

GPT-5涌现能力可预测?UC伯克利仅使用当前模型检查点预测未来模型
GPT-5涌现能力可预测?UC伯克利仅使用当前模型检查点预测未来模型LLM 规模扩展的一个根本性挑战是缺乏对涌现能力的理解。特别是,语言模型预训练损失是高度可预测的。然而,下游能力的可预测性要差得多,有时甚至会出现涌现跳跃(emergent jump),这使得预测未来模型的能力变得具有挑战性。
来自主题: AI技术研报
9387 点击 2024-11-30 16:51
LLM 规模扩展的一个根本性挑战是缺乏对涌现能力的理解。特别是,语言模型预训练损失是高度可预测的。然而,下游能力的可预测性要差得多,有时甚至会出现涌现跳跃(emergent jump),这使得预测未来模型的能力变得具有挑战性。
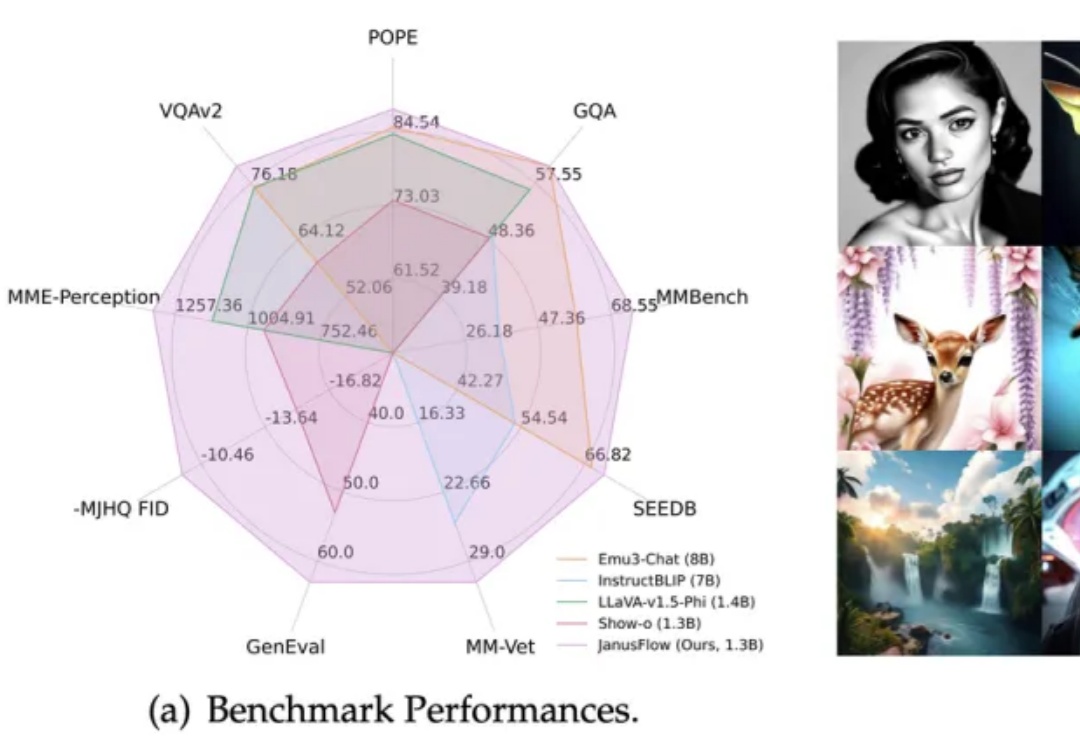
在多模态AI领域,基于预训练视觉编码器与MLLM的方法(如LLaVA系列)在视觉理解任务上展现出卓越性能。
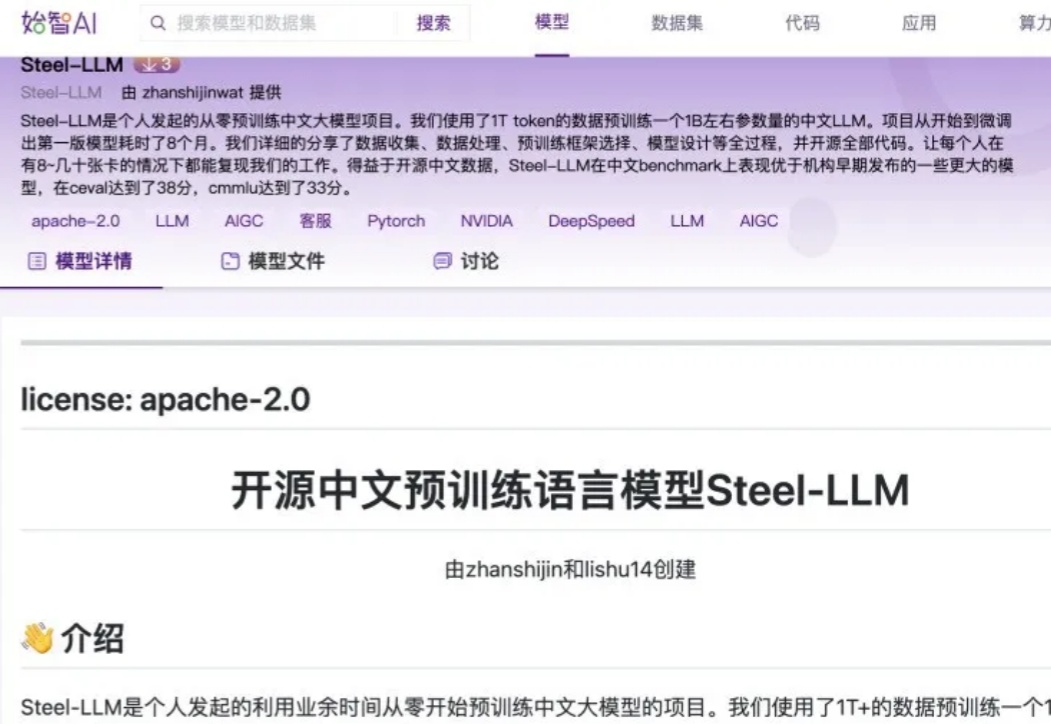
随着开源数据的日益丰富以及算力价格的持续下降,对于个人或小型机构而言,预训练一个小型的 LLM 已逐渐成为可能。开源中文预训练语言模型 Steel - LLM 就是一个典型案例,其模型参数量与数据量并非十分庞大,基本处于参数量为 B 级别、数据量为 T 级别的规模。
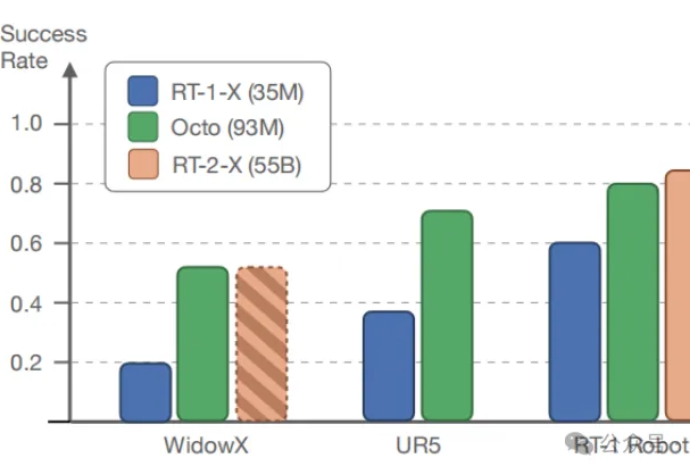
在多样化的机器人数据集上预训练的大型策略有潜力改变机器人学习:与从头开始训练新策略相比,这种通用型机器人策略可以通过少量的领域内数据进行微调,同时具备广泛的泛化能力。

