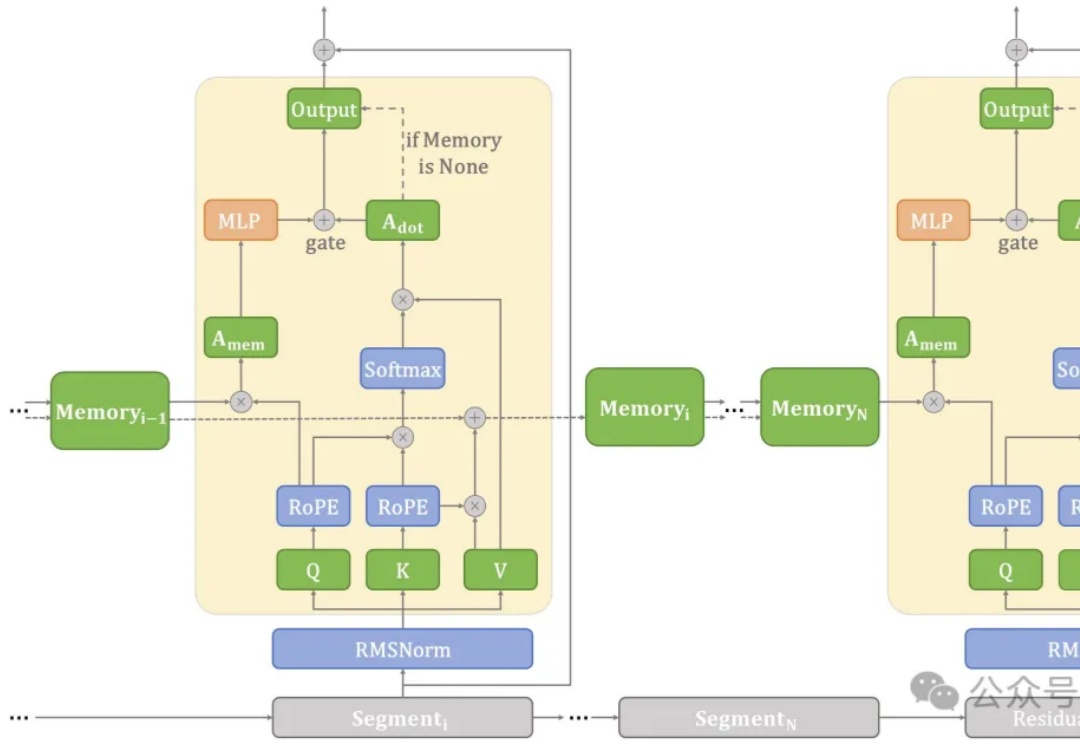
手机流畅处理128K长文本,vivo端侧新算法突破内存限制 | ACL 2025
手机流畅处理128K长文本,vivo端侧新算法突破内存限制 | ACL 2025在端侧设备上处理长文本常常面临计算和内存瓶颈。
来自主题: AI技术研报
11355 点击 2025-05-20 14:54
 搜索
搜索
在端侧设备上处理长文本常常面临计算和内存瓶颈。

北大DeepSeek联合发布的NSA论文,目前已被ACL 2025录用并获得了极高评分,甚至有望冲击最佳论文奖。该技术颠覆传统注意力机制,实现算力效率飞跃,被誉为长文本处理的革命性突破。
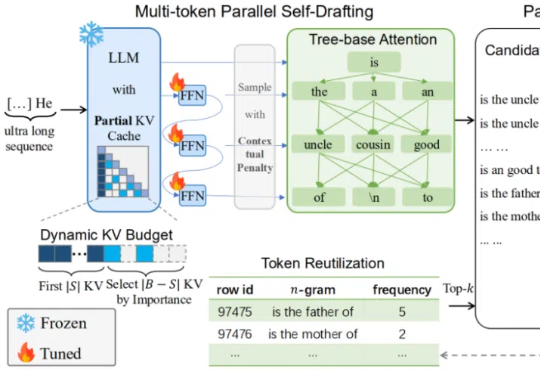
在当前大模型推理愈发复杂的时代,如何快速、高效地产生超长文本,成为了模型部署与优化中的一大核心挑战。
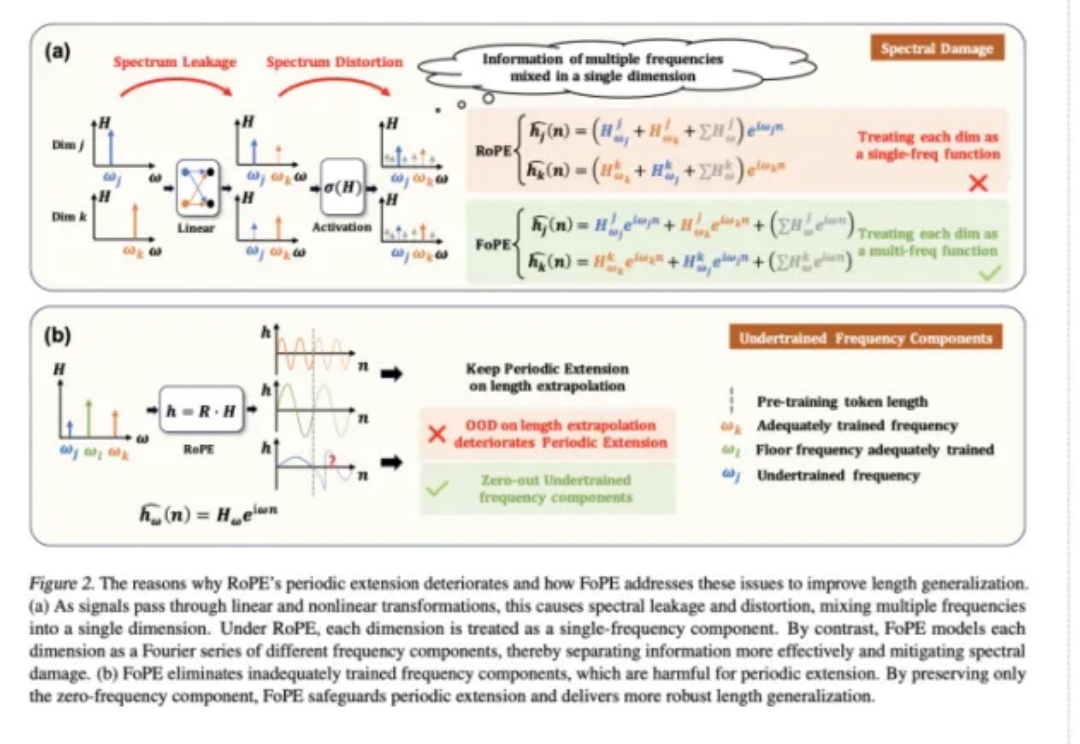
