速递|ElevenLabs发布独立语音检测模型,旨在精细化理解和转录语音
速递|ElevenLabs发布独立语音检测模型,旨在精细化理解和转录语音AI 初创公司 ElevenLabs,刚刚筹集了 1.8 亿美元巨额融资 ,主要以其音频生成能力而闻名。该公司通过推出首个独立语音转文本模型 Scribe,迈向了另一个技术方向。
来自主题: AI资讯
10469 点击 2025-02-27 14:33
 搜索
搜索
AI 初创公司 ElevenLabs,刚刚筹集了 1.8 亿美元巨额融资 ,主要以其音频生成能力而闻名。该公司通过推出首个独立语音转文本模型 Scribe,迈向了另一个技术方向。
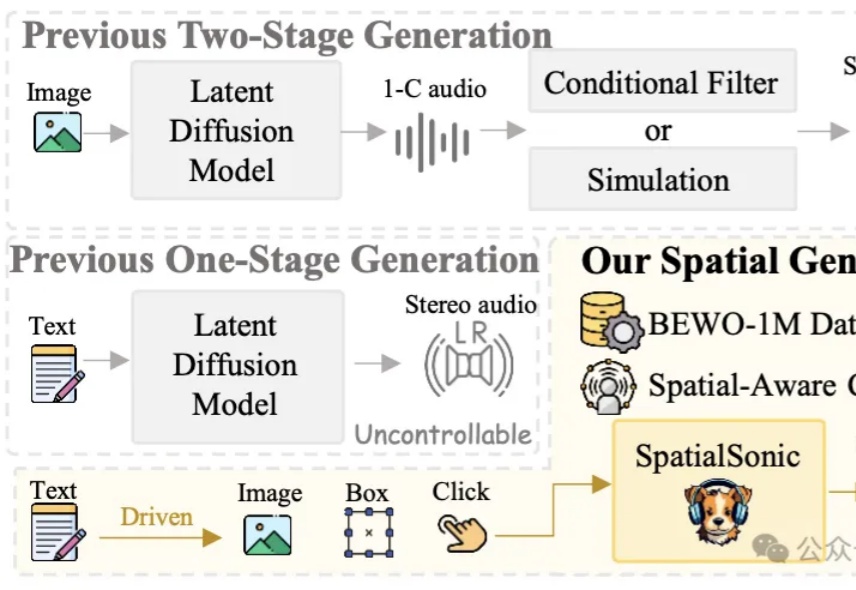
兔子通过两只耳朵可以准确感知捕食者的一举一动,造就了不同品种广泛分布在世界各地的生命奇迹;同样人也需要通过双耳沉浸式享受电影视听盛宴、判断驾驶环境和感知周围活动状态。
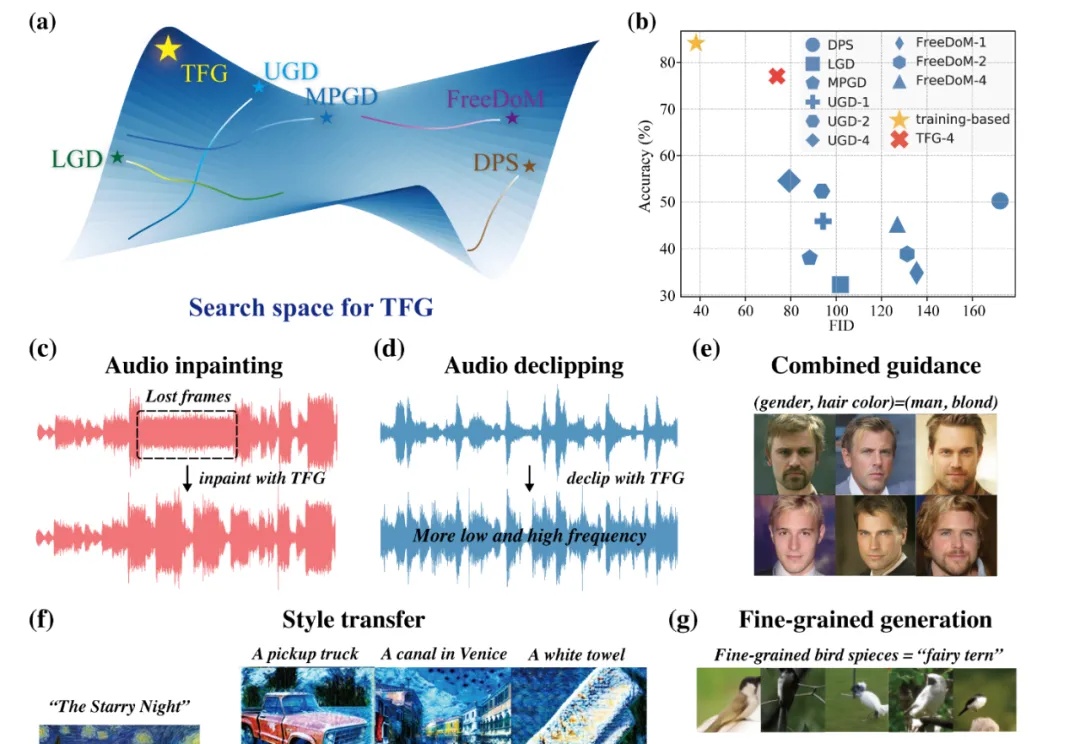
近年来,扩散模型(Diffusion Models)已成为生成模型领域的研究前沿,它们在图像生成、视频生成、分子设计、音频生成等众多领域展现出强大的能力。

