

官宣开源|Milvus 3.0 正式发布
官宣开源|Milvus 3.0 正式发布近日,Milvus 3.0 正式上线。作为 Milvus 架构演进中的里程碑式版本,3.0 不仅带来多项突破性新功能,更从底层重塑了向量数据的存储、索引与检索边界。在 Milvus 3.0 中,你可以获得:
来自主题:
AI资讯
8508 点击 2026-08-03 22:55
 搜索
搜索
近日,Milvus 3.0 正式上线。作为 Milvus 架构演进中的里程碑式版本,3.0 不仅带来多项突破性新功能,更从底层重塑了向量数据的存储、索引与检索边界。在 Milvus 3.0 中,你可以获得:

刚刚,杭州大模型公司西湖心辰宣布,公司近日完成数亿元人民币B+轮融资。该公司创始人蓝振忠,是卡耐基梅隆大学AI博士、自然语言处理预训练语言模型“ALBERT”第一作者,曾任谷歌人工智能研究院科学家,研究成果已被应用于Google News、Google Assistant 等数亿级用户产品中。他于2020年6月受聘于西湖大学,创办深度学习实验室并担任博士生导师。

Imagi宣布完成450万美元种子轮融资,投资方包括Brighteye Ventures、Day One Capital以及知名艺术家will.i.am。出身教师世家的Dora Palfi,与大学好友Beatrice Ionascu于2018年共同创立了Imagi。这家教育科技公司致力于为K-12学生和教师提供编程、基础计算机技能及AI素养的教学工具与课程。
未来几年,医疗大模型的行业竞争将不再局限于基础模型技术的单点对抗,而是演变为模型能力、医疗数据、临床场景、医院生态四位一体的综合实力竞争。下文筛选海内外各10家代表性企业,集中展现了全球医疗大模型产业链核心力量与资本流向(本文内容仅作行业研究参考,不构成任何投资建议、投资引导及相关承诺)。

近日,港科大团队孵化的项目Aivilization正式改了名字,叫作AI小镇星原。去年八月,团队刚上线一个连自己都觉得够不上及格线的版本,压力测试只按两三千人的规模准备,结果不到三天,注册用户就冲破了五万,此后热度一路攀升,参与的玩家累计超过十万。

但如果你问的问题收束成:「今年最火的 AI 可穿戴硬件是什么?」那答案大概率只有一个—— Fitbit Air。仅仅一个数据就足以说明它的现象级爆火:作为一款官方开售已经超过两个月的设备,在二手平台你至今仍然需要加价 200~300 元购买。

Grok,学会一键看片了?
连续自主编程16天,24小时击败458支人类队伍。
其实 Codex 和 Claude Code 都支持切换模型,咱们直接用 DeepSeek-V4-Flash 来驱动它们就行,量大管饱、不用魔法、也不怕封号。而且现在 DeepSeek 官方已经做了原生适配,接入流程比以前简单多了。
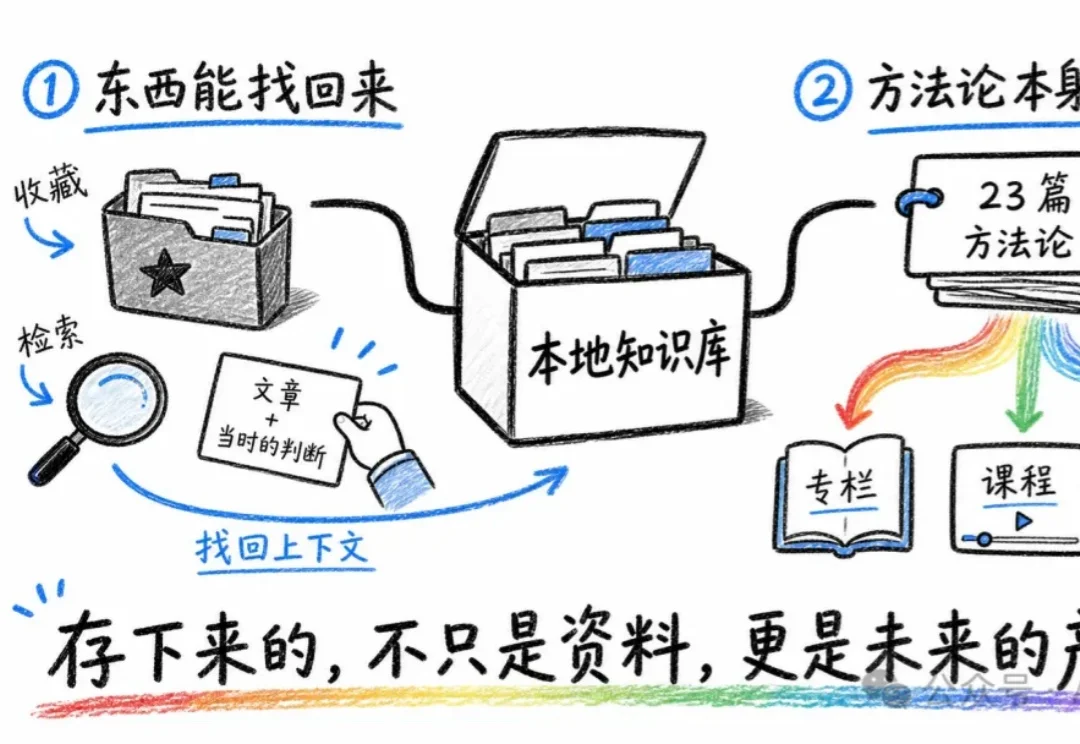
7 月初的时候,我照着 Karpathy 那套 LLM Wiki(简单说就是让 AI 帮你把资料编译成一个能长大的百科)搭了个本地知识库。

