



哈佛新研究:过度使用AI会“烧脑”,14%用户出现认知过载
哈佛新研究:过度使用AI会“烧脑”,14%用户出现认知过载不知道有没有人和我一样啊,最近养🦞,养得心好累……
来自主题:
AI资讯
6469 点击 2026-03-17 10:12
不知道有没有人和我一样啊,最近养🦞,养得心好累……

太燃了!老黄GTC再次掏出核弹,新一代Vera Rubin炸场,七颗芯片首次合体,推理性能狂飙35倍。最重磅的是,英伟达版「龙虾」NemoClaw终于现身。

上周,我和一位在北京某大厂做工程师的朋友吃了顿饭,饭桌上他震惊了我 3 次。
周末刚过,Meta 的 1.6 万名员工可能需要重新找工作了。

前Anthropic 研究人员正为一家新创公司洽谈以 10 亿美元估值融资 1.75 亿美元。据知情人士透露,该公司旨在为生物学和材料科学等科研领域开展人工智能驱动的研发工作。
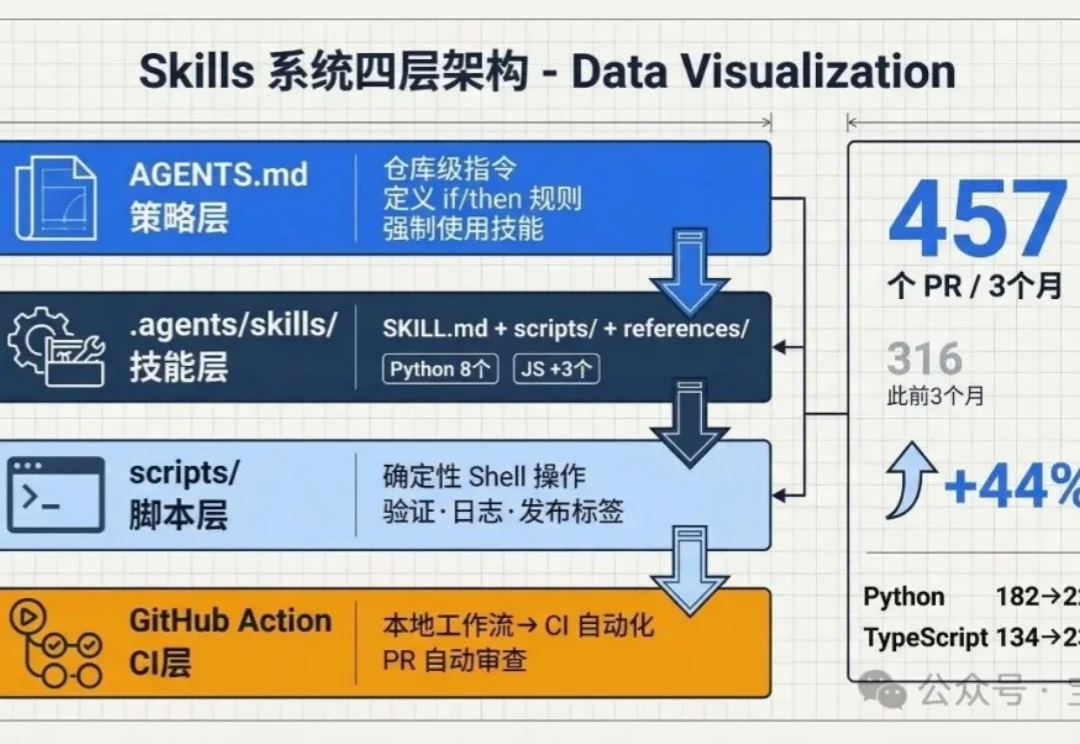
我们用 Codex 改变了维护 OpenAI Agents SDK[1] 仓库的方式。仓库本地的技能(skills)、AGENTS.md 文件和 GitHub Actions,让我们把反复出现的工程工作——验证、发布准备、示例集成测试、PR 审查,变成了可重复执行的工作流。
所以今天我就去闲鱼上找了找,看看有没有更便宜一点、能继续顶上来的方案,最后顺手买了一个 9.9 元的 bussiness 拼车。买完之后,我就顺手把它折腾了一下,最终成功接到了 Claude Code 里面。

终于,“养虾人”们也有自己的专属模型了。

随着龙虾OpenClaw热潮持续,复杂的云端部署已经无法满足用户的需求,尤其是最近两周,涌现出了大量在原OpenClaw基础上定制的新产品,其中很多已经实现了应用化,用户只需要点击下载注册应用就能够体验OpenClaw的部分功能。
这是自我实现的过程,这是 “无限游戏”。

