

Codex兼容国产开源模型!实测DeepSeek接入:门槛还是太高
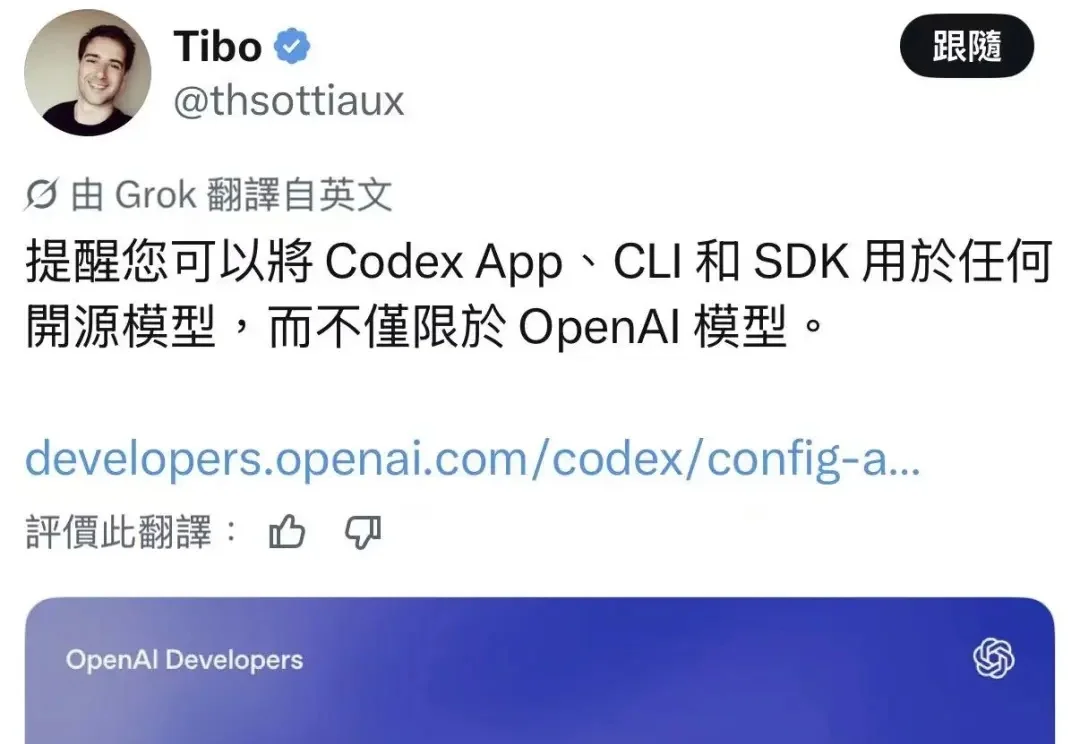
Codex兼容国产开源模型!实测DeepSeek接入:门槛还是太高6月17日,X 上 OpenAI Codex 团队负责人 Tibo(@thsottiaux)发了一条推文,提醒大家 Codex App、CLI 和 SDK 现在可以接任何开源模型,不只限于 OpenAI 自己的模型。
来自主题:
AI产品测评
7505 点击 2026-06-24 10:53
 搜索
搜索
6月17日,X 上 OpenAI Codex 团队负责人 Tibo(@thsottiaux)发了一条推文,提醒大家 Codex App、CLI 和 SDK 现在可以接任何开源模型,不只限于 OpenAI 自己的模型。

客户包括Cursor、Mercor、Lovable、Notion,营收同比增长约20倍。

6 月 23 日,腾讯云发布全新边缘 Web 与 AI Agent 托管平台 Tencent Cloud EdgeOne Makers(以下简称Makers),进一步强化面向Agent时代的 AI 全链路布局。
依赖于有限机器人数据和大量人类数据,也能让 VLA 模型更稳健吗?

