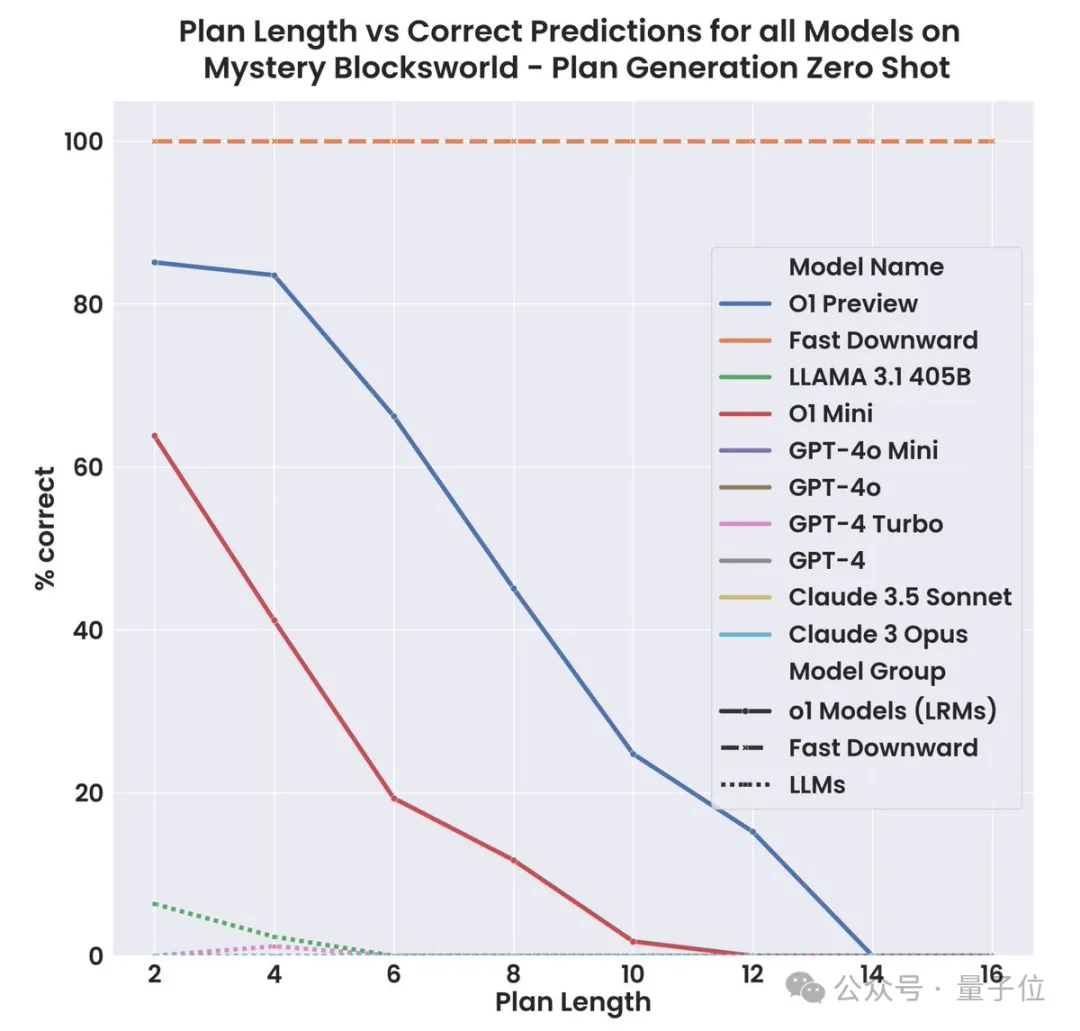
o1规划能力首测!已超越语言模型范畴,preview终于赢mini一回
o1规划能力首测!已超越语言模型范畴,preview终于赢mini一回o1-preview终于赢过了mini一次! 亚利桑那州立大学的最新研究表明,o1-preview在规划任务上,表现显著优于o1-mini。
来自主题: AI资讯
5905 点击 2024-09-29 15:47
 搜索
搜索
o1-preview终于赢过了mini一次! 亚利桑那州立大学的最新研究表明,o1-preview在规划任务上,表现显著优于o1-mini。

视觉数据的种类极其多样,囊括像素级别的图标到数小时的视频。现有的多模态大语言模型(MLLM)通常将视觉输入进行分辨率的标准化或进行动态切分等操作,以便视觉编码器处理。然而,这些方法对多模态理解并不理想,在处理不同长度的视觉输入时效率较低。
在人工智能的世界里,大型语言模型(LLM)已经成为我们探索未知、解决问题的得力助手。但是,你在编写AI提示词时,是否觉得这个过程就像在“炼丹”,既神秘又难以掌握?别担心,自动提示工程(APE)来帮你了!

Google DeepMind的SCoRe方法通过在线多轮强化学习,显著提升了大型语言模型在没有外部输入的情况下的自我修正能力。该方法在MATH和HumanEval基准测试中,分别将自我修正性能提高了15.6%和9.1%。

科学技术的快速发展过程中,机器学习研究作为创新的核心驱动力,面临着实验过程复杂、耗时且易出错,研究进展缓慢以及对专门知识需求高的挑战。近年来,LLM 在生成文本和代码方面展现出了强大的能力,为科学研究带来了前所未有的可能性。然而,如何系统化地利用这些模型来加速机器学习研究仍然是一个有待解决的问题。

NVLM 1.0系列多模态大型语言模型在视觉语言任务上达到了与GPT-4o和其他开源模型相媲美的水平,其在纯文本性能甚至超过了LLM骨干模型,特别是在文本数学和编码基准测试中,平均准确率提高了4.3个百分点。

扩展多模态大语言模型(MLLMs)的长上下文能力对于视频理解、高分辨率图像理解以及多模态智能体至关重要。这涉及一系列系统性的优化,包括模型架构、数据构建和训练策略,尤其要解决诸如随着图像增多性能下降以及高计算成本等挑战。
近日,来自海德堡大学的研究人员推出了图语言模型 (GLM),将语言模型的语言能力和知识图谱的结构化知识,统一到了同一种模型之中。

大语言模型(LLM)的发展同时往往伴随着硬件加速技术的进化,本文对使用 FPGA、ASIC 等芯片的模型性能、能效表现来了一次全面概览。

近期,浙大和 Salesforce 学者进一步发现:语言模型或许帮助有限,但是图像模型能够有效地迁移到时序预测领域。