


仅需一个混频器的无线射频机器学习推理,登上Science Advances!
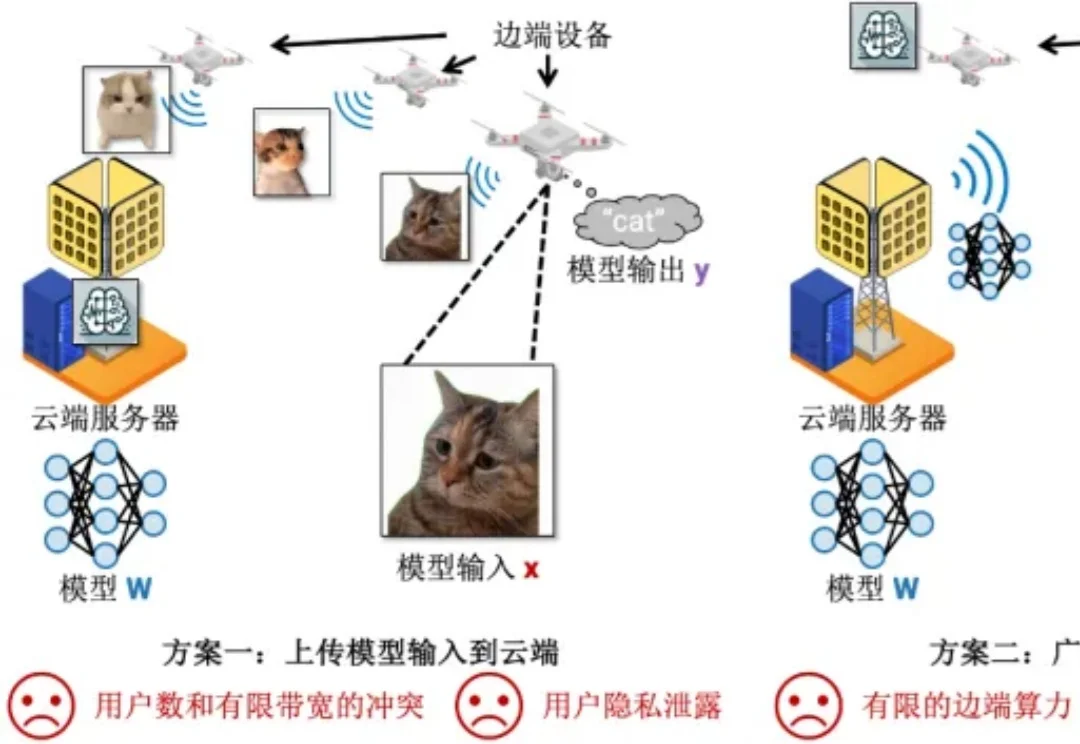
仅需一个混频器的无线射频机器学习推理,登上Science Advances!机器学习部署在边端设备的时候,模型总是存储在云端服务器上(5G 基站),而模型输入输出总是在边端设备上(例如用照相机拍摄照片然后识别其中的目标)。在这种场景下,传统有以下两种方案完成机器学习的推理:
来自主题:
AI技术研报
10009 点击 2026-01-16 10:01
机器学习部署在边端设备的时候,模型总是存储在云端服务器上(5G 基站),而模型输入输出总是在边端设备上(例如用照相机拍摄照片然后识别其中的目标)。在这种场景下,传统有以下两种方案完成机器学习的推理:
新年第一天,DeepSeek 发布了一篇艰深晦涩的技术论文,不少网友直呼「看不懂」。