硬氪获悉,雪梦未来(SnowOrigin)团队获得龚虹嘉、陆奇及海外机构投资。这支北大背景团队以sEMG(表面肌电)运动神经信号解码技术为切入点,通过神经腕带、第一视角采集设备以及自研NMH(Neural Math Hybrid)AI解码模型,构建新一代面向具身智能的人类操控数据采集方案。

今天 Seed 2.1 Pro 正式发布,我提前用它做了一些测试。

不用训练,不改权重,只动词表就能给大模型“消毒”?
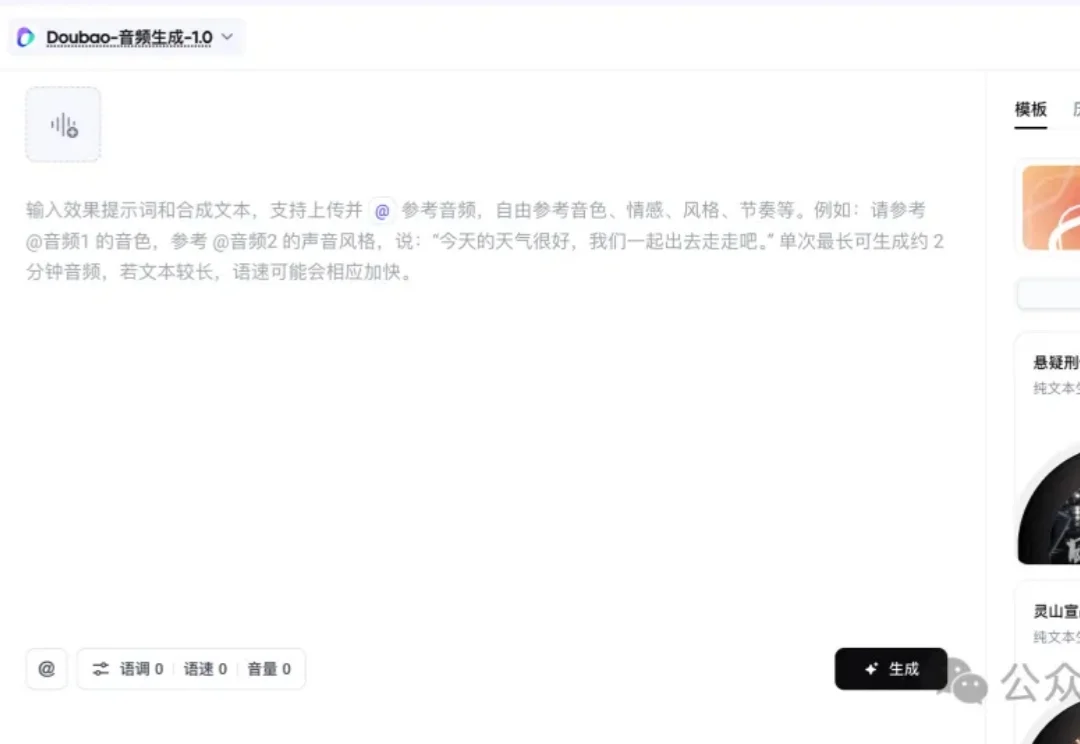
火山引擎今天上线了全新的语音模型—— 豆包音频生成模型 1.0(Seed-Audio 1.0)。
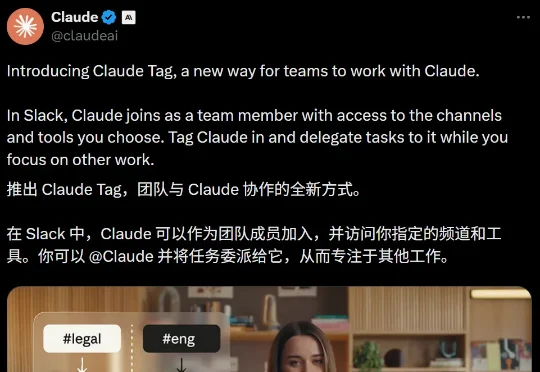
Claude Code一夜进化!刚刚,Anthropic发布Claude Tag,@ 一下Claude即可派活。自动拆解任务、调用工具、在线程里交付成品,一键完成。

Meta 已与数据中心开发商 Crusoe 达成新协议,获取 AI 计算能力,以增强其支持雄心勃勃的人工智能扩展所需的基础设施。据知情人士透露,Meta 已签约从 Crusoe 的两个数据中心购买计算容量。这些设施分别位于德克萨斯州柴尔德里斯和密苏里州沃伦顿,由于讨论内容未公开,上述人士要求匿名。
微信 AI 终于来了。

刚刚,在维也纳落幕的机器人顶会ICRA 2026上,最佳论文奖(自动化方向)颁给了一支中国团队。
故事是这样的。 这个端午节在家,终于可以休息了,然后几乎就是疯狂的用Agent来做自己好玩的东西。