AI竞赛,已经踩下油门,开始全力冲刺!2026下半年,三巨头OpenAI、谷歌DeepMind、Anthropic将甩开所有人,递归自我改进的引擎已点火。接下来六个月,人类文明或将永久改写。
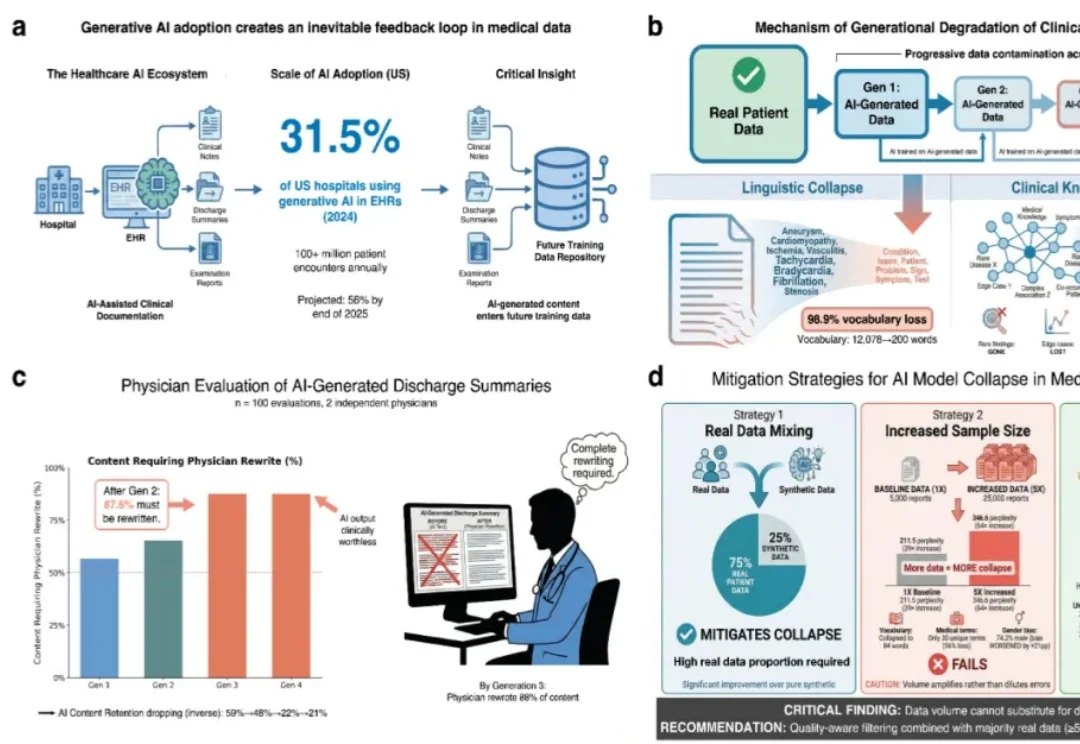
随着生成式人工智能在医疗领域的加速渗透,越来越多的病历、影像报告及各类临床文本正逐步纳入 AI 参与生成的范畴。这一旨在提升医疗效率的技术革新背后,潜藏着威胁诊断安全性的深层隐患。
当AI的生成能力逐渐成为标配时,设计AI的竞争核心已不再是谁更会出图,而是谁能真正接管设计师从创意沟通到商业落地的完整工作流,将设计、协同与产业生态整合成一个无缝的系统。这预示着一场范式转移,而最近发布的暗壳AI Agent2.0,或将成为万亿人居产业的生态破局者。
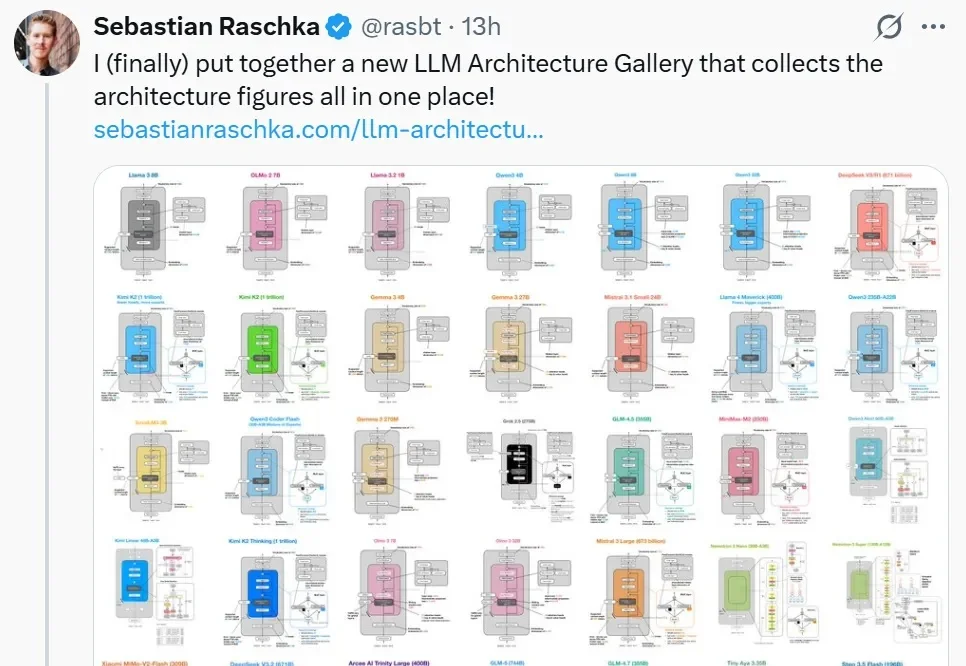
最近几年,大模型赛道好不热闹。