今年 WAIC,最热闹的区域之一,是超维动力展台的一张乒乓球桌。
话不多说,直接开始每日瘫坐(doge)!

最近,有个很有意思的现象。
2026 年的 YC Startup School 上,Jeff Dean 的声音有些沙哑。

Token可以“热”,但Token工厂必须靠原生液冷“冷”下来。

25分钟,500个钱包被洗劫一空!
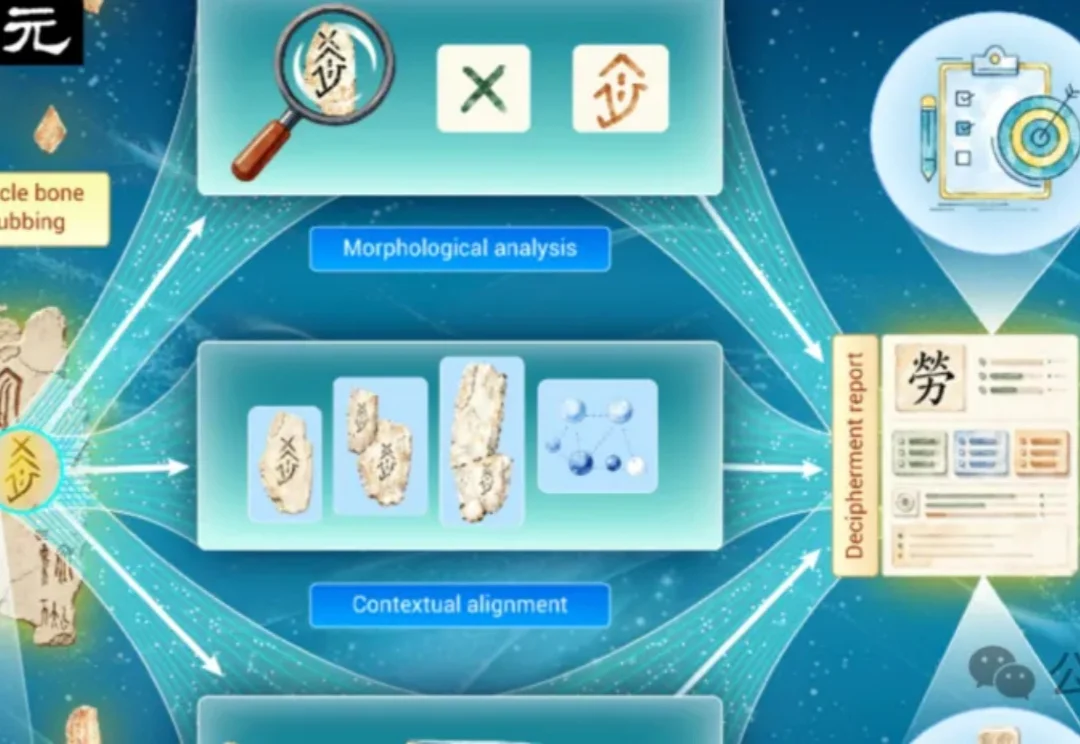
一片龟甲或牛肩胛骨摆在案头,裂纹穿过刻辞,几个字还缺了笔画。

