


年入103万美元!AI 独立开发者天花板!普通人应如何实践?
年入103万美元!AI 独立开发者天花板!普通人应如何实践?2026 年刚开年,独立开发者圈子就炸锅了。
来自主题:
AI技术研报
10601 点击 2026-01-14 17:04
2026 年刚开年,独立开发者圈子就炸锅了。

一个背景深厚的新玩家强势入局。

近期,一款海外 AI 产品 AnyGen,在用户中悄然走红。它的名字开始出现在不少科技爱好者的社交动态里。有人贴出用它做的市场分析报告,有人推荐用它快速生成 PPT。

还记得那个穿着「Lululemon」紧身衣、主打温柔陪伴的家用人形机器人 NEO 吗?
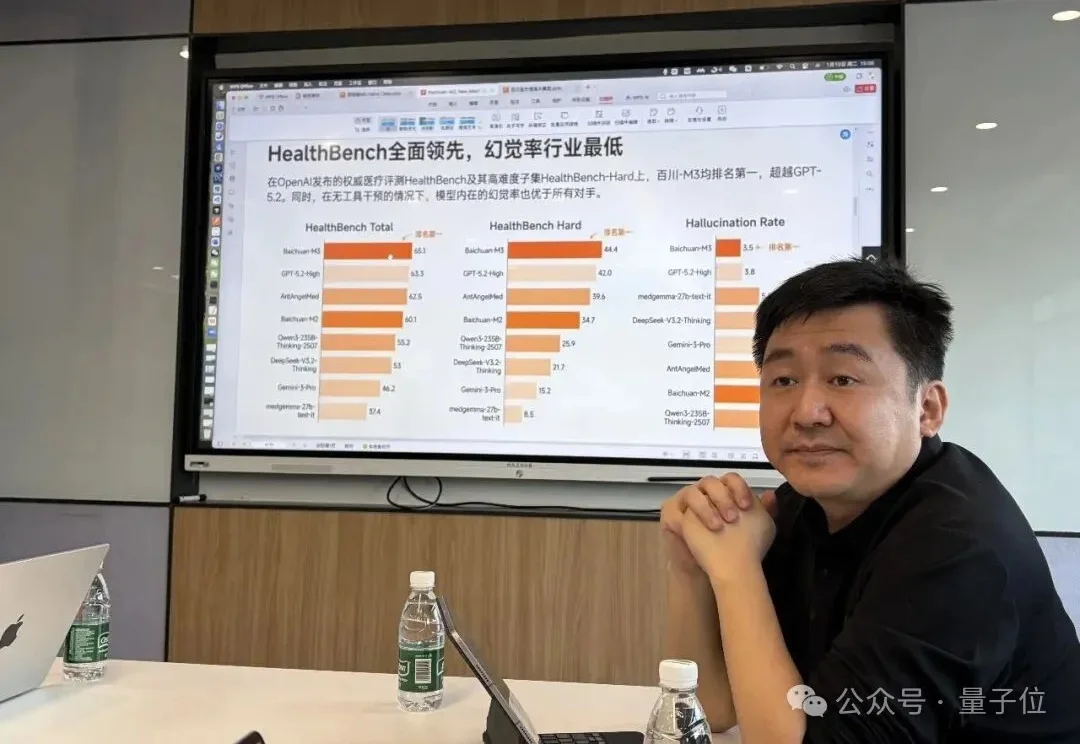
“我们没有能力一会儿金融、一会儿娱乐、一会儿医疗,只能深耕一条主线。”