七天时间,从神坛到凡间,从泡沫到实用。

朋友们,你们是不是也这样: 遇到问题,打开ChatGPT,噼里啪啦打一堆提示词,它给你生成一段代码、一个方案,然后呢?
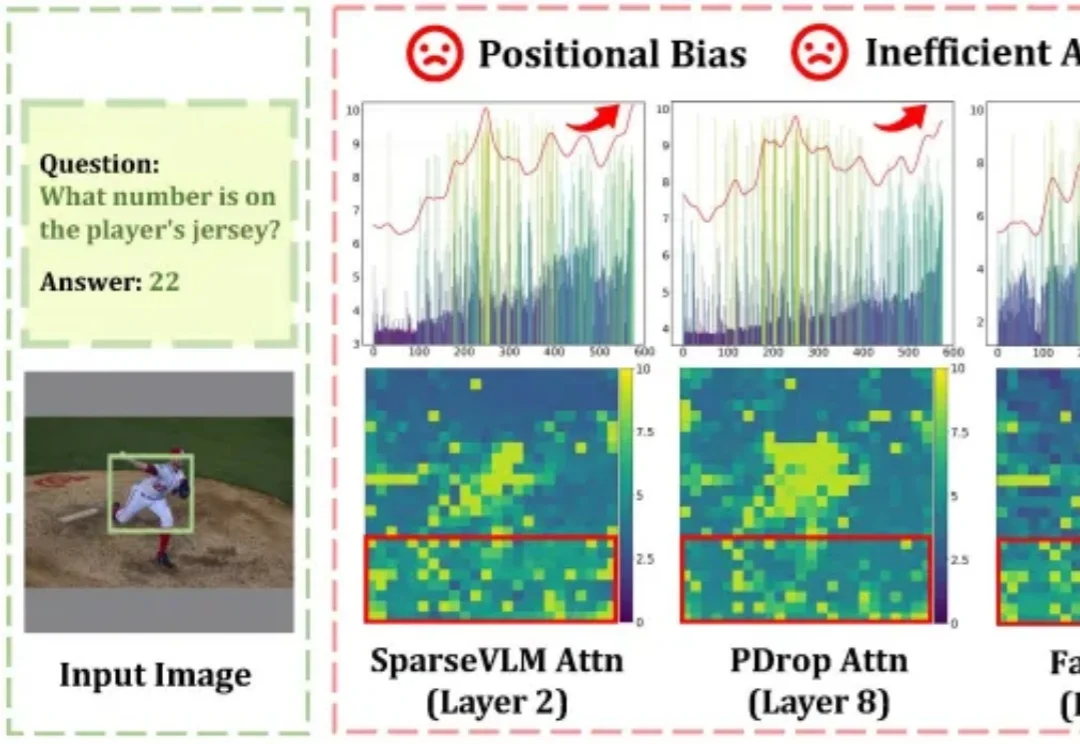
随着高分辨率图像理解与长视频处理需求的爆发式增长,大型视觉语言模型(LVLMs)所需处理的视觉 Token 数量急剧膨胀,推理效率成为落地部署的核心瓶颈。Token 压缩是缩短序列、提升吞吐的直接手段,但现有方法普遍依赖注意力权重来判断 Token 重要性,这一路线暗藏两个致命缺陷:
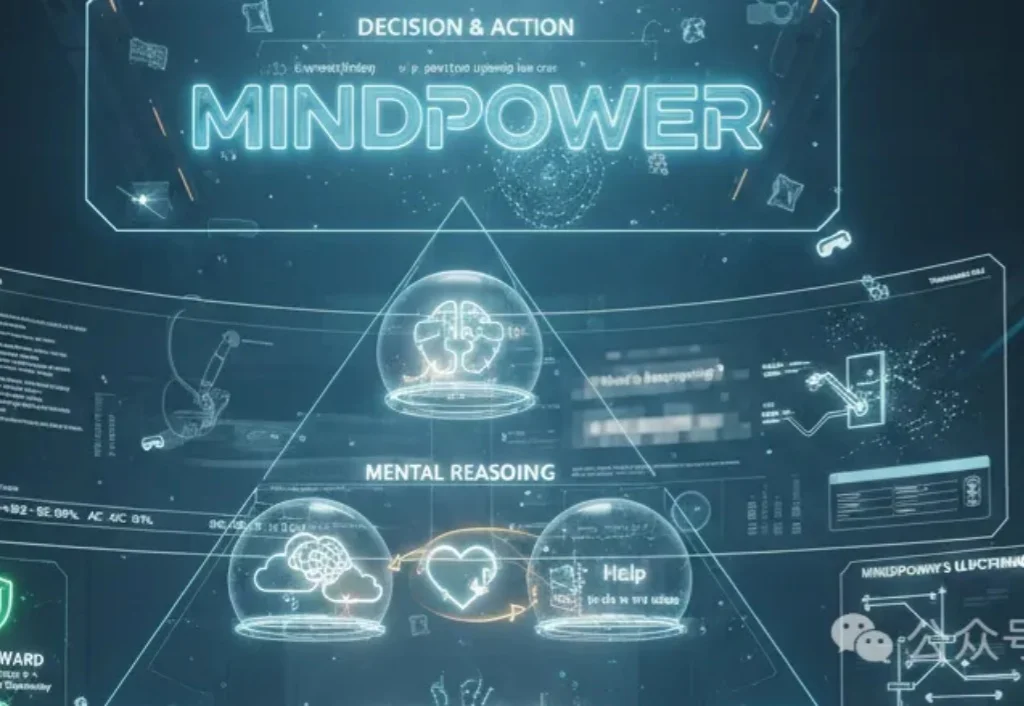