如何从一段视频中获得完整、稳定的 3D 物体?过去,这个问题大致沿着两条路线发展。
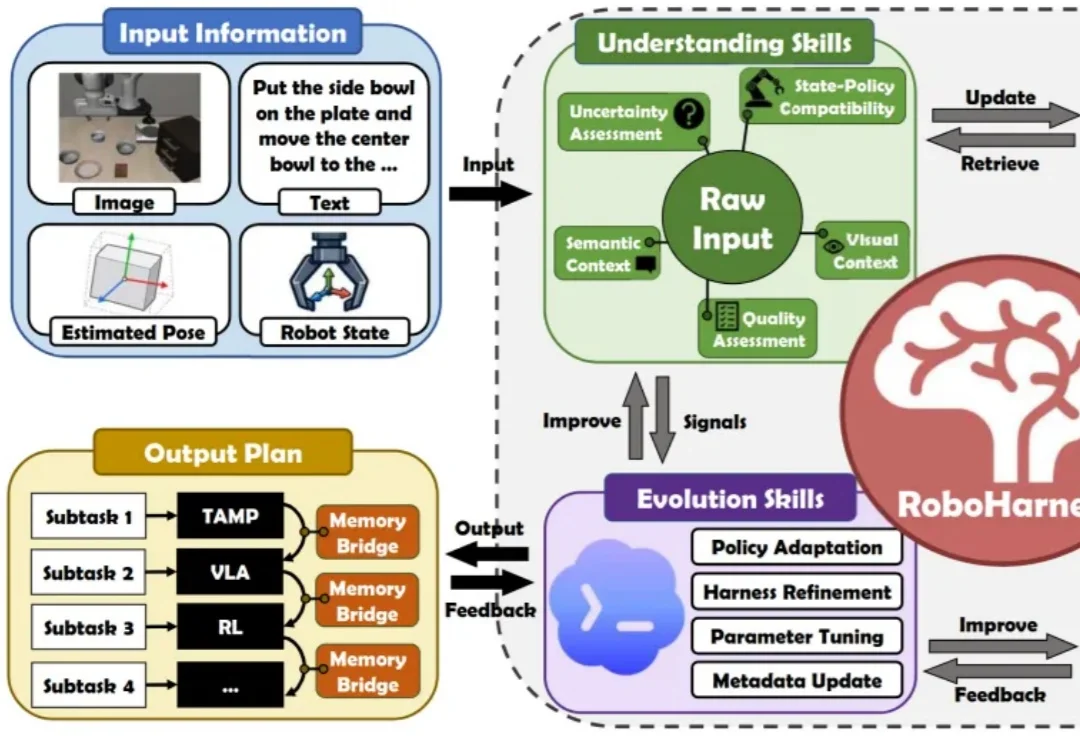
当 VLA、WAM、RL、TAMP、MPC 等机器人控制策略在各自擅长的任务中大放异彩,如何刻画其能力边界,并在正确的时机为不同子任务匹配最合适的策略,正逐渐成为机器人完成复杂长时序任务的关键。