Ilya终于承认,自己关于Scaling的说法错了!现在训练模型已经不是「越大越好」,而是找出Scaling的对象究竟应该是什么。他自曝,SSI在用全新方法扩展预训练。而各方巨头改变训练范式后,英伟达GPU的垄断地位或许也要打破了。
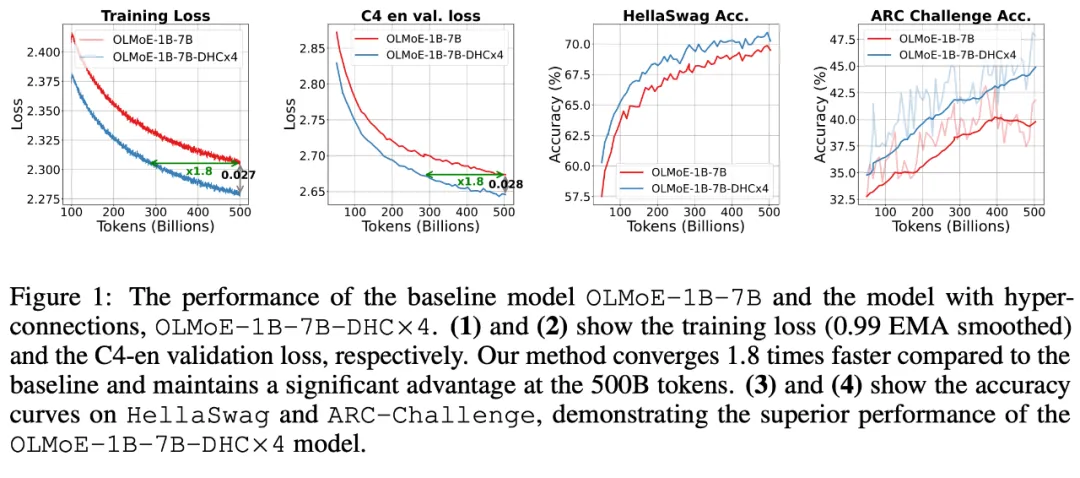
字节跳动豆包大模型团队于近日提出超连接(Hyper-Connections),一种简单有效的残差连接替代方案。面向残差连接的主要变体的局限问题,超连接可通过动态调整不同层之间的连接权重,解决梯度消失和表示崩溃(Representation Collapse)之间的权衡困境。在 Dense 模型和 MoE 模型预训练中,超连接方案展示出显著的性能提升效果,使收敛速度最高可加速 80%。