吉林大学&微软亚洲研究院等团队提出MindPower框架,让机器人像人一样理解他人想法并主动帮忙,构建了首个以机器人为中心的心智推理评测体系,通过六层推理链条,让AI不仅看懂场景,更能推断意图、做出决策、执行动作,显著提升助人能力。
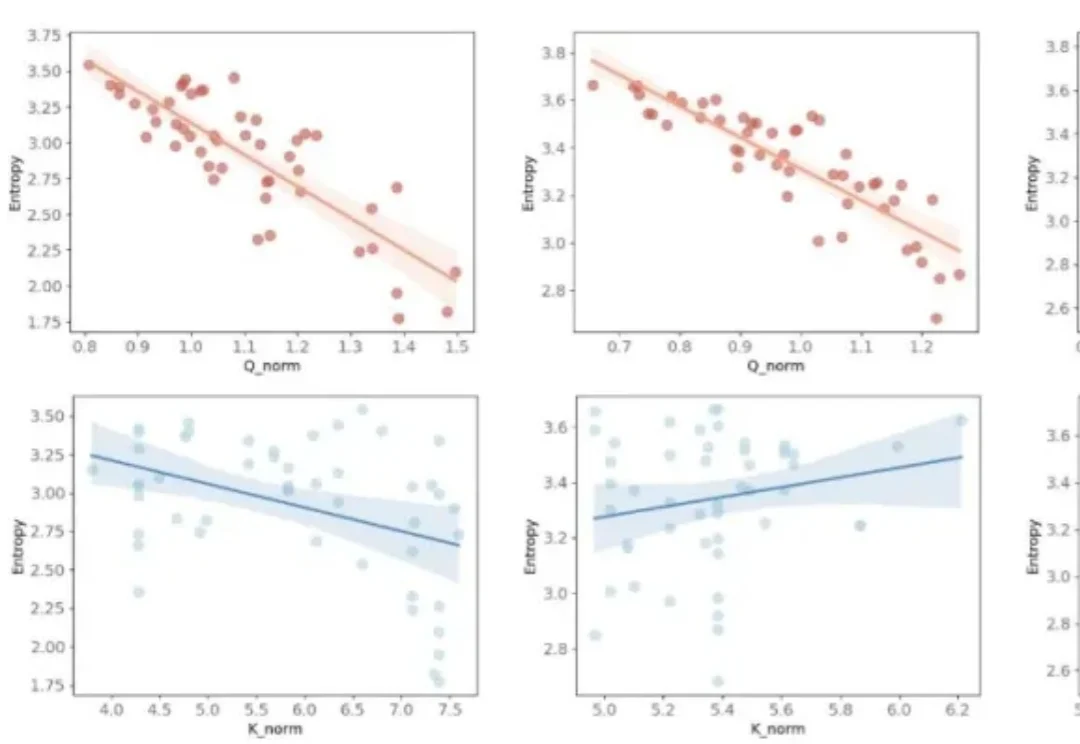
当 Transformer 席卷计算机视觉领域,高分辨率图像、超长序列任务带来的算力与显存瓶颈愈发凸显:标准 Softmax 注意力的二次复杂度,让 70K+token 的超分辨率任务直接显存爆炸,高分辨率图像分割、检测的推理延迟居高不下。
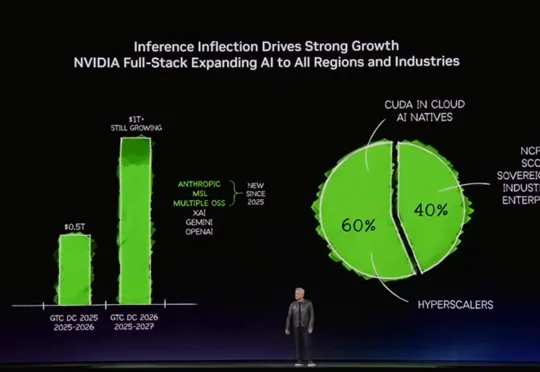
老黄:科技公司的算力焦虑,有 1 万亿刀那么大。北京时间今天凌晨两点,英伟达 GTC 大会在加州圣何塞正式召开,这回的 Keynote 注定要被各大公司 CEO 不断引用了。