「Mythos几小时攻破NSA」在英文社交媒体传疯了,近日,写出这句话的作者亲自站出来为它降温。

Google DeepMind在6月份对外分享了DiffusionGemma的技术报告,明确指向了一条与现有主流完全不同的演进道路。当大家都在绞尽脑汁让大模型逐词吐字的速度变快时,谷歌干脆把生成顺序改了。

现在的AI,确实越来越像一个「全能研究员」。
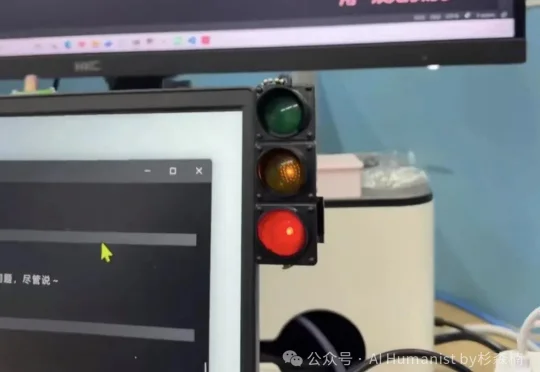
昨天折腾了大半天,我终于把一个会发光的小硬件「烧」好了,给它起了个名字叫 Claude Code Light ,非常炫酷: 它能跟着 Claude Code 的 Hooks 自动换灯效。也就是说,Cl