OpenAI内部最新推理模型,一口气发布了十项惊人的数学进展。

WAIC之后,具身智能行业进入了一段微妙的冷静期。
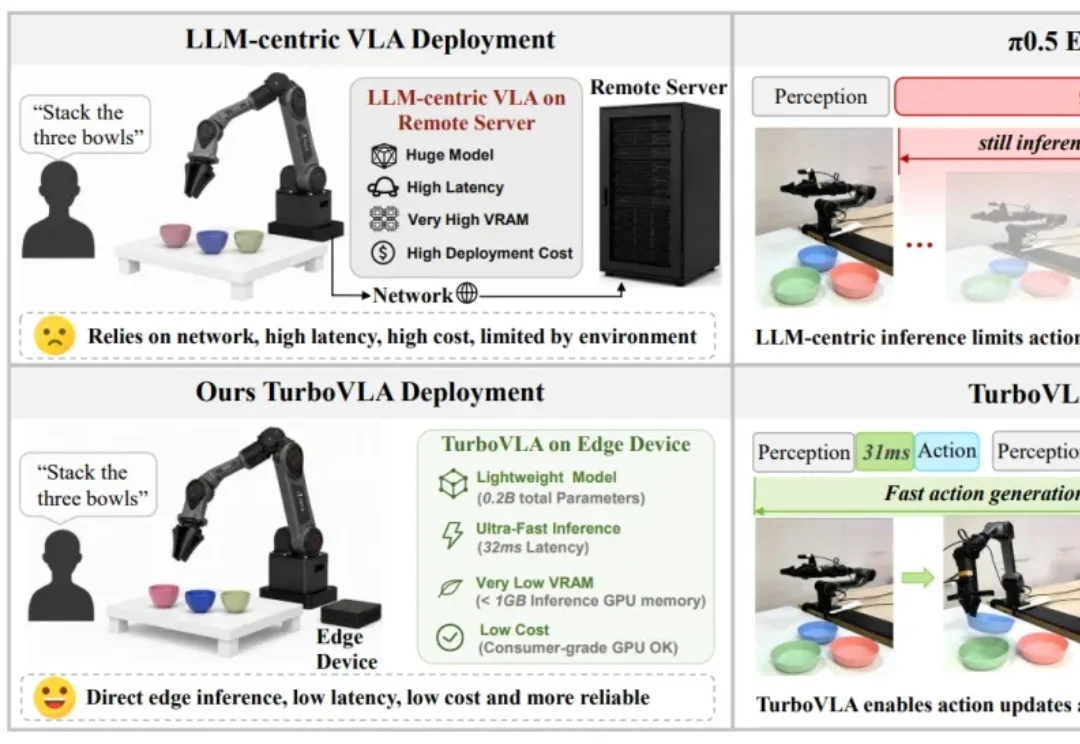
近年来,视觉 — 语言 — 动作模型(Vision-Language-Action Model,VLA)正逐渐成为通用机器人控制的重要技术路线,但当这些模型真正进入高频闭环执行时,一个矛盾越来越突出:模型越来越大、语义能力越来越强,动作更新却未必足够快。
8 月 3 日,在 AGI Playground 2026 大会上,Genspark 创始人&CEO 景鲲在现场发布了一款新产品 GenOffice。这是一个面向 Windows 和 Mac 的本地 Office 客户端。开源、免费、无广告,保留用户熟悉的文档编辑能力,同时把 AI 引入 Word、PPT 等高频办公场景。
8 月 3 日,阿里巴巴正式发布新一代基座大模型 Qwen3.8,总参数量 2.4 万亿,在编程(Coding)和专业办公(Cowork)方面能力大幅提升。今日放榜的权威三方榜单 Arena 中,阿里 Qwen 模型仅次于 Anthropic 的 Claude 系列,整体性能处于全球大模型第一梯队。。

Jay 发自 凹非寺 量子位 | 公众号 QbitAI 啥,谷歌真比OpenAI还早一年搞出了ChatGPT? 不是谷歌事后找补了,这次是OpenAI自己人,Codex负责人Tibo刚佐证的消息: 那
又一家AI初创公司加入了这场狂飙突进的独角兽俱乐部:Simile。据该初创公司透露,就在结束隐身状态、宣布完成由Index Ventures领投的1亿美元A轮融资仅仅五个月后,公司已完成2亿美元B轮融资,估值达到20亿美元。

AI浏览器正为用户完成跨网站的重复工作。

美国政府正在成为 AI 基建的“超级风投”。按公开交易逐笔统计,过去 14 个月,特朗普政府公布的股权或准股权安排已增至约 37 笔。

「我明天要见心理咨询师,」一位居住在波士顿的年轻妈妈,正在规划第二天的行程,不过,这话她既不是说给丈夫听的,也不是说给孩子听的,而是说给 Claude 听的。「帮我捋一捋上次咨询之后我们聊过什么,有什么该拿出来说的。」
最近,一款叫Town的AI助手,成了硅谷创投圈最火的AI产品之一。

