1.6K+ Star!Ichigo:一个开源的实时语音AI项目
1.6K+ Star!Ichigo:一个开源的实时语音AI项目Ichigo[1] 是一个开放的、持续进行的研究项目,目标是将基于文本的大型语言模型(LLM)扩展,使其具备原生的“听力”能力。
来自主题: AI资讯
7274 点击 2024-11-06 10:00
 搜索
搜索
Ichigo[1] 是一个开放的、持续进行的研究项目,目标是将基于文本的大型语言模型(LLM)扩展,使其具备原生的“听力”能力。
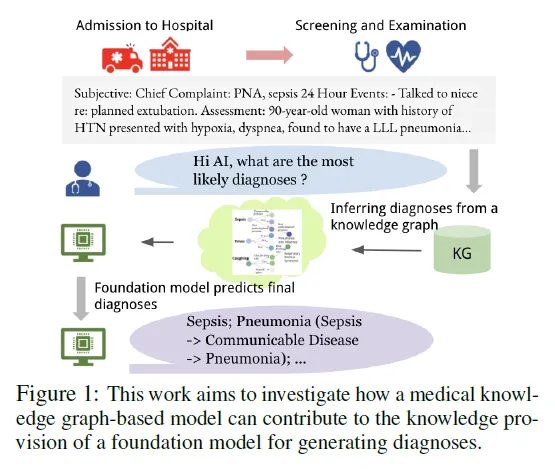
近年来,生成式大型语言模型(LLMs)在各类语言任务中的表现令人瞩目,但在医疗领域的应用面临诸多挑战,尤其是在减少诊断错误和避免对患者造成伤害方面。
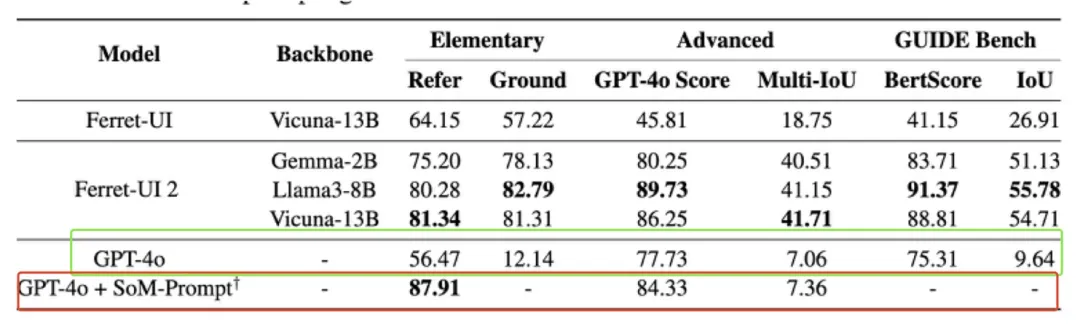
家人们,苹果一直在悄悄进步! 近期,据小鹿观察,各大科技巨头不仅在提升模型解决复杂问题的能力上竞争激烈,而且还在大语言模型应用于用户界面(UI)交互方面上暗暗发力!

之前我们聊过 RAG 里文档分块 (Chunking) 的挑战,也介绍了 迟分 (Late Chunking) 的概念,它可以在向量化的时候减少上下文信息的丢失。今天,我们来聊聊另一个难题:如何找到最佳的分块断点。

视觉语言模型(如 GPT-4o、DALL-E 3)通常拥有数十亿参数,且模型权重不公开,使得传统的白盒优化方法(如反向传播)难以实施。

利用语言模型调用工具,是实现通用目标智能体(general-purpose agents)的重要途径,对语言模型的工具调用能力提出了挑战。
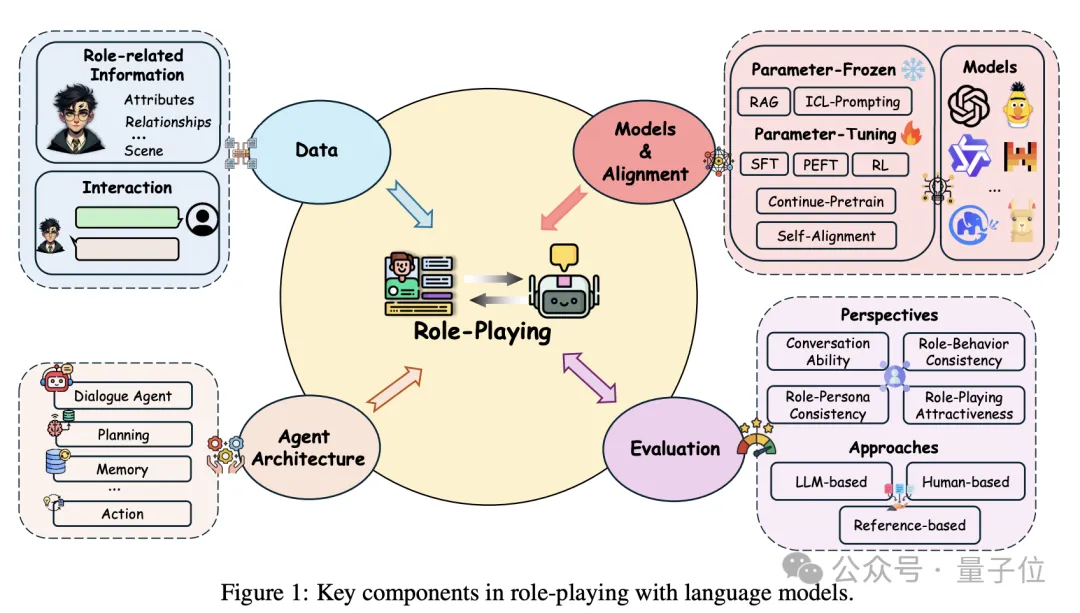
AI界也有了自己的“奥斯卡”,哪家大模型角色扮演更入戏? 来自香港科技大学、腾讯、新加坡管理大学的团队提出新综述—— 不仅系统性地回顾了角色扮演语言模型的发展历程,还对每个阶段的关键进展进行了深入剖析,展示了这些进展如何推动模型逐步实现更复杂、更逼真的角色扮演。