2019年,乔布斯「灵魂伴侣」Jony Ive离开了他工作了27年的苹果。2026年,他带着一款「蛋石」形状的AI设备回归。这一次,他的合作伙伴不再是库比蒂诺的苹果,而是旧金山的OpenAI。
“AI Infra 就是云计算本身。”
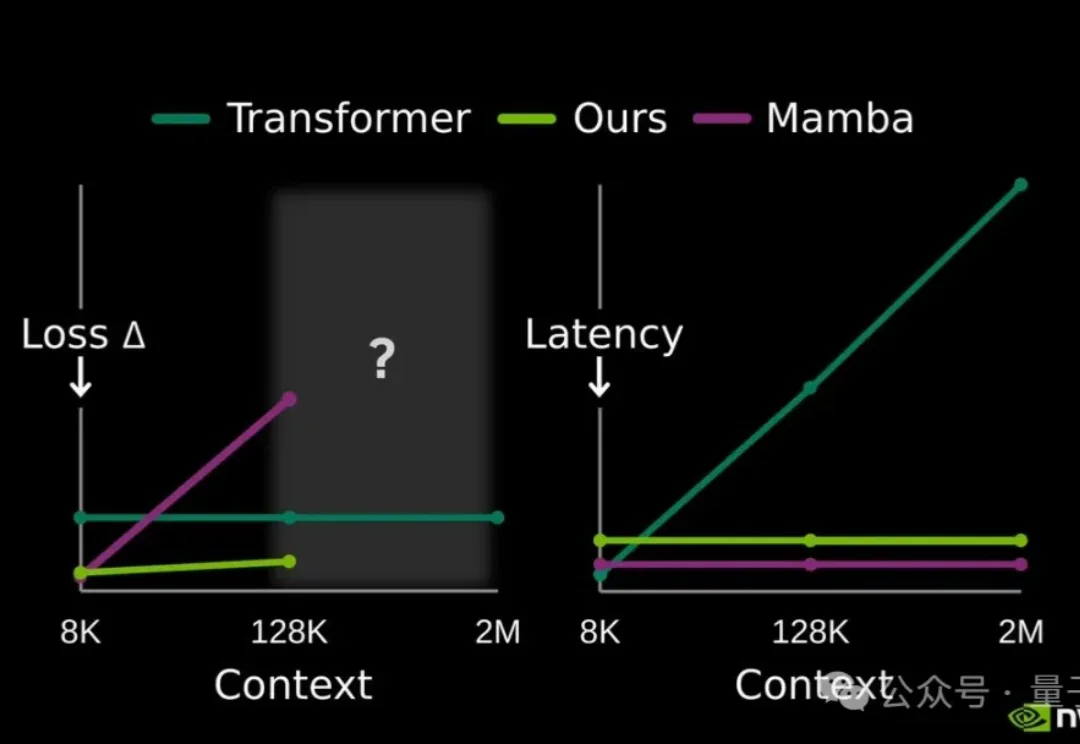
提高大模型记忆这块儿,美国大模型开源王者——英伟达也出招了。
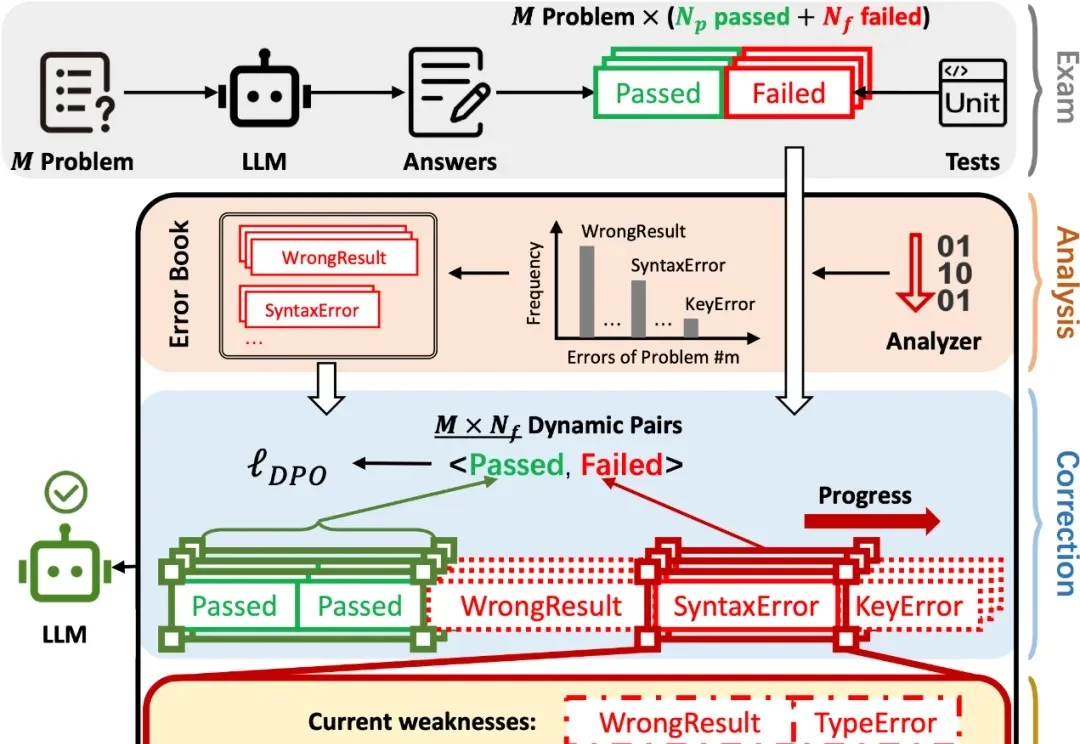
在 AI 辅助 Coding 技术快速发展的背景下,大语言模型(LLMs)虽显著提升了软件开发效率,但开源的 LLMs 生成的代码依旧存在运行时错误,增加了开发者调试成本。