长文本能力对语言模型(LM,Language Model)尤为重要,试想,如果 LM 可以处理无限长度的输入文本,我们可以预先把所有参考资料都喂给 LM,或许 LM 在应对人类的提问时就会变得无所不能。

Nemotron-H模型混合了Transformer和Mamba架构,使长文本推理速度提升3倍,同时还能保持高性能,开源版本包括8B和56B尺寸。训练过程采用FP8训练和压缩技术,进一步提高了20%推理速度
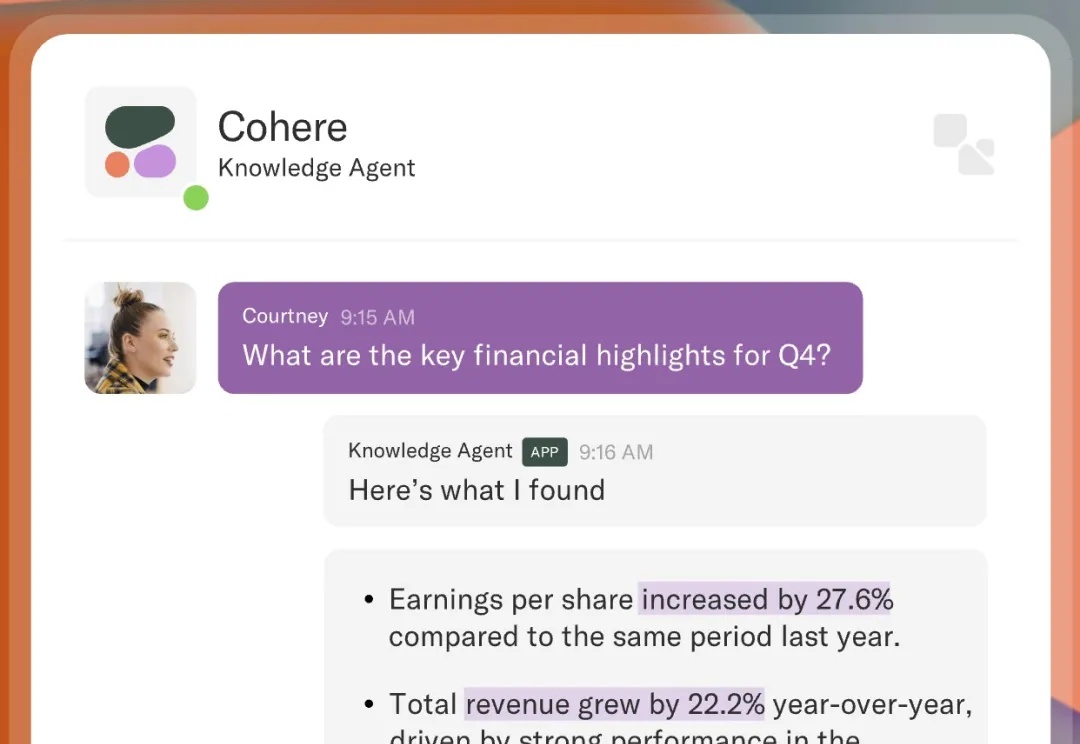
2025年4月16日,Cohere 发布了其最新一代多模态搜索模型 Embed 4,在多模态数据处理、长文本建模和跨模态检索能力上实现了显著提升,进一步巩固了其在企业级 AI 搜索领域的领先地位。

Transformer架构主导着生成式AI浪潮的当下,但它并非十全十美,也并非没有改写者。
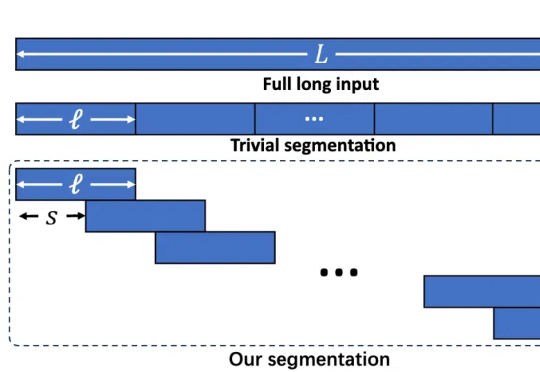