在 Claude 推出 Cowork 功能后,一个明显的信号 —— Agent 不仅仅是辅助工具,而是一种可以被设计、被组织、被反复调用的协作单元。
今天,OpenAI在ChatGPT网页端悄悄推出了独立的翻译功能——ChatGPT Translate。乍一看,它与谷歌翻译等传统翻译工具颇为类似。真正将二者区分开来的,可能是翻译后ChatGPT Translate提供的交互与个性化调整能力。
谷歌正式发布了由最新Gemini3模型驱动的“Personal Intelligence”功能。它将谷歌旗下四大应用的数据池进行了底层连接,让AI获得了跨应用权限。
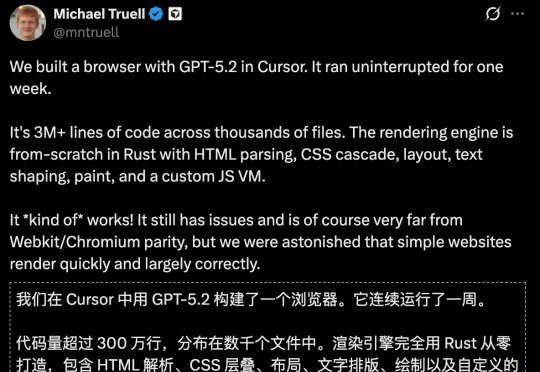
Michael Truell让Cursor中的GPT-5.2连续运行了整整一周。不是一小时,不是一天,而是不眠不休,昼夜不停,168小时持续写代码。结果?300万行代码。数千个文件。

1 月 15 日上午,千问又前进了一大步,已经准备让智能体全面接管我们的日常生活了。千问 App 上线了全新 AI Agent 能力「任务助理」,同时全面打通阿里生态,一次开启了 400 多项新功能,邀请测试与灰度上线已经同步开启,全都是免费可用的。

据《智能涌现》独家获悉,Noumena近期获得数千万人民币Pre-A轮融资,投资方包括狮城资本、百度战投以及老股东靖亚资本。Noumena的三位联合创始人,Jett曾任小红书KA行业群总经理,另外两位联合创始人,均是历经第四范式商业与工业化历练的科学家

最近,一篇由中国团队领衔全球24所TOP高校机构发布,用于评测LLMs for Science能力高低的论文,在外网炸了!当晚,Keras (最高效易用的深度学习框架之一)缔造者François Chollet转发论文链接,并喊出:「我们迫切需要新思路来推动人工智能走向科学创新。」

估值 120 亿美元的明星 AI 公司,创业没几年就把首任 CTO 给开了。就在刚刚,前 OpenAI CTO、Thinking Machines Lab 创始人 Mira Murati 在社交媒体上发了条措辞相当严厉的声明:

去年下半年,B2、B3两轮融资的钱还没捂热,这不,就在刚刚,新鲜热乎C1轮融资又双叒叕光速到位~行业首个实现双向对话、实时翻译的智能眼镜INMO GO3,首发仅3天,全渠道预订量就突破20000台。

今天,OpenAI与美国AI芯片独角兽Cerebras联合宣布,将部署750兆瓦的Cerebras晶圆级系统,为OpenAI客户提供服务。该合作将于2026年起分阶段落地,并于2028年之前完成,建成后将成为全球规模最大的高速AI推理平台。

最新消息:姚班大神陈立杰,加盟OpenAI了。
上个月你刚花 20 美元订阅了 ChatGPT Plus,转头这个月朋友圈就被「Claude 秒杀一切」刷屏,再过一个月可能又换成「Gemini 吊打一切」。

大家好,我是凤凰编辑部的编辑李周。 蛇年除夕夜,除了春晚朋友圈,大家都在津津乐道一种新东西:AI。

感谢AI!