DeepMind 公布其正在开发一套创新的音频生成技术细节,也就是NotebookLM背后使用的语音技术。使 AI 能够生成更加自然的对话和高质量的音频。这些技术不仅提升了语音助手的交互性,还帮助多种应用在语音合成和对话生成上取得更大进展。
近期,来自字节跳动的视频生成模型 Loopy,一经发布就在 X 上引起了广泛的讨论。Loopy 可以仅仅通过一张图片和一段音频生成逼真的肖像视频,对声音中呼吸,叹气,挑眉等细节都能生成的非常自然,让网友直呼哈利波特的魔法也不过如此。
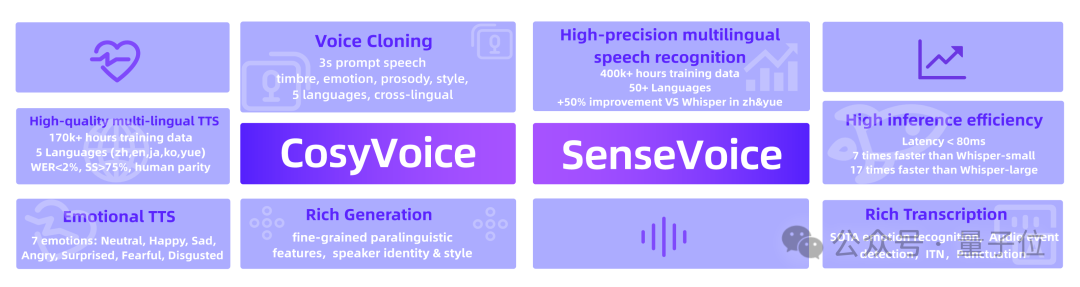
OpenAI迟迟不上线GPT-4o语音助手,其它音频生成大模型成果倒是一波接着一波发布,关键还是开源的。

音频生成领域又有好消息:刚刚,Stability AI 宣布推出开放模型 Stable Audio Open,该模型能够生成高质量的音频数据。

字节大模型团队,终于曝光! 这不是,字节刚刚启动大模型校招计划,招揽人才嘛—— 计划取名Top Seed,薪资TOP级别、算力数据管够,但仅面向应届博士生;前沿课题覆盖大模型、图像&视频生成、机器学习算法和系统以及音频生成和理解等方向。 另外还有一帮顶尖的技术导师团带队……等等,这不就是字节豆包大模型的背后团队吗?