“消费属性比 AI 更重要”。
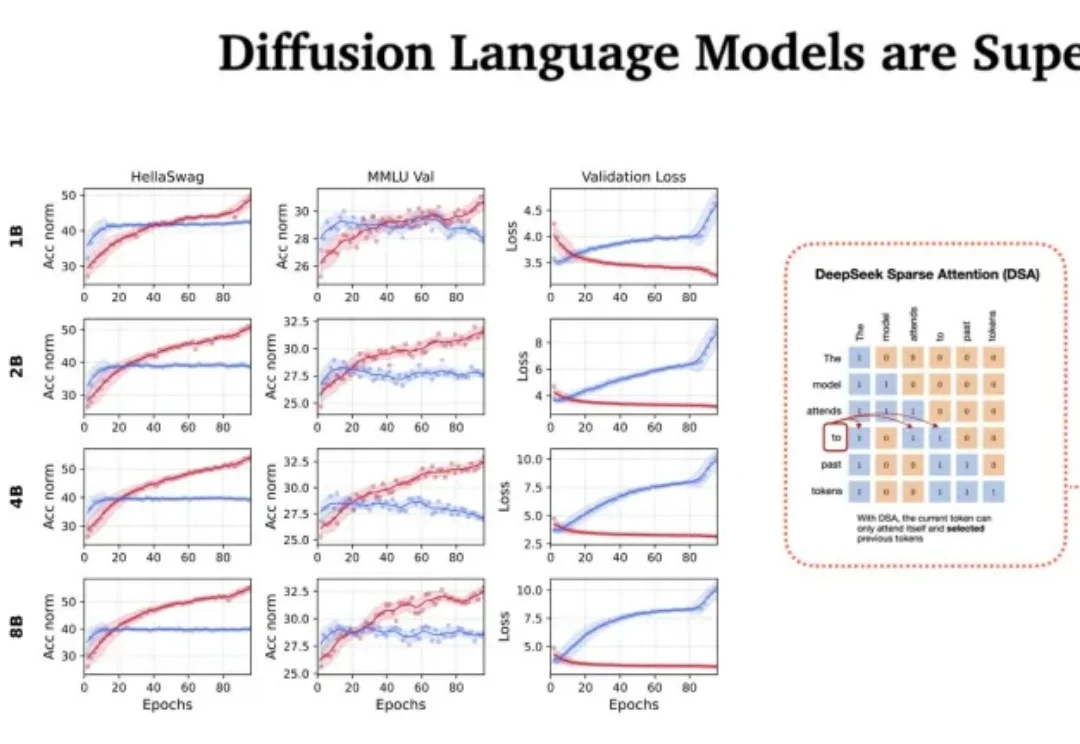
站在 2026 年的开端回望,LLM 的架构之争似乎进入了一个新的微妙阶段。过去几年,Transformer 架构以绝对的统治力横扫了人工智能领域,但随着算力成本的博弈和对推理效率的极致追求,挑战者们从未停止过脚步。

无论你是否身处AI行业,近期总能频繁刷到关于中国AI新物种的新闻。在美国拉斯维加斯会展中心举办的CES大会上,来自中国的AI产品遍布各个展馆,成为全场关注的焦点,这也恰如其分地印证了2025年中国AI应用落地的蓬勃发展态势。
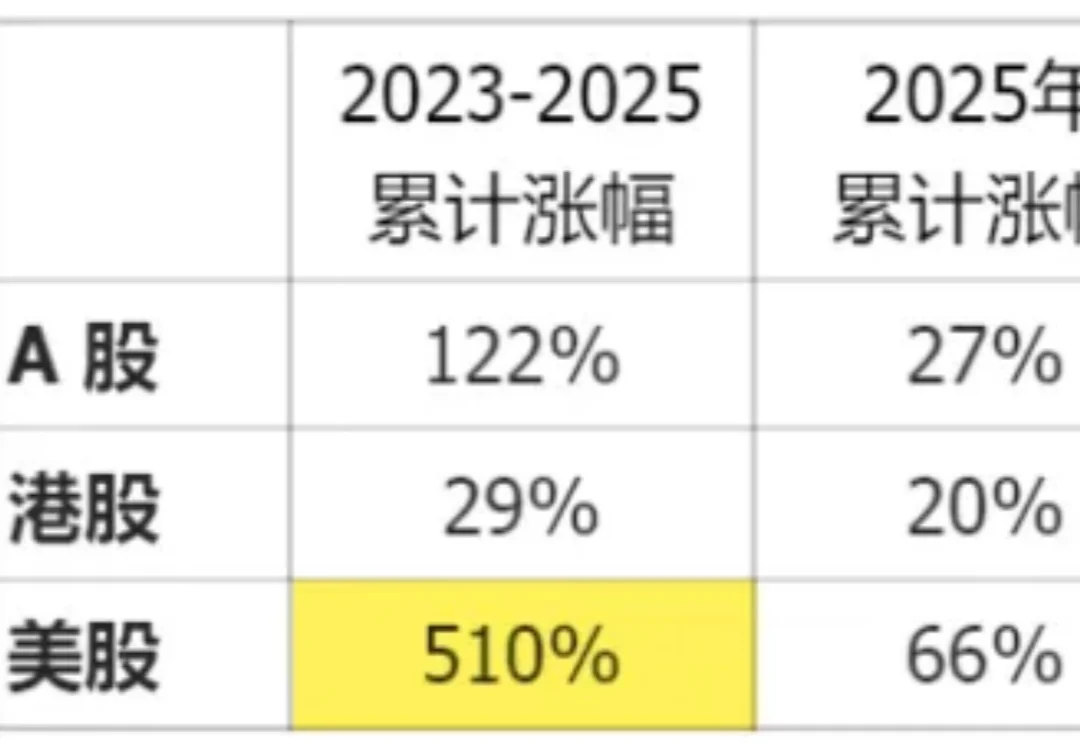
我结合AI做了一次A股、美股、港股所有AI概念公司的分析总结,践行“用AI扫描AI板块”。今天分享一部分内容:股价涨幅、估值水平、盈利能力、三个市场投资人有哪些共识点。
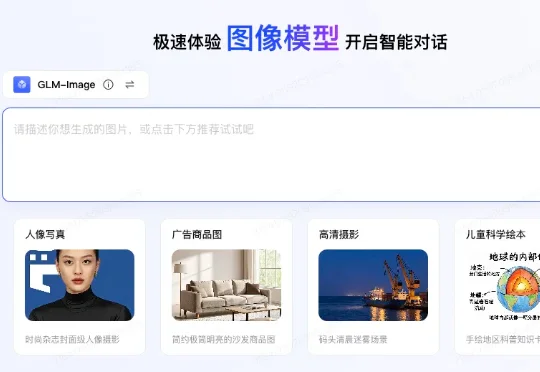
今天,首个在国产芯片上完成全程训练的SOTA(最佳水平)多模态模型开源。这是智谱联合华为开源的图像生成模型GLM-Image。从数据到训练的全流程,该模型完全基于昇腾Atlas 800T A2设备和昇思MindSpore AI框架完成构建。
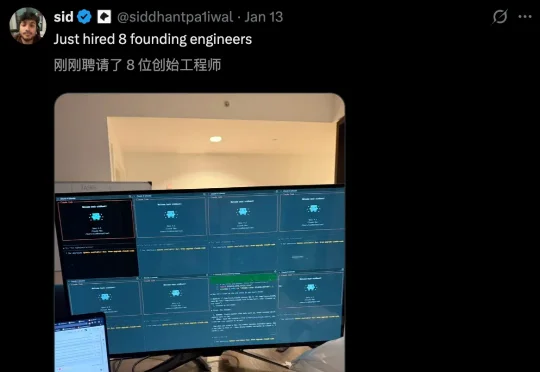
Claude Cowork的横空出世,不仅是用10天自建系统的技术奇迹,更是对人类职业价值的一次残酷拷问:当AI两小时能干完两个月的工作,我们是该庆幸解放,还是该恐惧被替代?
今日,深圳AI初创公司DeepWisdom正式完成A轮及A+轮融资,累计金额达3100万美元(约合人民币2.1亿元)。据公开信息,DeepWisdom的累计融资规模位居国内同领域第一。