又有一家 AI 初创公司拿到了融资。

今早,媒体人Kylie Robison在社交平台X上发文称,据两位知情人士消息,由前OpenAI首席技术官Mira Murati共同创立的知名AI创企Thinking Machines Lab已解雇其首席技术官Barret Zoph,因其“不道德行为”。

AI 不再仅仅是操作和交互的对象,它开始成为 Coworker。
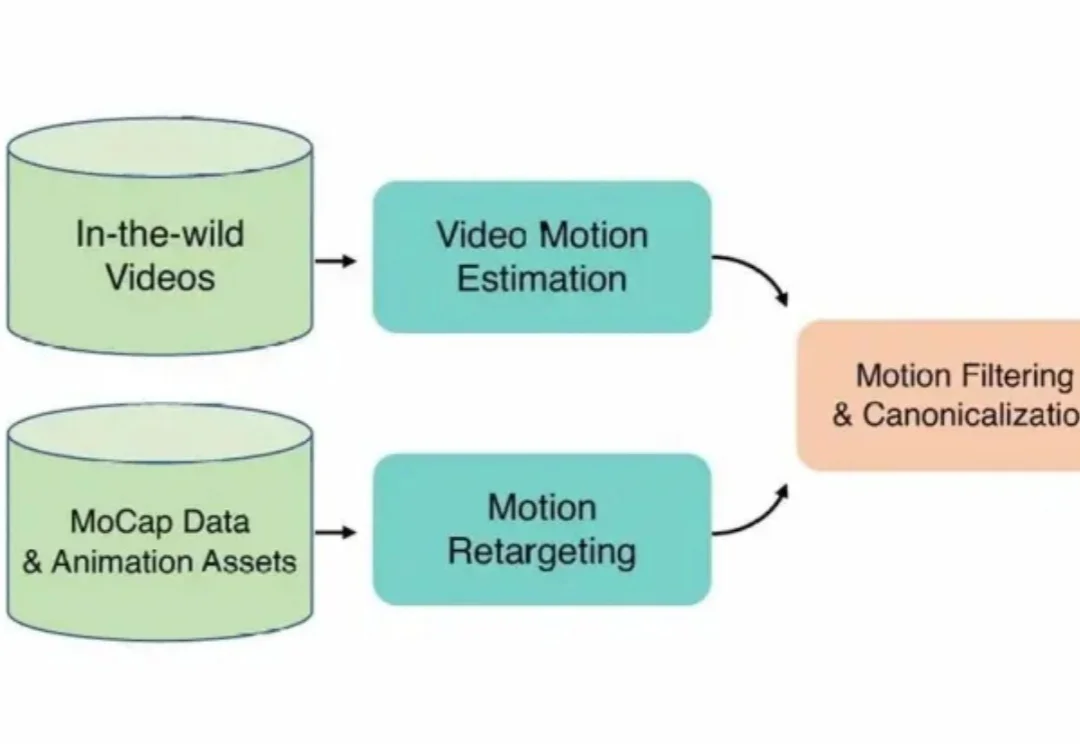
在3D角色动画创作领域,高质量动作资产的匮乏长期制约着产出的上限。