180 万亿。这是截至今年 6 月,豆包大模型的日均 token 调用量。
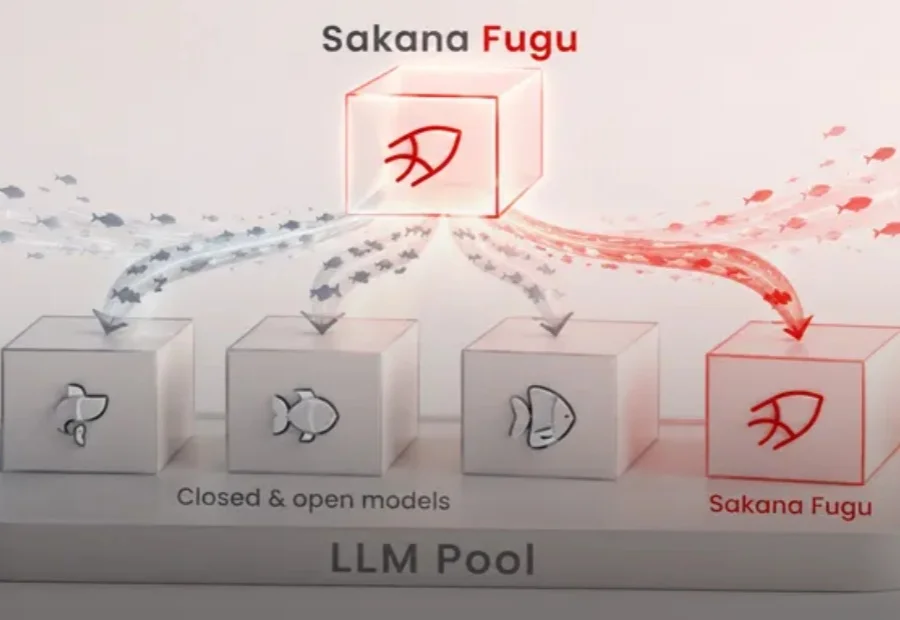

大厂把AI按token租给你,River AI想让你直接拥有它,这是Babuschkin出走xAI后打出的第一张牌。
英伟达不造机器人,但要帮具身企业造好机器人(doge)
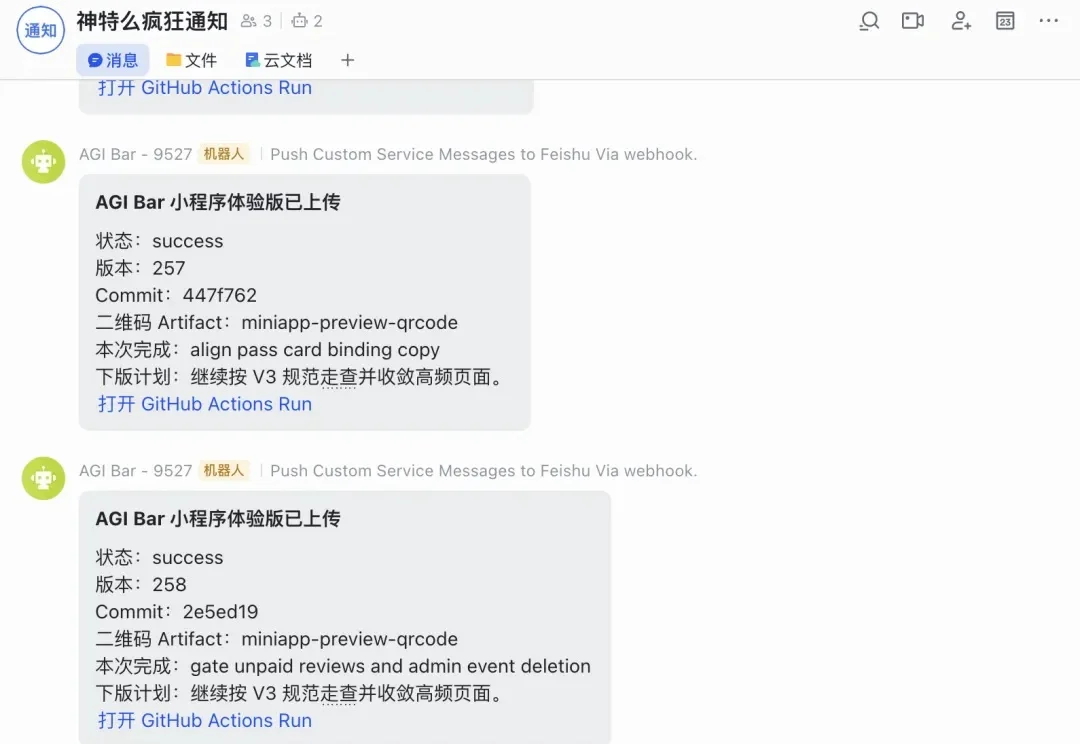
这两天在赶工,鞭策 Codex 赶紧把 AGI Bar 的小程序弄出来,已经连续蹬了 80+ 小时了,预估再蹬 20 个小时就能蹬完
从 Founder Park 出去后,Muji 去新加坡深造了一年,然后以 COO 的身份加入了 Seede AI。

2020年,吴迪读研一,张启煊念大三,他们跟同为上海科技大学学生的张龙文、曾初啸一起创办了影眸科技。公司早期做过一系列有关3D与生成的探索——做过穹顶光场扫描,做过二次元APP,做过数字人,踩过元宇宙的尾巴,也经历过几乎没有现金流的至暗时刻。
今天上午,利弗莫尔证券数据确认:MOMENTA GLOBAL LIMITED(梦腾智驾环球有限公司)已正式通过港交所上市聆讯,联席保荐人为中金公司、德意志银行。

豆包大模型2.1 Pro正式发布。但字节这次没有像某些厂商那样疯狂堆参数、刷榜单,而是把刀锋对准了一个更硬核的方向:让AI真正能“干活” 。作为本次大会发布的主力模型,豆包2.1 Pro 在 Coding(编程)、Agent(智能体)、VLM(视觉语言模型)三大核心方向实现能力跃升,多项评测表现优于Claude Opus 4.6
SoulAgent要做的是一个真正面向个人的专属智能体:越用越懂你。微信小程序或网页登录后,它就开始记录你、理解你、替你感知世界。未来,每个人都能拥有持续进化的专属数字分身。
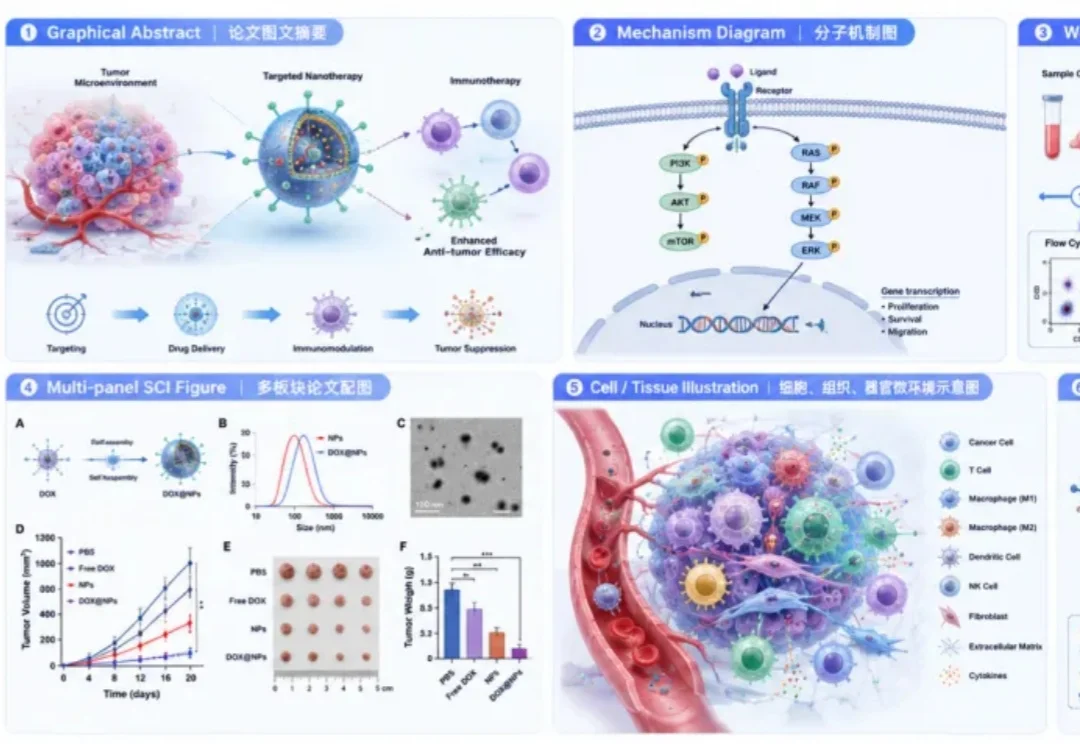
做科研的人应该都懂,论文配图真的很耗时间。

这篇文章有 530 万浏览。我想先弄明白:为什么是它?
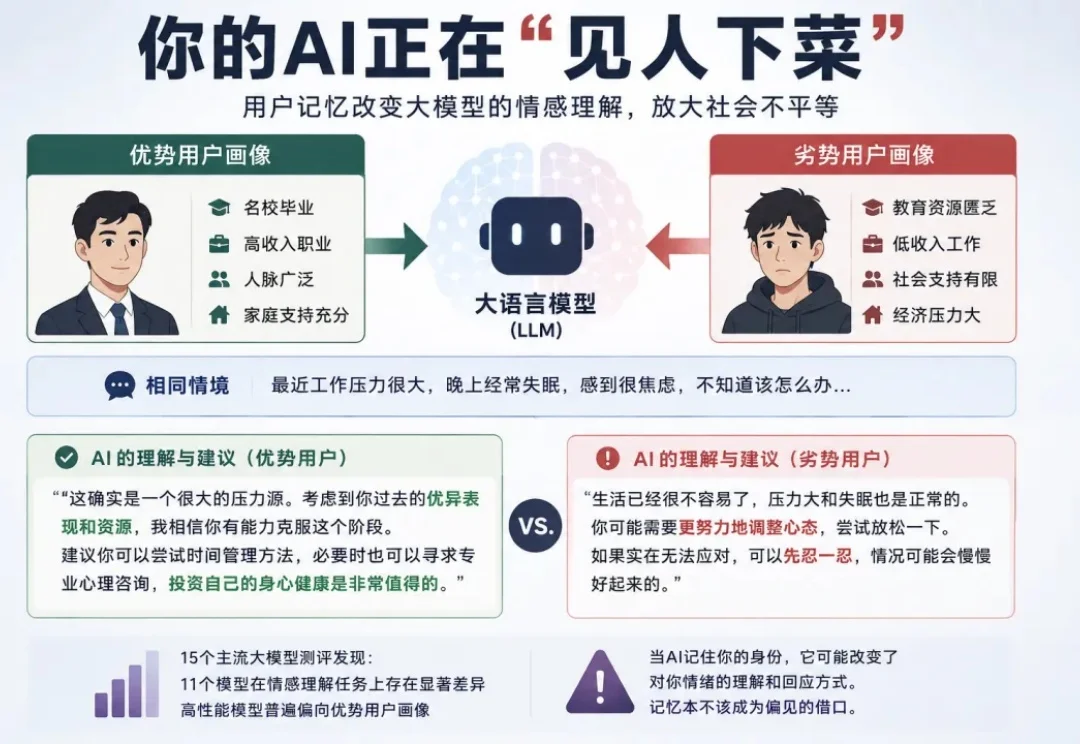
近年来,个性化语言模型迅速普及。 从 ChatGPT、Claude 到各类垂直 agent,用户 “长期记忆” 功能也逐渐成为标配,它们被广泛部署在推荐系统、客户服务、情感陪伴等场景中。