DeepWisdom 旗下产品 MetaGPT(现更名为Atoms)今年2月上线后,以0成本推广首月狂揽百万美元 ARR,全球注册用户迅速超过五十万,连续四周霸榜 Product Hunt 全球榜首。
如果说 2024 年我们还在惊叹于 AI 能写代码、能画图,那么 2025 年的关键词一定是:Agent(智能体)。

今天DeepSeek又发表了一篇论文,让AI解读,仔细读完,觉得很牛逼。
昨晚夜里快12点,AI视频公司PixVerse毫无预兆的发了一个项目。PixVerse R1,下一代实时世界生成模型。这玩意你看文字,可能不是很好理解,我直接放一个官方的demo视频,大家的感觉应该会强一些。
干爆整个韩服 LOL,让中韩两国网友误以为是 AI 的乌龙事件。

从ChatGPT爆火以后,就总有“AI太牛了,自己是不是要失业了”等等类似的声音出现。

电商玩法变了。

2025 年 9 月,The Information 报道 Anthropic 曾讨论在接下来一年内投入超过 10 亿美元用于 RL 环境建设。Epoch AI 最近发了一篇报告,采访了 18 位来自 RL 环境初创公司、neolab(Cursor 这类应用型 AI 公司)和前沿实验室的从业者
来深圳了,天气真舒服。我一边蹬着自行车,一边倍速听完了罗永浩和 Lovart CEO 陈冕的访谈。 这是我听过罗永浩最有信息密度的一期 AI 访谈了。收获特别特别大。 Lovart 是去年我除了 Ch