Andrej Karpathy震惊硅谷的推文揭开了编程史上最剧烈的变局,软件工程正在经历一场9级地震。当Linus Torvalds开始用AI写代码,当Rust创始人DHH在网上疯狂安利AI编程,当一个澳洲养羊农民用5行代码逼疯硅谷精英,我们必须直面一个残酷的现实:编程领域的AGI奇点,已经率先抵达。
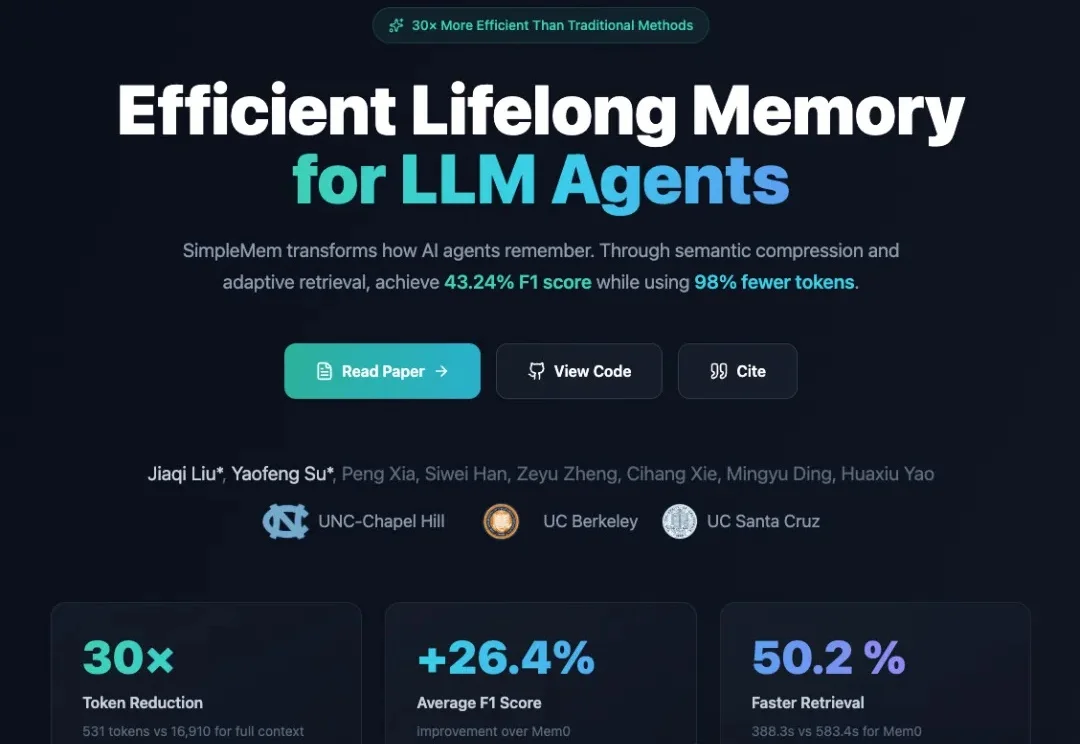
如果人类的大脑像现在的LLM Agent一样工作,记住每一句今天明天的废话,我们在五岁时就会因为内存溢出而宕机。真正的智能,核心不在于“存储”,而在于高效的“遗忘”与“重组”。
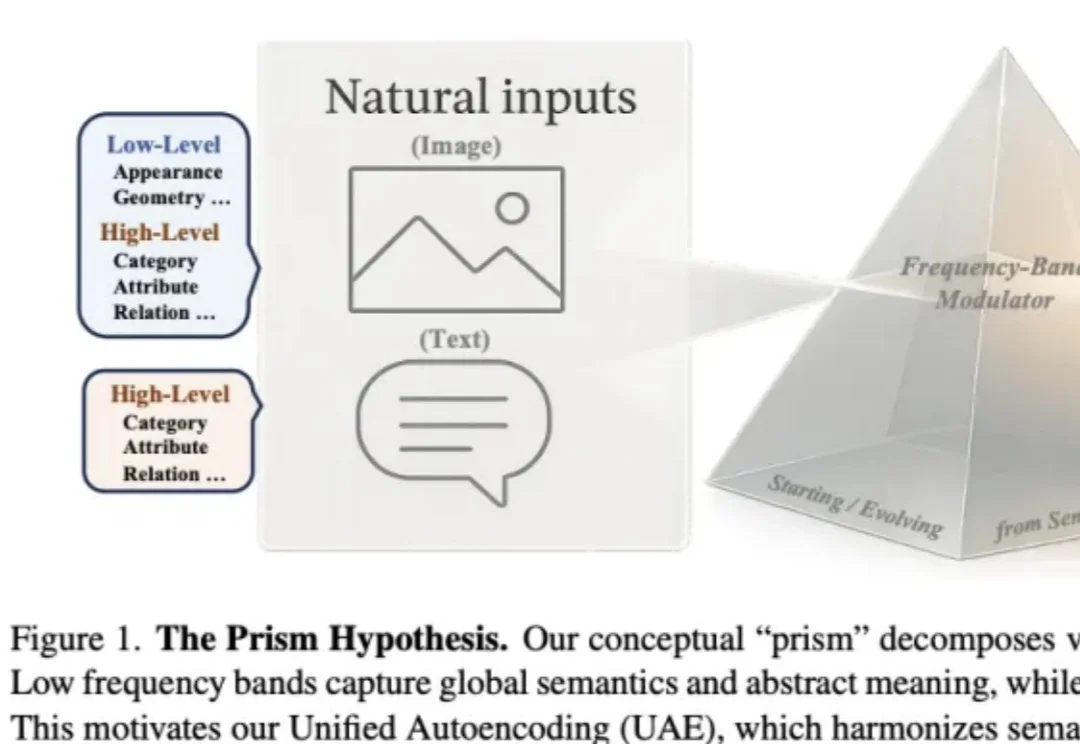
作者来自 Nanyang Technological University(MMLab) 与 SenseTime Research,提出 