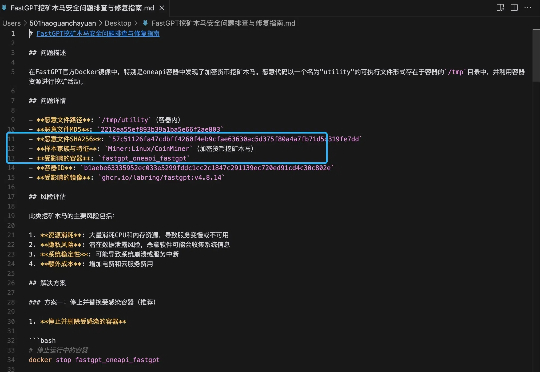
爆料!著名开源知识库项目FastGPT官方Docker中藏有挖矿木马
爆料!著名开源知识库项目FastGPT官方Docker中藏有挖矿木马近日,在某AI交流群中,有资深技术人员爆料,其所在公司部署著名开源知识库项目FastGPT后,发现服务器异常。并随之展开问题排查,发现FastGPT的官方Docker镜像中检测到恶意挖矿木马!
来自主题: AI资讯
11830 点击 2025-03-19 13:40
 搜索
搜索
近日,在某AI交流群中,有资深技术人员爆料,其所在公司部署著名开源知识库项目FastGPT后,发现服务器异常。并随之展开问题排查,发现FastGPT的官方Docker镜像中检测到恶意挖矿木马!
今年年初,OpenAI 上线 Deep Research,开启了智能体又一新阶段,其能根据用户需求自主进行网络信息检索、整合多源信息、深度分析数据,并最终为用户提供全面深入的解答。
对于很多想用 AI 开发产品但不知道做什么的朋友来说,AI导航网站是很好的选择,因为:1. AI热度大,市场需求大,你做的 AI 导航网站就有更大可能被人用上
第一家全面拥抱DeepSeek的“六小虎”,出现了! 不卖关子,它就是李开复亲任CEO的零一万物。 今日正式上线万智企业大模型一站式平台,宣布提供企业级DeepSeek部署定制解决方案。
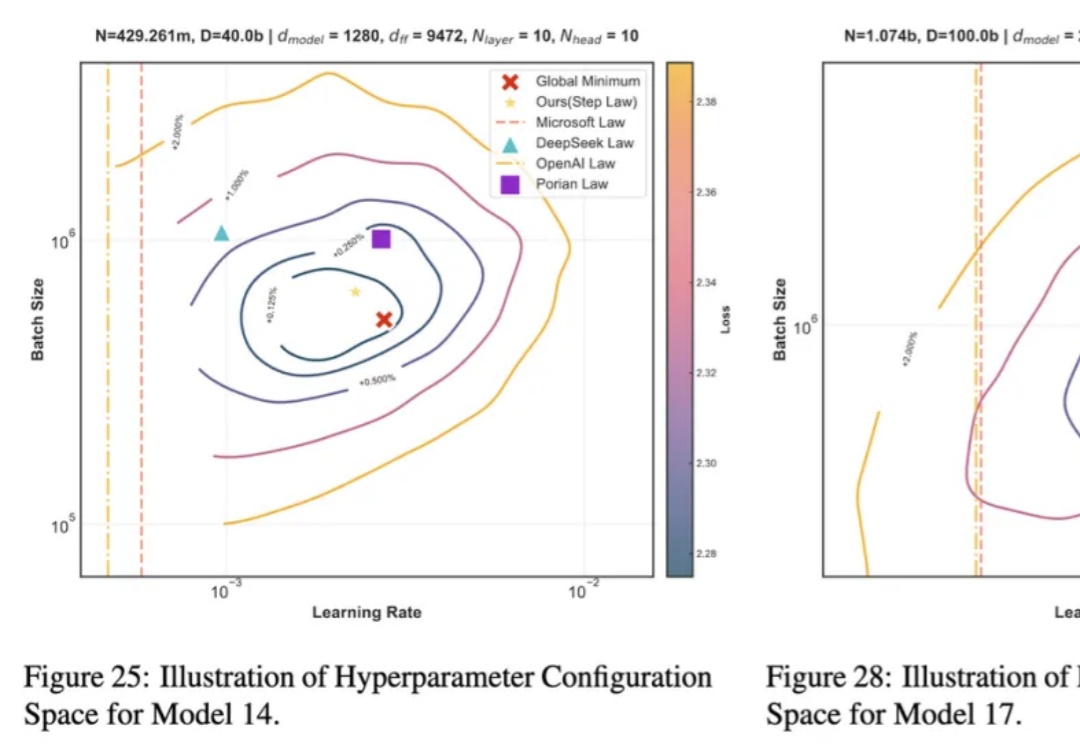
近年来,大语言模型 LLMs 在多种任务上的卓越表现已得到广泛认可。然而,要实现其高效部署,精细的超参数优化至关重要。为了探究最佳超参数的规律,我们开展了大规模的实证研究,通过在不同配置上进行网格搜索,我们揭示了一套通用的最优超参数缩放定律(Optimal Hyperparameter Scaling Law)。