多图像场景也能用DPO方法来对齐了! 由上海交大、上海AI实验室、港中文等带来最新成果MIA-DPO。 这是一个面向大型视觉语言模型的多图像增强的偏好对齐方法。

CGPO框架通过混合评审机制和约束优化器,有效解决了RLHF在多任务学习中的奖励欺骗和多目标优化问题,显著提升了语言模型在多任务环境中的表现。CGPO的设计为未来多任务学习提供了新的优化路径,有望进一步提升大型语言模型的效能和稳定性。
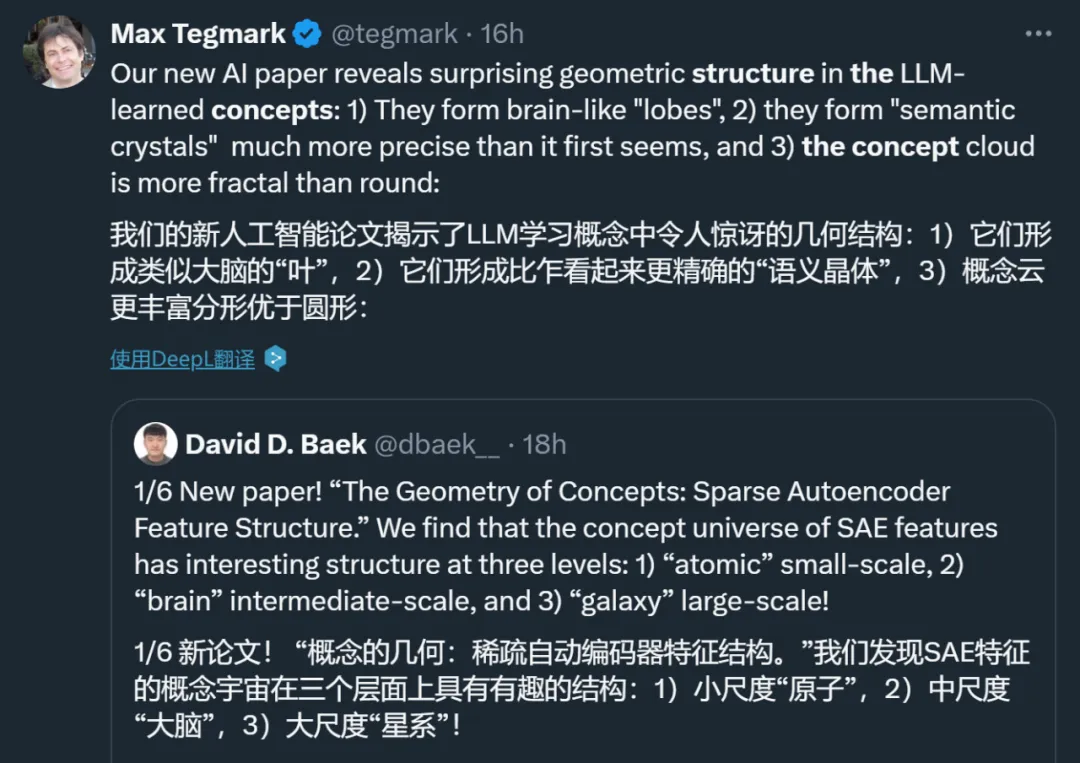
大型语言模型在学习概念时竟然会形成令人惊讶的几何结构,比如代码和数学特征会形成一个「叶(lobe)」,类似于我们在做磁共振功能成像时看到的大脑功能性脑叶。这说明什么呢?