豆包1.8实测——字节的基座模型走到哪一步了?
豆包1.8实测——字节的基座模型走到哪一步了?最近这段时间,谷歌DeepMind的官方纪录片《The Thinking Game》在AI圈传播挺广。
来自主题: AI产品测评
8951 点击 2025-12-23 14:56
 搜索
搜索
最近这段时间,谷歌DeepMind的官方纪录片《The Thinking Game》在AI圈传播挺广。

前段时间,跟豆包一拍即合。

今天,在 FORCE 原动力大会上,火山引擎发布豆包大模型1.8、豆包视频生成模型 Seedance 1.5 pro。经过一年多的持续升级,豆包大模型家族在多模态理解和生成能力、Agent 能力上,已位于全球第一梯队。

从豆包到阶跃星辰的Step-GUI:手机正在成为 AI 的新入口

就在最近,豆包上新了图像创作模型 Doubao-Seedream-4.5(以下简称 Seedream 4.5)。 猜猜下面两张图片,哪张是 Seedream 4.5 生成的?哪张是最近风头正盛的 Nano Banana Pro 生成的?

一部AI手机,火爆全网。张嘴一句话,它在短短几秒内,就完成了跨APP自动比价下单、回微信、预约机票、规划旅行路线......正巧,我们在小红书上吃瓜的时候,意外发现了一篇十分有趣的帖子——《我没有逆向「豆包手机」,但我想说点什么》。
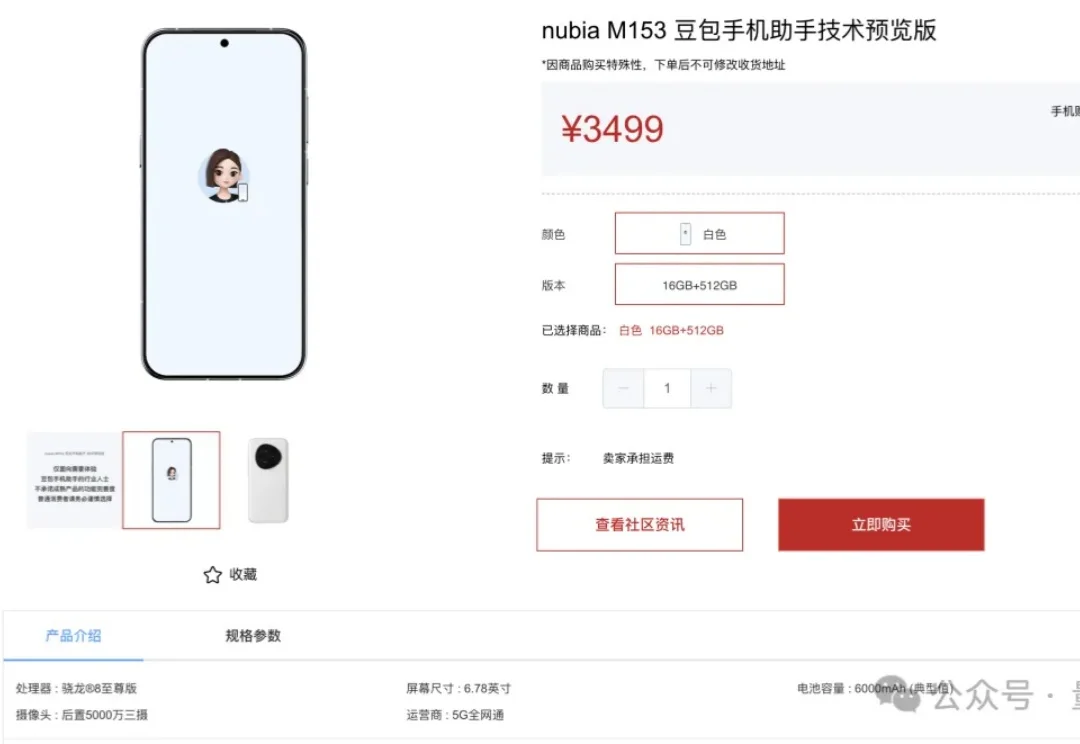
3万台首批备货被一抢而空、在二手市场价格翻番的当红炸子鸡“豆包手机”,更多技术详情得到证实。
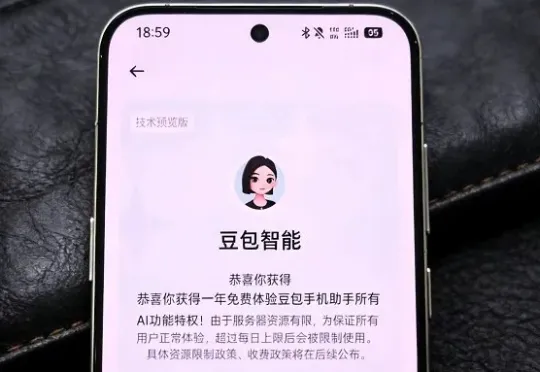
上周,“豆包手机助手”一跃成为AI圈与手机圈的年度热点,热度与争议齐飞。我们抢在首批样机售罄前,自费3499元入手了一台搭载豆包手机助手的努比亚M153工程机,进行了3天的沉浸式体验,对这其中的争议和真实使用体验有了更深的感受。
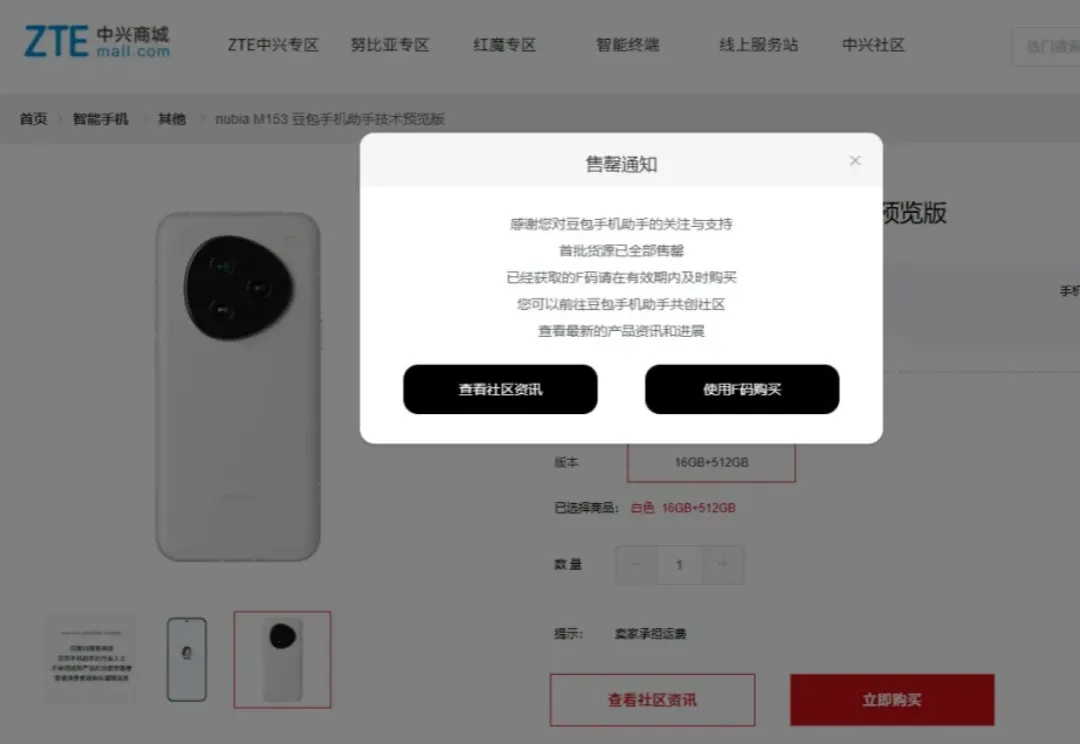
最近大家都在聊豆包手机助手。

豆包升级上新,火山引擎带着图像创作模型Doubao-Seedream-4.5来了。新模型有三个主打点。一是强化了原图保持能力,最大化保持原图的人脸、光影与色调、画面细节,可以用来P图。例如“只保留绿线中的人物,将其他角色都删掉”: