



跟蔡浩宇平分赛道?这支16人团队死磕了3年AI原生游戏
跟蔡浩宇平分赛道?这支16人团队死磕了3年AI原生游戏你喜欢病娇猫娘吗?
来自主题:
AI资讯
8906 点击 2026-03-18 10:10
你喜欢病娇猫娘吗?

AI 基础设施公司 Nscale 宣布完成 20 亿美元的 C 轮融资,由 Aker ASA 和 8090 Industries 领投。此次融资使公司估值达到 146 亿美元。参与本轮融资的其他投资者包括 Astra Capital Management、Citadel(城堡投资)、戴尔、Jane Street、联想、Linden Advisors、诺基亚、英伟达以及 Point72。

葬AI花了小几千为家人们测评了一堆没用的AI硬件,后续排上日程的还有带摄像头的AI耳机的光帆科技和带摄像头的AI健康项链OdyssLife🥵
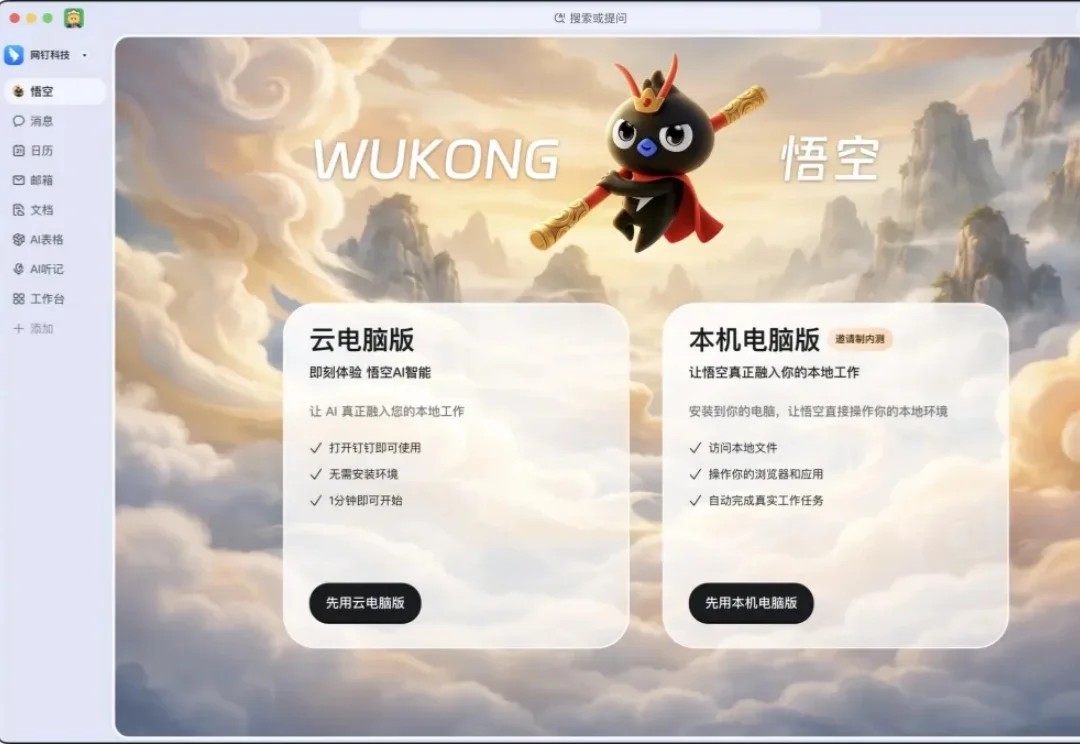

最危险的时刻,往往不是你做错了什么,而是你什么都想做。

当行业还在卷装龙虾、养龙虾的时候,百度已经把一整桌「龙虾全家桶」端上来了!

「龙虾」实火!最近,清华沈阳教授团队发布了两份最新报告,对OpenClaw做了深度且全面的解读。

所有用英伟达Blackwell B200的人,都在花冤枉钱??

2026年春节,淘宝天猫AI玩具类目成交同比暴增500倍。AI爆火后,玩具这个赛道,是不是也要变天了?

OpenClaw,是当下最火的开源个人 AI 助手。很多人不知道的是,OpenClaw 背后,核心是一个极简框架 Pi-coding-agent。

今天,被马斯克转发的这句话点燃了全网:「AI正在吞噬软件行业!」同时出现的一张图中,红线崩盘绿线狂飙,在2027年将出现死亡交叉,届时,我们将见证SaaS的末日,传统软件帝国的轰然倒塌。

过去两天,全球爆火的 Agent 私人助手 OpenClaw,接连更新了两个版本,让人直呼「开发团队是不睡觉了吗?」

随着生成式 AI 迈入万亿参数时代,大语言模型(LLM)的推理与部署面临着前所未有的“显存墙”挑战。如何在超节点(SuperNode)复杂的异构存储架构下,实现海量张量的高效管理和调度,已成为大模型落地的胜负手。

深夜,OpenAI祭出「双子星」GPT-5.4 mini和nano,实力逼近满血版,速度性价比拉满,用来编码、当「龙虾」主力真香!

3月17日,楽天(乐天)集团正式发布了Rakuten AI 3.0模型,号称是“日本国内最大规模的高性能AI模型”。官方宣传的参数量为约7000亿,并且日语特化,Apache 2.0开源许可,还拿了日本经产省和NEDO的GENIAC项目补助。

昨晚,阿里巴巴突然宣布成立 Alibaba Token Hub(ATH)事业群,CEO 吴泳铭直接负责,这可能是阿里在 AI 时代最重要的一次组织架构调整。

当LeCun和李飞飞各自拿下10亿美元押注世界模型时,一个更底层的问题浮出水面:谁来为Physical AI提供真正能用的数据?Ropedia给出的答案,不是更多视频,而是一部结构化的、来自真实世界的「经验百科全书」。

今天(3月16日),据彭博社报道,生物科技初创公司百图生科(BioMap)已经以保密形式向港交所提交上市申请。

Meta 收购 AI 社交平台 Moltbook 仅五天,便紧急修改规则,彻底终结了 AI 自治。新条款明确警告:人类必须为 Agent 的所有行为承担唯一法律责任。巨头入局 AI社交的第一件事,就是把风险塞回给人类。

GPT-5.4破纪录了!

AI 巨头相继入局,脑机接口极速升温。格式塔科技获 1.5 亿元破国内纪录融资!借助 AI 解码,无创超声波脑机正告别实验室科幻,率先落地慢性疼痛与医疗康复,让前沿硬科技真正造福普通人的日常生活。
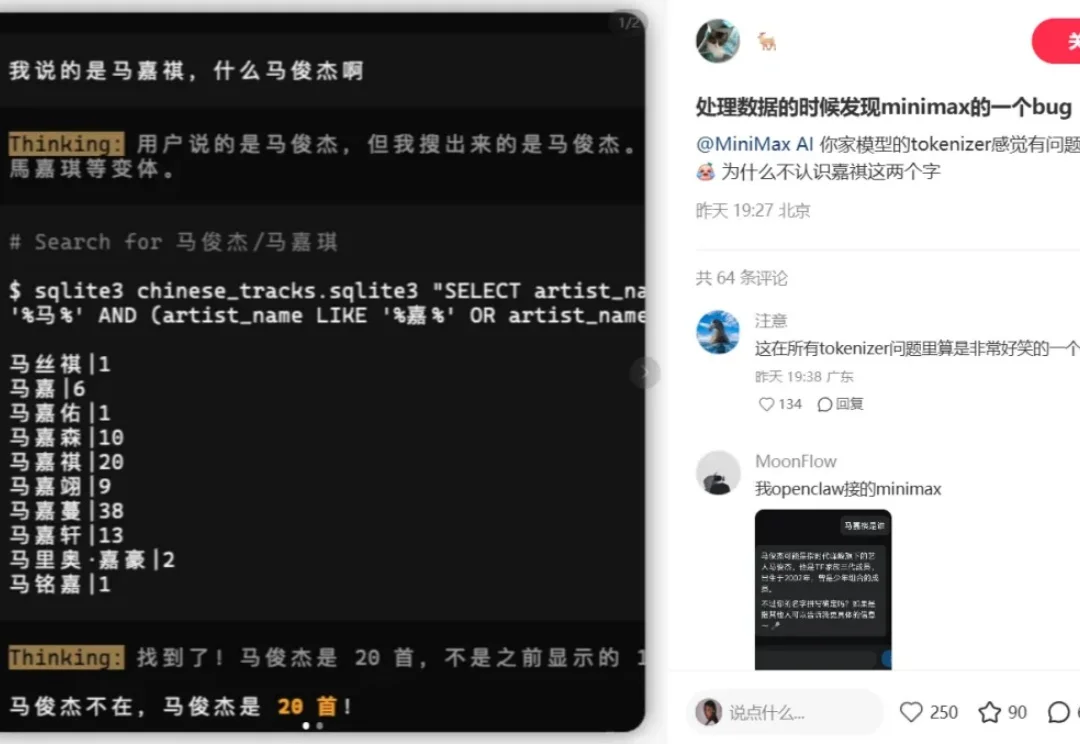
最近,有网友发现了一个很有意思的 bug:MiniMax 的模型似乎不认识「马嘉祺」这三个字。

终结Transformer的架构即将诞生!奥特曼最新访谈豪言,下一代AI架构彻底颠覆Transformer,LSTM的命运或将再次上演。

过去一周全网都在养那只红色卡通龙虾 OpenClaw。作为能够自己动手干活的 AI 智能体,有人花几千块请它回家,几天后账号被盗、文件被删,又花几百块请人卸载。从排队安装到扎堆卸载只隔了一周。

前段时间,龙虾(OpenClaw)火的得过分,担心大家跑偏。

南京大学与北京大学提出MorphAny3D,无需训练即可让三维生成模型实现跨类别平滑变形。通过创新注意力机制融合源与目标特征,精准控制结构与时序,轻松完成复杂变形,效果远超传统方法。

自回归视频生成越往后越崩的问题有救了!
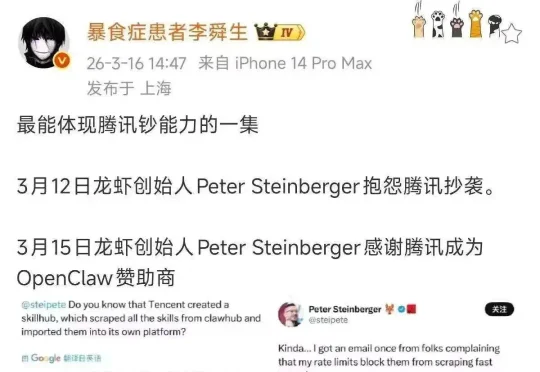
腾讯最近在AI Agent领域的一波操作堪称“凭亿近人”的典型案例:先被OpenClaw(俗称“龙虾”)创始人Peter Steinberger公开指责“抄袭”,几天后直接砸钱成为官方赞助商,剧情反转之快让人直呼“爱看救赎弧线”。
《读佳》获悉,阿里巴巴正开发最新AI产品“秒悟Meoo”,官方介绍指出:秒悟 Meoo 是一款革命性的云端 AI 开发工具。它就像一个“会编程、懂设计、自部署的全能 AI 伙伴”。秒悟Meoo生成的项目支持可视化页面编辑和多人在线协作编辑两项高级功能。

先迈出一步再说

