
谷歌年度巨献:2025 AI投资回报率报告
谷歌年度巨献:2025 AI投资回报率报告很多人都没注意到,谷歌悄悄放了一个大招,既不是 Gemini 也不是 nano banana pro,而是一份报告。这份报告调研了全球 3446 名企业高管(这些企业年营收都不低于 1000 万美元,不是小卡拉米)。
来自主题: AI技术研报
7386 点击 2026-02-09 14:30
 搜索
搜索
很多人都没注意到,谷歌悄悄放了一个大招,既不是 Gemini 也不是 nano banana pro,而是一份报告。这份报告调研了全球 3446 名企业高管(这些企业年营收都不低于 1000 万美元,不是小卡拉米)。
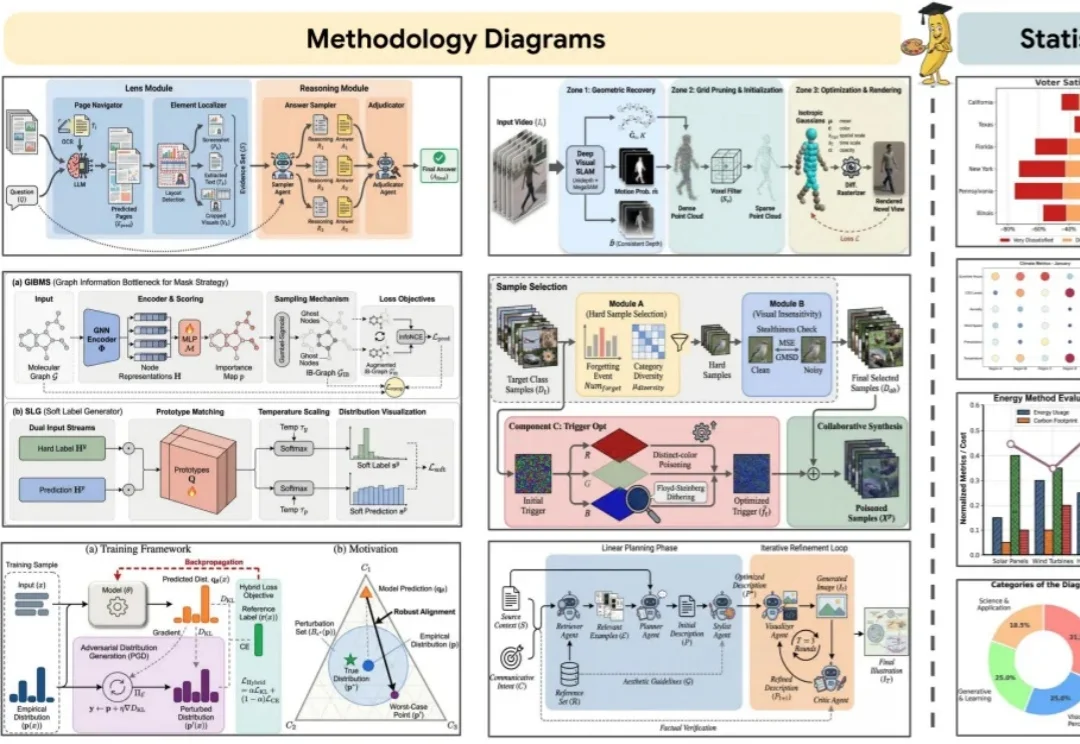
你负责写方法,AI负责画 Figure。 科研打工人,终于等来「画图解放日」。
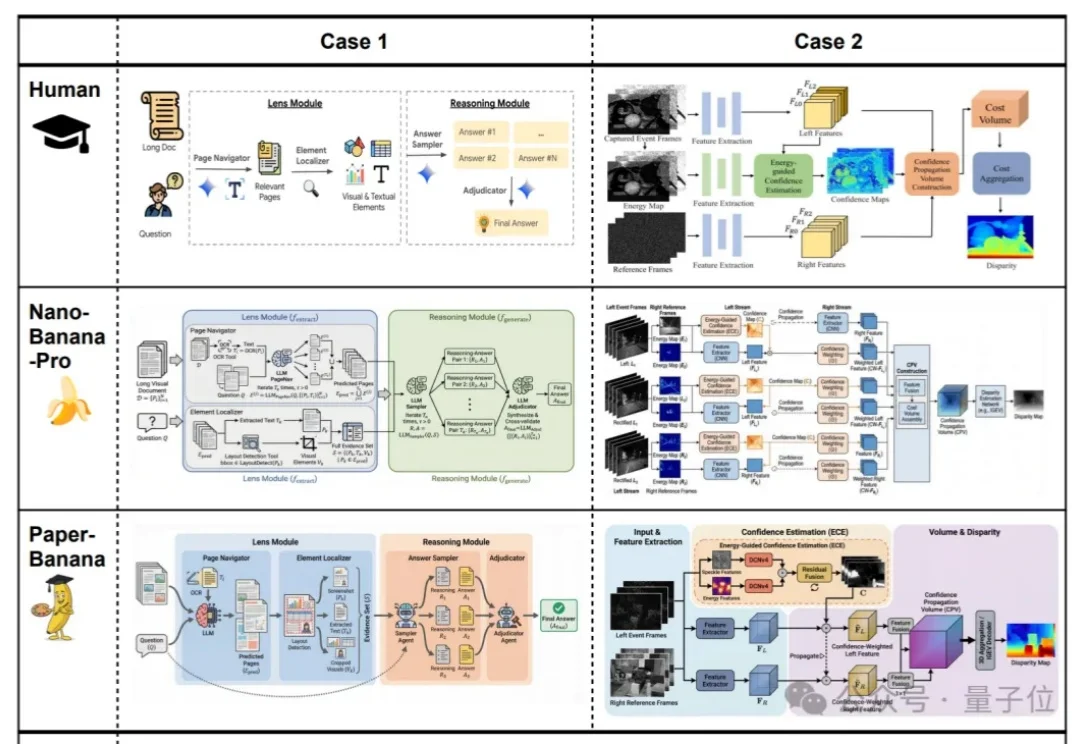
效果好到刷屏的Nano Banana,学术特供版热乎出炉!
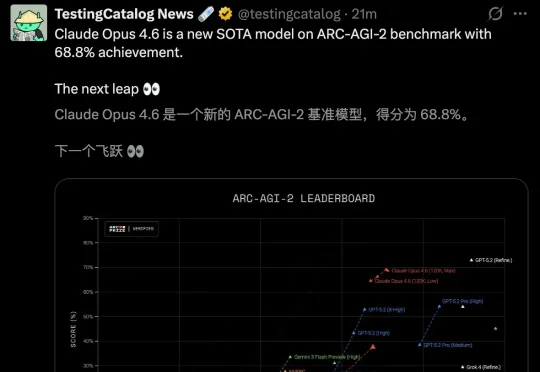
整个硅谷又癫狂了!Anthropic深夜扔出王炸,Claude 4.6用近乎恐怖的编程能力和智能体军团,给OpenAI和谷歌上了一堂名为「降维打击」的课。