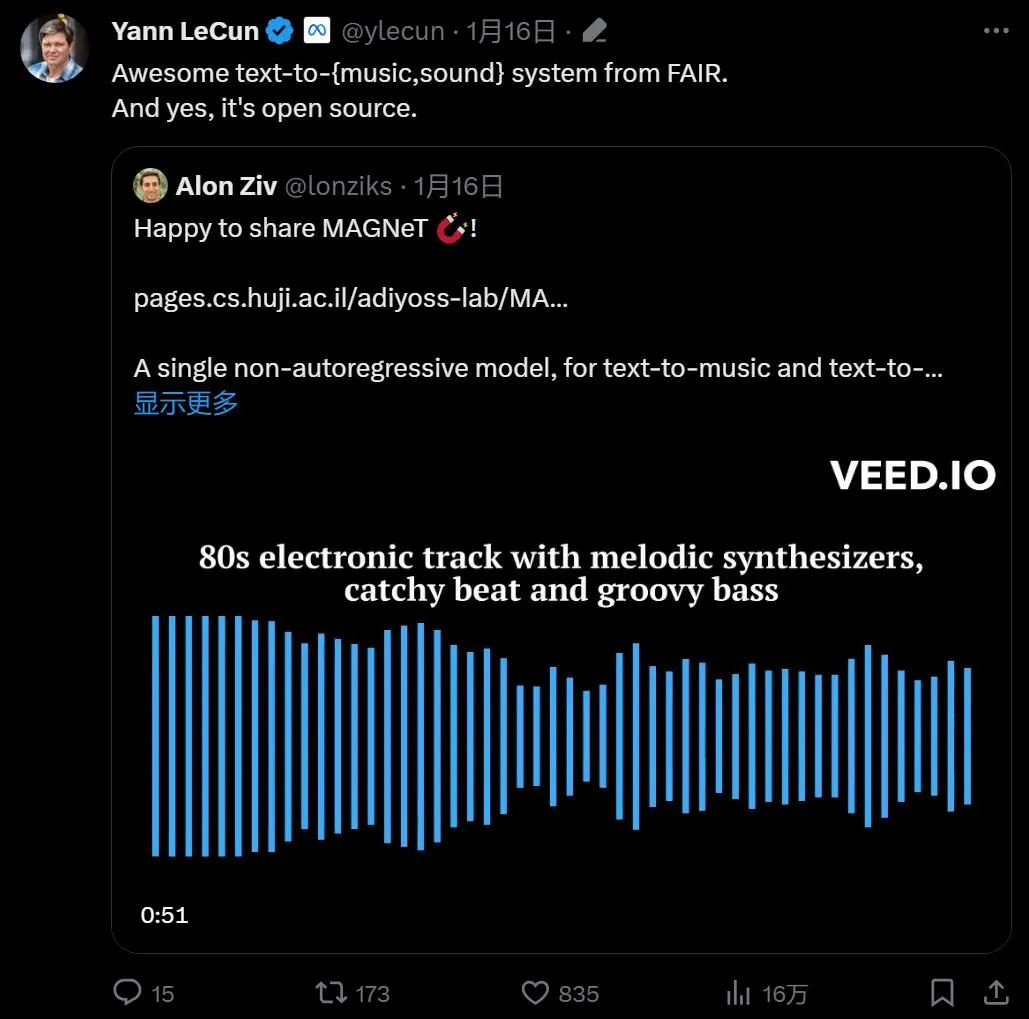
在文本生成音频(或音乐)这个 AIGC 赛道,Meta 最近又有了新研究成果,而且开源了。前几日,在论文《Masked Audio Generation using a Single Non-Autoregressive Transformer》中,Meta FAIR 团队、Kyutai 和希伯来大学推出了 MAGNeT,一种在掩码生成序列建模方法。

香港中文大学(深圳)数据科学学院武执政副教授团队联合上海人工智能实验室 OpenMMLab 团队开源了综合音频生成项目 Amphion(安菲翁)。该系统旨在打造一个集语音合成转换、歌声合成转换、音效音乐生成等多功能为一体的开源平台。