号称地表最强的M3 Ultra,本地跑满血版DeepSeek R1,效果到底如何?
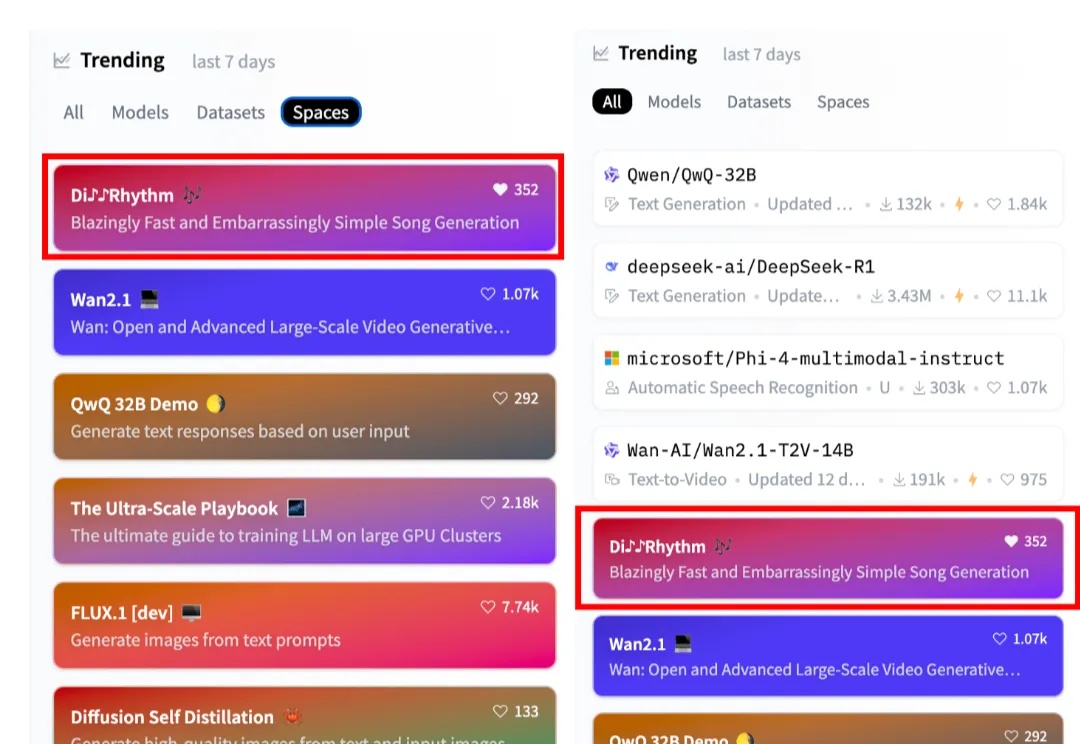
DiffRhythm是一款新型AI音乐生成模型,能在10秒内生成长达4分45秒的完整歌曲,包含人声和伴奏。它采用简单高效的全diffusion架构,仅需歌词和风格提示即可创作,还支持本地部署,最低只需8G显存。

硅基智能开源数字人模型,1秒克隆生成4K视频,支持离线多语言。GitHub可部署。

AI21Labs 近日发布了其最新的 Jamba1.6系列大型语言模型,这款模型被称为当前市场上最强大、最高效的长文本处理模型。与传统的 Transformer 模型相比,Jamba 模型在处理长上下文时展现出了更高的速度和质量,其推理速度比同类模型快了2.5倍,标志着一种新的技术突破。

从今天这个视角来看,DeepSeek 等国内外大模型能力是越来越强大了,大家都说 2025 年 AI 应用还会持续爆发。但对于企业来说,有了大模型,那场景都有啥,应用又长啥样?