长文本任务是当下大模型研究的重点之一。在实际场景和应用中,普遍存在大量长序列(文本、语音、视频等),有些甚至长达百万级 tokens。
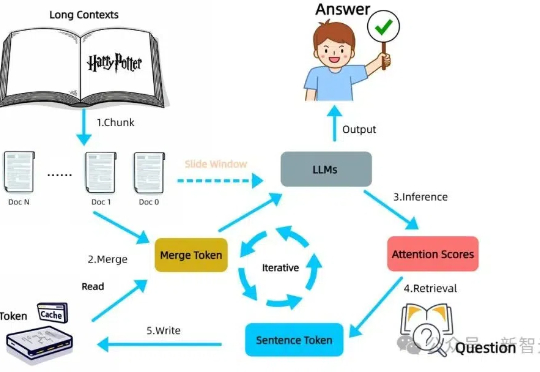
LLM自身有望在无限长token下检索信息!无需训练,在检索任务「大海捞针」(Needle-in-a-Haystack)测试中,新方法InfiniRetri让有效上下文token长度从32K扩展至1000+K,让7B模型比肩72B模型。
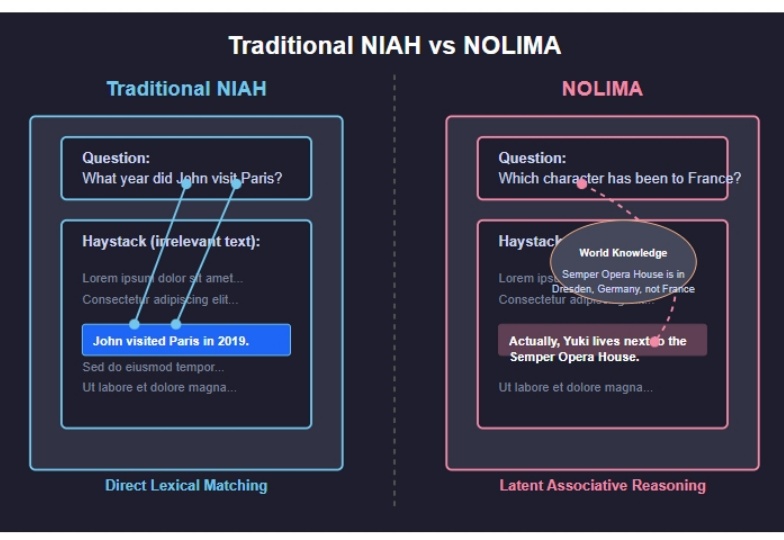
2025 年 2 月发布的 NoLiMA 是一种大语言模型(LLM)长文本理解能力评估方法。不同于传统“大海捞针”(Needle-in-a-Haystack, NIAH)测试依赖关键词匹配的做法,它最大的特点是 通过精心设计问题和关键信息,迫使模型进行深层语义理解和推理,才能从长文本中找到答案。