Replit 怒锤“欧洲版 Cursor”:造出百款“高危”应用,普通开发者一小时内黑入,氛围编码成了黑客“天堂”?
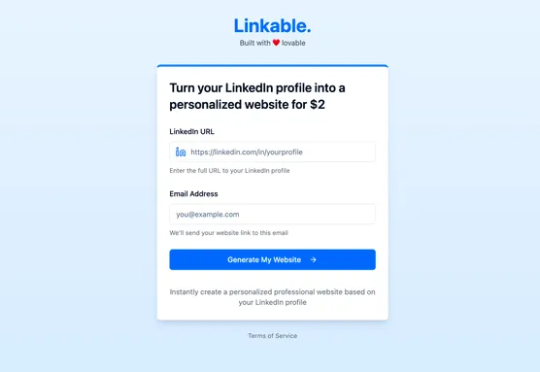
Replit 怒锤“欧洲版 Cursor”:造出百款“高危”应用,普通开发者一小时内黑入,氛围编码成了黑客“天堂”?据撰写这份报告的 AI 编程助手厂商 Replit 员工 Matt Palmer 称,他和一位同事扫描了 Lovable 网站上 1645 款由其开发的 Web 应用程序。经过审查核实,其中 170 款应用程序允许任何人访问网站的用户信息,包括姓名、电子邮件地址、财务信息以及 AI 服务的 API 密钥。
来自主题:
AI资讯
9815 点击 2025-06-01 22:03