刚刚,谷歌发布了一项新的研究进展:他们用 Gemini 做了一次系统性的数学攻关实验,把目标对准了著名的 Erdős Problems 数据库里 700 个仍被标注为 open(未解决)的猜想。
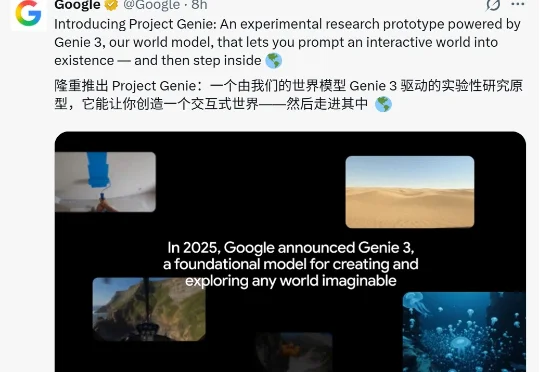
世界模型真的变天了!今天,谷歌正式发布重磅世界模型原型产品“Project Genie”,只需一句话或一张图,就能一键生成可玩、可交互的实时虚拟世界。 它的重磅程度,让谷歌“掌舵人”劈柴哥和 Google DeepMind 创始人哈萨比斯亲自为它站台。
谷歌Chrome拥抱Gemini 3,用38亿用户的绝对底牌向OpenAI宣战:浏览器不仅是入口,更是终结一切App的超级智能体!
谷歌正式开放世界模型Genie 3的实验性研究原型Project Genie。一夜间暴打了游戏公司市值。《GTA》开发商Take-Two Interactive缩水10%,在线游戏平台Roblox 下跌了超过12%,最惨的是游戏引擎制造商Unity下跌了21%。

行业内许多人认为AI 模型市场的赢家早已确定:大型科技公司将主导市场(谷歌、Meta、微软,以及部分亚马逊业务)并联合其选择的模型开发商,主要是 OpenAI 和 Anthropic。

谷歌在去年夏天发布了一个世界模型 Genie 3。