3月16日阿里内部围绕“Token”链路,重新梳理整合了业务架构,并成立了新事业群:Alibaba Token Hub(ATH)事业群,阿里巴巴CEO吴泳铭将直接负责这个事业群。这也是自阿里内部电商事业群整合以来,最重要的一次架构调整。

投资界获悉,月之暗面Kimi正以投前估值180亿美元(约合人民币1200亿),进行新一轮10亿美元融资。大约一个月前,Kimi刚刚完成逾7亿美元融资,彼时估值100亿美元;而在去年底一轮5亿美元融资中,其估值还只是43亿美元。

今天上午,AI Agent创企MuleRun(骡子快跑)团队发布MuleRun 2.0,该产品是一个可自我进化的个人AI Agent助手。Mulerun创始人兼CEO陈宇森分享称,MuleRun的上手门槛更低,可以在给定目标的前提下主动工作,具有0门槛使用、极高安全性、稳定性、售后完善、自进化能力、24小时在线、主动性等优势。

就在刚刚,Moonshot AI(月之暗面)发布了一项足以撼动 Transformer 底层的研究:《Attention Residuals》。海外科技大 V,谷歌高级AI产品经理 Shubham Saboo 直接开启了“高赞”模式:“他们触碰了那个十年没人敢碰的部分。”

一睁眼!陈天桥带队的大模型黑马MiroMind再度满血归来—— 正式发布新一代重型推理智能体:MiroThinker-1.7和MiroThinker-H1。

中国教育界的OpenClaw来了!刚刚,清华教育学院、计算机系联合团队正式开源多智能体AI课堂OpenMAIC:AI老师语音授课,AI同学举手讨论,交互式课程一键生成。

最近AI圈又多了一张硬核通行证,Anthropic刚刚在官网发布了Claude首个AI架构师认证。

多模态模型代码写得像老司机,却在数手指、量柱子时频频翻车?UniPat AI用五百行代码打造的SWE-Vision,让模型「掏出Python尺子」自我验证,一举拿下五大视觉相关基准SOTA。

半年前我对MuleRun的结论是,阿里老哥拿出了看家的电商心法,要做AI淘宝,供给侧改革,思路典中典。那篇文章最后一句话是等大来——你去喝两瓶假酒一觉睡到明年什么都没错过。

黑暗启蒙运动在硅谷的标志性人物——彼得·蒂尔,将于这几天在罗马开展一系列绝密讲座,驳斥教皇观点,反对 AI 监管,这或许标志着 AI 竞争的终局较量已经拉开帷幕。各大巨头想要争夺的标的,已经超越了算力规模与爆款应用。他们真正在抢夺的,是对「未来秩序」的最终解释权。

