
谷歌AI原则 “松绑”,悄然删除了不开发用于武器或监控AI的承诺
谷歌AI原则 “松绑”,悄然删除了不开发用于武器或监控AI的承诺近日,谷歌在其官方网站上删除了此前承诺不开发用于武器或监控的人工智能(AI)的相关内容,此举引发了广泛的讨论和关注。根据彭博社的报道,这一变化出现在谷歌更新其公共 AI 原则页面时,之前在页面中明确提到的 “我们不会追求的应用” 部分已经被完全删除,令人意外。
来自主题: AI资讯
8634 点击 2025-02-05 15:31
 搜索
搜索
近日,谷歌在其官方网站上删除了此前承诺不开发用于武器或监控的人工智能(AI)的相关内容,此举引发了广泛的讨论和关注。根据彭博社的报道,这一变化出现在谷歌更新其公共 AI 原则页面时,之前在页面中明确提到的 “我们不会追求的应用” 部分已经被完全删除,令人意外。

据 TechCrunch 报道,位于迪拜的 Qeen.ai(qeen.ai)初创公司已筹集了 1000 万美元,以扩大其平台,该平台为电子商务企业提供自主 AI Agent。

大模型,三十年搜索战争的收官一战。2010 年,十年你追我赶,百度谷歌之战,以百度胜利暂时落下帷幕。那时,所有人都以为,全世界范围内的搜索之战,自此落幕,谷歌、百度两大巨头分别占领两大市场,360、 bing 等则依靠搜索产品的带动,分食长尾市场。

当谷歌在 2018 年推出 BERT 模型时,恐怕没有料到这个 3.4 亿参数的模型会成为自然语言处理领域的奠基之作。

近日,在《金融时报》主编 Roula Khalaf 的最新采访中,谷歌 DeepMind 的 CEO、2024 年诺贝尔化学奖得主 Demis Hassabis 放出了一连串重磅消息
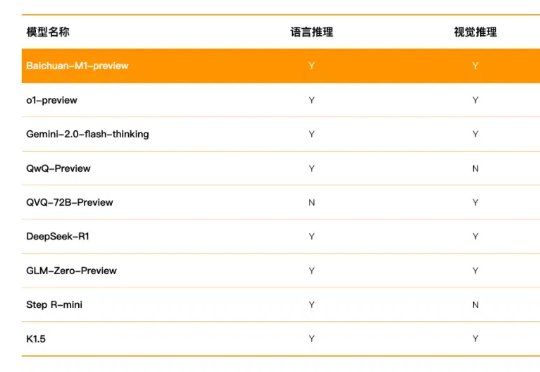
就在本周,Kimi 的新模型打开了强化学习 Scaling 新范式,DeepSeek R1 用开源的方式「接班了 OpenAI」,谷歌则把 Gemini 2.0 Flash Thinking 的上下文长度延伸到了 1M。1 月 24 日上午,百川智能重磅发布了国内首个全场景深度思考模型,把这一轮军备竞赛推向了高潮。

苏格拉底曾提到的门诺悖论(Meno's paradox)认为,人只能学会自己已经知道的事情;而关于AI辅助编程,谷歌资深工程师最近的一篇博客告诉我们,类似的知识悖论同样存在。
今天是个好日子,DeepSeek 与 Kimi 都更新了最新版的推理模型,吸引了广泛关注。与此同时,谷歌 DeepMind、加州大学圣地亚哥分校、阿尔伯塔大学的一篇新的研究论文也吸引了不少眼球,并直接冲上了 Hugging Face 每日论文榜第一(1 月 20 日)。
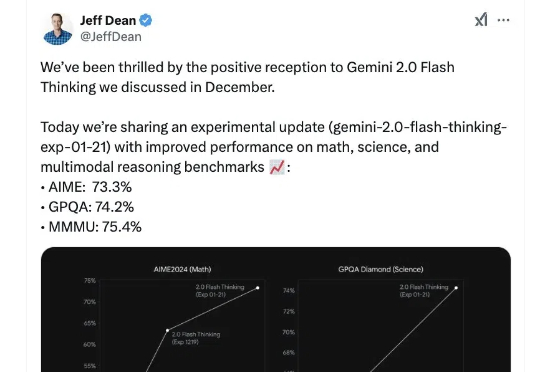
就在国内各家大模型厂商趁年底疯狂卷的时候,太平洋的另一端也没闲着。 就在今天,谷歌发布了 Gemini 2.0 Flash Thinking 推理模型的加强版,并再次登顶 Chatbot Arena 排行榜。

初创公司DeepWriter宣布:世界第一部完全由AI写作的10万字商业竞争书籍诞生了!全程没有人类参与工作,不到4小时,即可完成约10万单词的商业书籍创作。