Prism Hypothesis(棱镜假说) 与 Unified Autoencoding(UAE),尝试用 “频率谱” 的统一视角,把语义编码器与像素编码器的表示冲突真正 “合并解决”。
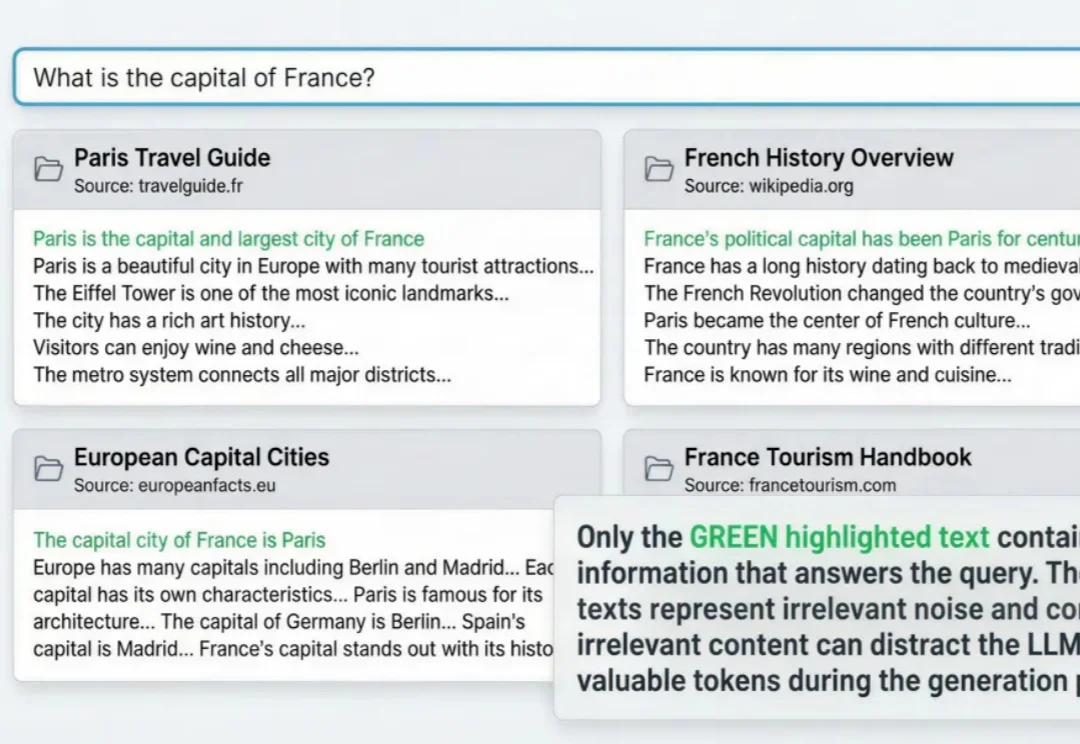
RAG与agent用到深水区,一定会遇到这个问题: 明明架构很完美,私有数据也做了接入,但项目上线三天,不但token账单爆了,模型输出结果也似乎总差点意思。
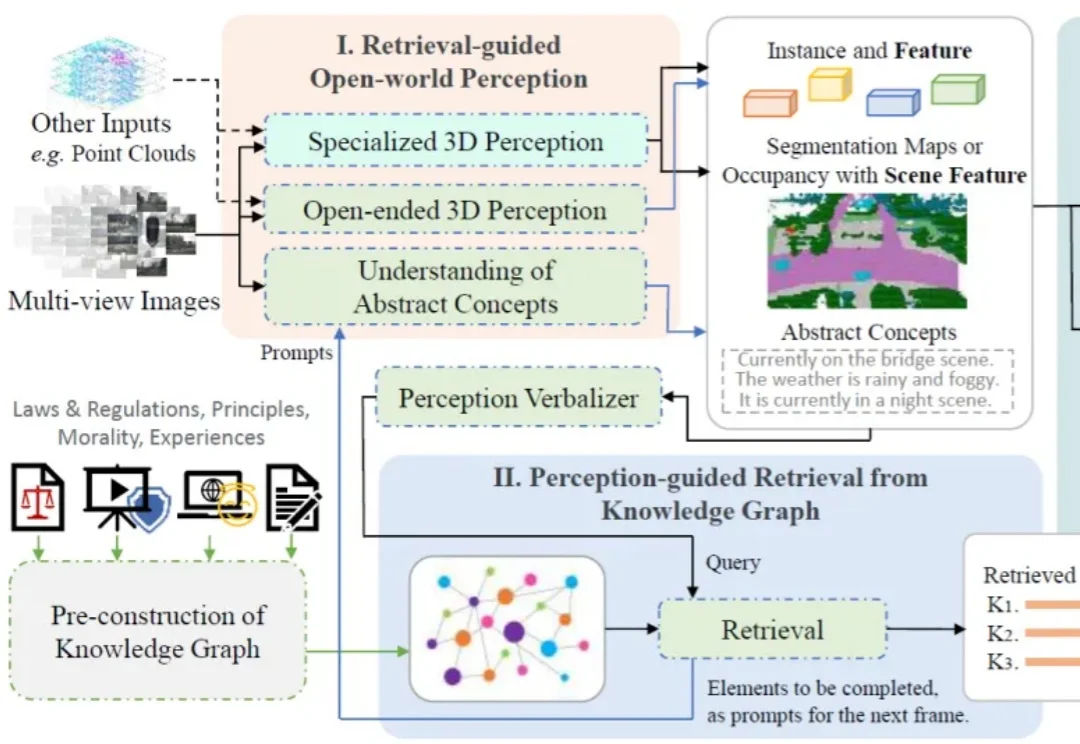
一个智能驾驶系统,在迈向高阶自动驾驶的过程中,应当具备何种能力?除了基础的感知、预测、规划、决策能力,如何对三维空间进行更深入的理解?如何具备包含法律法规、道德原则、防御性驾驶原则等知识?如何进行基本的视觉 - 语言推理?如何让智能系统具备世界观和价值观?
美国当地时间1月13日,语音AI公司Deepgram宣布完成1.3亿美元C轮融资。此轮融资后,公司总融资额达到2.15亿美元,估值13亿美元,成为了这一赛道的新晋独角兽。

最近,一个澳大利亚的养羊大叔用5行代码捅破AI编程天花板的故事,彻底火出圈了。2025年底,在铲羊粪的间隙,Geoffrey Huntley写出了下面这个仅含5行代码的Bash脚本while :; do cat PROMPT.md | claude-code ; done

今天,谷歌Veo 3.1终于迎来重磅升级,表现力直接爆表! 这一次,谷歌特别优化了移动端体验。只需上传一些「素材图片」(ingredient images),就能轻松创作出更有趣、更有创意、画质极佳的视频。

今天,OpenAI 宣布收购 Torch,一家成立刚满一年的医疗数据整合应用
2026 年刚开年,独立开发者圈子就炸锅了。

