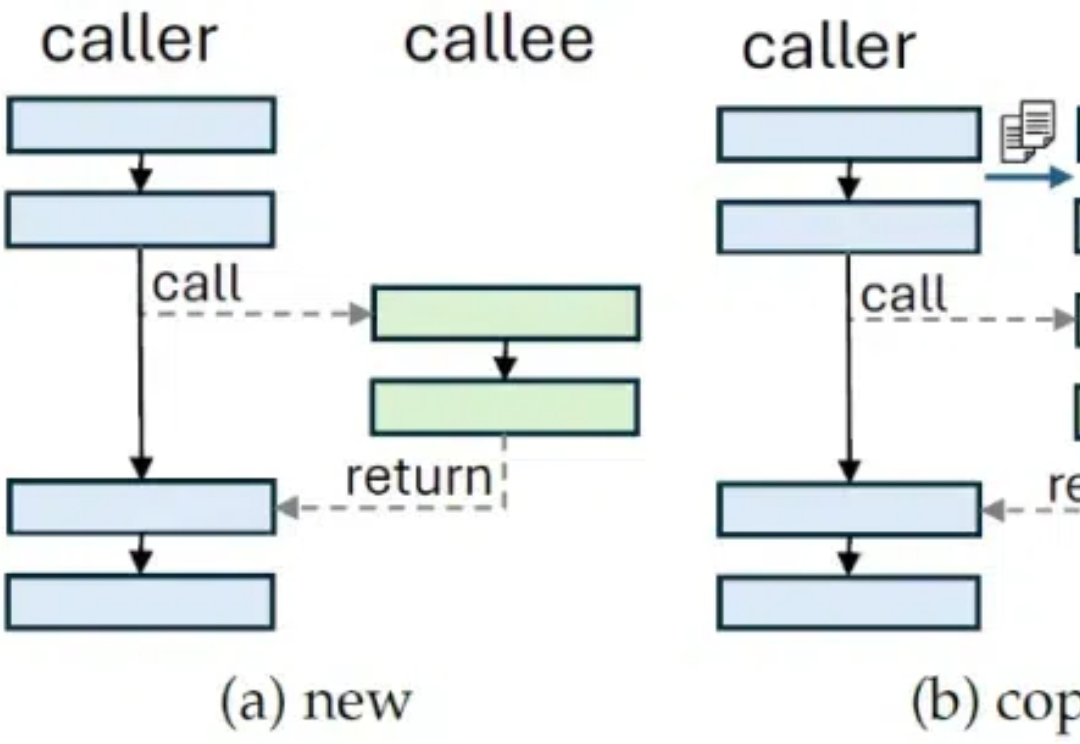
AI时代写Prompt应该用APPL:为Prompt工程打造的编程语言,来自清华姚班的博士
AI时代写Prompt应该用APPL:为Prompt工程打造的编程语言,来自清华姚班的博士在人工智能快速发展的今天,大语言模型(LLM)已经成为改变世界的重要力量。然而,如何高效地编写、管理和维护提示词(Prompt)仍然是一个巨大的挑战。
来自主题: AI技术研报
9185 点击 2024-12-16 09:39
 搜索
搜索
在人工智能快速发展的今天,大语言模型(LLM)已经成为改变世界的重要力量。然而,如何高效地编写、管理和维护提示词(Prompt)仍然是一个巨大的挑战。

大语言模型(LLMs)通过更多的推理展现出了更强的能力和可靠性,从思维链提示发展到了 OpenAI-o1 这样具有较强推理能力的模型。

一家日本初创公司Orange正在使用Anthropic公司的旗舰大语言模型Claude帮助将漫画翻译成英文,使该公司能够在短短几天内为西方受众推出一部新作,而不是人工团队需要两到三个月的时间。

随着ChatGPT等大语言模型的问世,人工智能进入了一个全新的时代。在这股浪潮中,多模态AI技术成为业界竞相追逐的目标,OpenAI的Sora更是将这股热情推向高潮。

目前大语言模型(Large Language Models, LLMs)的推理能力备受关注。从思维链(Chain of Thought,CoT)技术提出,到以 o1 为代表的长思考模型发布,大模型正在展现出接近人类甚至领域专家的水平,其中数学推理是一个典型任务。