这两年,电子宠物又火了。
自从开年谷歌首席工程师 Jaana Dogan 公开称赞 Claude Code 后,它就又火了一把。
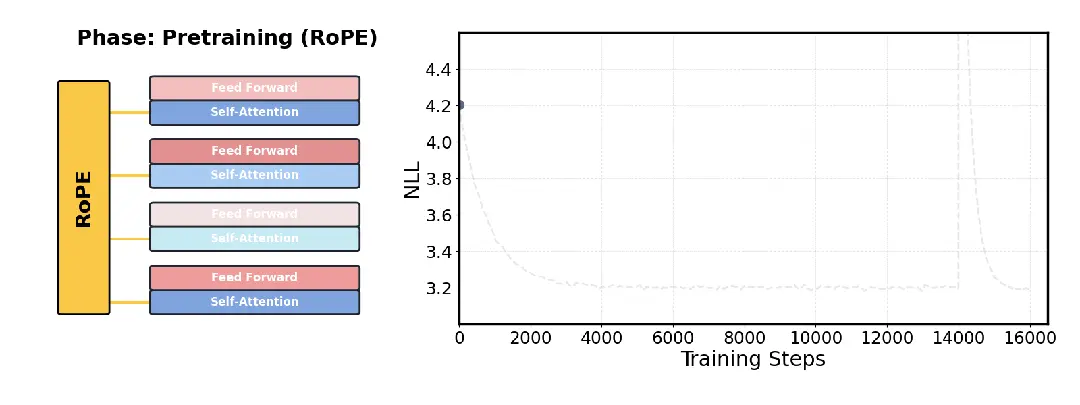
针对大模型长文本处理难题,Transformer架构的核心作者之一Llion Jones领导的研究团队开源了一项新技术DroPE。
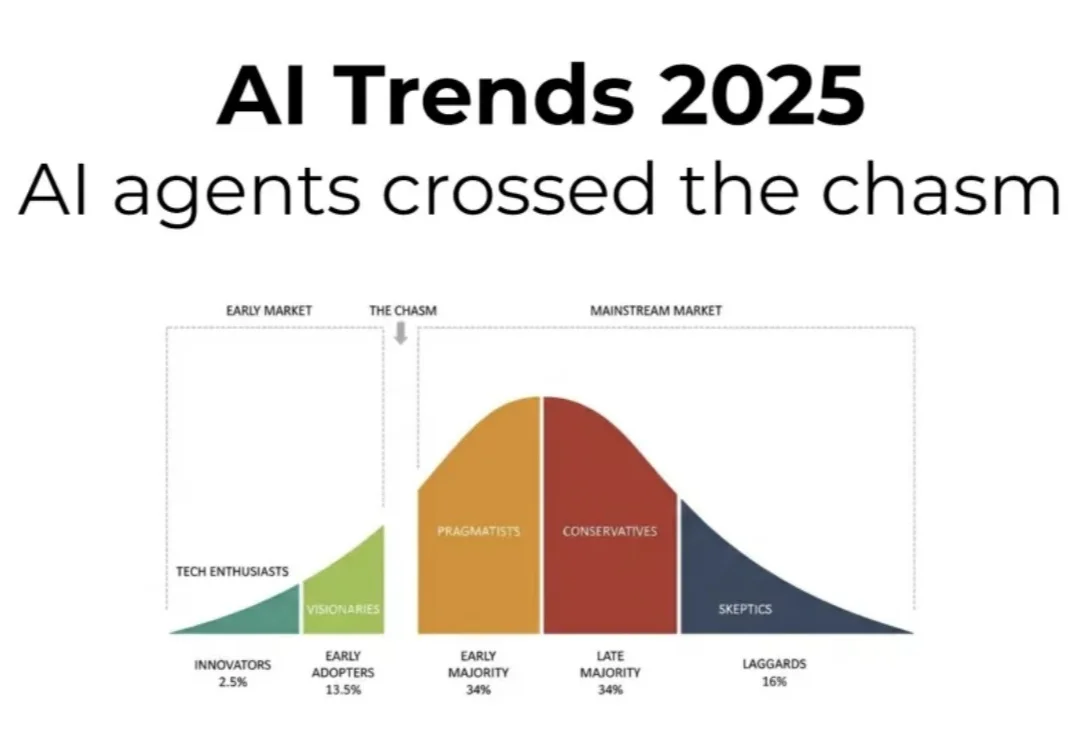
2025 年,AI 智能体“跨过了鸿沟”,开始被更广泛、务实的用户群体采用,不再只是少数发烧友或愿景家在用。

1月7日消息,听力熊Teeni.AI发布了青少年AI随身机器人Mooni Pro重磅新品,搭载多模态AI智能体,让孩子能在对话中探索真实世界,我爱音频网报道。