来自中科大等单位的研究团队共同提出了用来有效评估多模态大模型预训练质量的评估指标 Modality Integration Rate(MIR),能够快速准确地评估多模态预训练的模态对齐程度。

在人工智能领域,大型预训练模型(如 GPT 和 LLaVA)的 “幻觉” 现象常被视为一个难以克服的挑战,尤其是在执行精确任务如图像分割时。
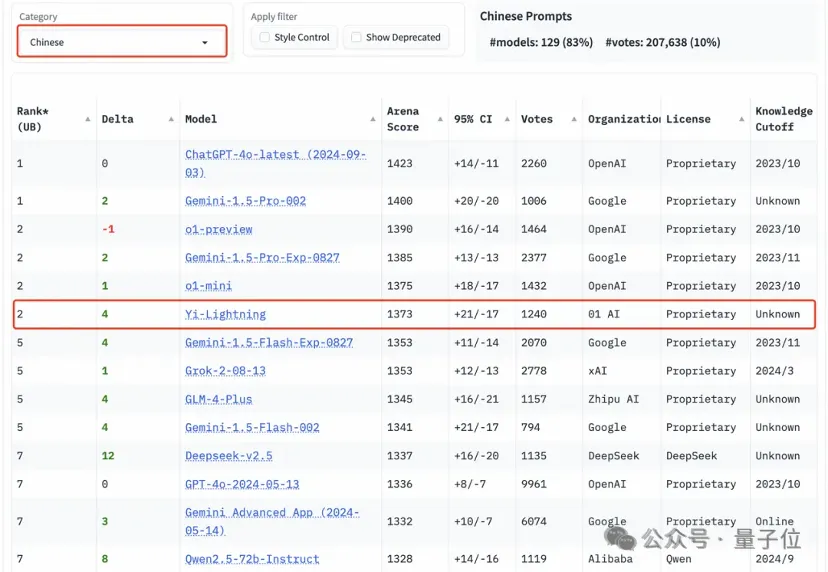
国产大模型首次在国际最具挑战的“大模型竞技场”榜单上超过GPT-4o(5月版本),当零一万物的名字紧跟在OpenAI、Google之后,李开复却如是坦言。

近年来,大语言模型(Large Language Models, LLMs)的研究取得了重大进展,并对各个领域产生了深远影响。然而,LLMs的卓越性能来源于海量数据的大规模训练,这导致LLMs的训练成本明显高于传统模型。