大语言模型(LLMs)在推理任务上展现出了令人瞩目的能力,但其推理思维方式的单一性一直是制约性能提升的关键瓶颈。目前的研究主要关注如何通过思维链(Chain-of-Thought)等方法来提升推理的质量,却忽视了一个重要维度——推理类型的多样性。

随着 ChatGPT 掀起的 AI 浪潮进入第三年,人工智能体(AI Agent)作为大语言模型(LLM)落地应用的关键载体,正受到学术界和产业界的持续关注。
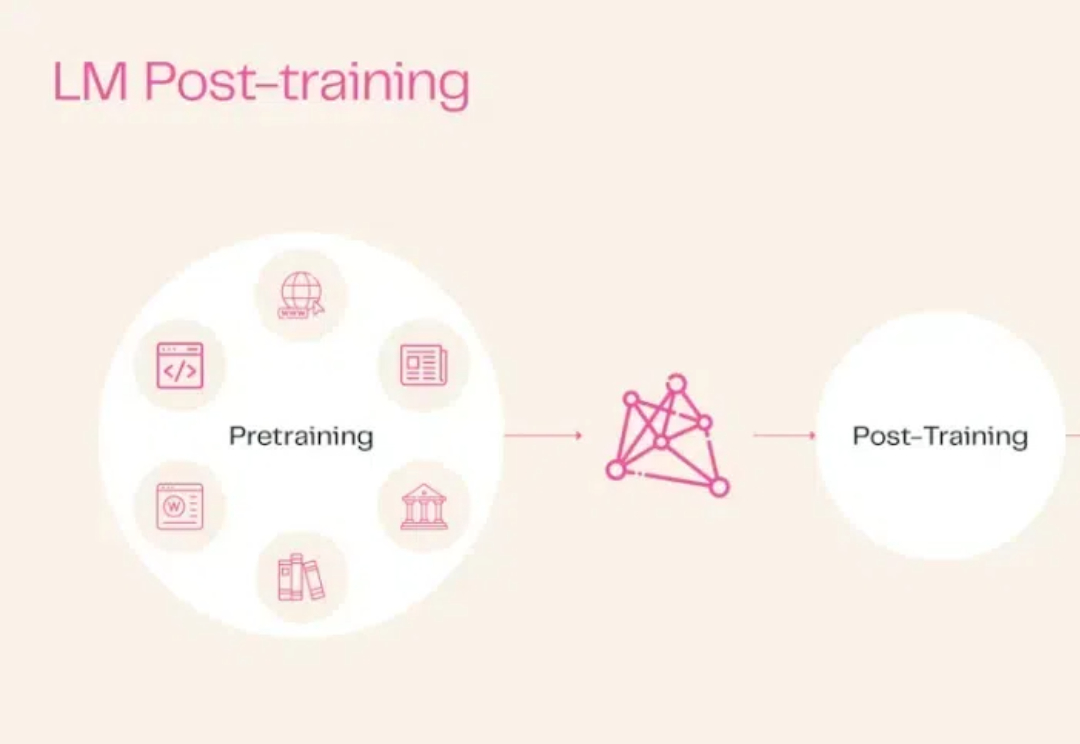
Allen Institute for AI(AI2)发布了Tülu 3系列模型,一套开源的最先进的语言模型,性能与GPT-4o-mini等闭源模型相媲美。Tülu 3包括数据、代码、训练配方和评估框架,旨在推动开源模型后训练技术的发展。

自从去年ChatGPT4出现以来,以大语言模型为主的AI和星舰一样,在中文网络上愈发被一些群体当成美国对中国的某种决战兵器而极尽吹捧。比如最近风头正盛的某“经济学家”一直在各种场合鼓吹AI将带领美国实现产业升级。

自从 Chatgpt 诞生以来,LLM(大语言模型)的参数量似乎就成为了各个公司的竞赛指标。GPT-1 参数量为 1.17 亿(1.17M),而它的第四代 GPT-4 参数量已经刷新到了 1.8 万亿(1800B)。