



别被室内基准高分骗了:大模型是在推理空间,还是在「背答案」?
别被室内基准高分骗了:大模型是在推理空间,还是在「背答案」?2025 年,随着李飞飞等学者将 “空间智能”(Spatial Intelligence)推向聚光灯下,这一领域迅速成为了大模型竞逐的新高地。通用大模型和各类专家模型纷纷在诸多室内空间推理基准上刷新 SOTA,似乎 AI 在训练中已经更好地读懂了三维空间。
来自主题:
AI技术研报
8808 点击 2026-01-07 09:36
2025 年,随着李飞飞等学者将 “空间智能”(Spatial Intelligence)推向聚光灯下,这一领域迅速成为了大模型竞逐的新高地。通用大模型和各类专家模型纷纷在诸多室内空间推理基准上刷新 SOTA,似乎 AI 在训练中已经更好地读懂了三维空间。

现在搞 AI 创作,最缺的其实不是模型,是耐心…为了做个像样的视频,活生生逼成了搬运工。

CES巨幕上,老黄的PPT已成中国AI的「封神榜」。DeepSeek与Kimi位列C位之时,算力新时代已至。
有没有一款工具,既有 Claude Code 那么强大的能力,又是完全开源免费的,还能让我自由选择用哪家的AI模型?答案是:有的!就是在GitHub上狂揽50.2K Star的新晋开源编程神器:OpenCode。
最近我还真看到一个有点不一样的的 AI 创作比赛,国际奥委会联合阿里云搞了一场「米兰冬奥会 AIGC 全球大赛」,用万相大模型输入一句话,生成 5 到 15 秒冬奥视频即可参赛。不需要专业设备、不需要懂技术、甚至不需要会滑雪,只需要有个脑洞。

英特尔发布年度旗舰AI PC芯片——第三代酷睿Ultra系列处理器(代号Panther Lake)。这是首款基于Intel 18A制程(1.8nm级)的计算平台,将AI PC引入埃米时代,端侧AI算力多达180TOPS。

她是当代人工智能界最具象征意义的女性科学家之一。提到人工智能领域,李飞飞(Fei-Fei Li)无疑是最醒目的那一个。1976年出生的她,早年在美求学,1999年以物理学荣誉学士毕业于普林斯顿大学,随后在加州理工学院获得电气工程博士学位。
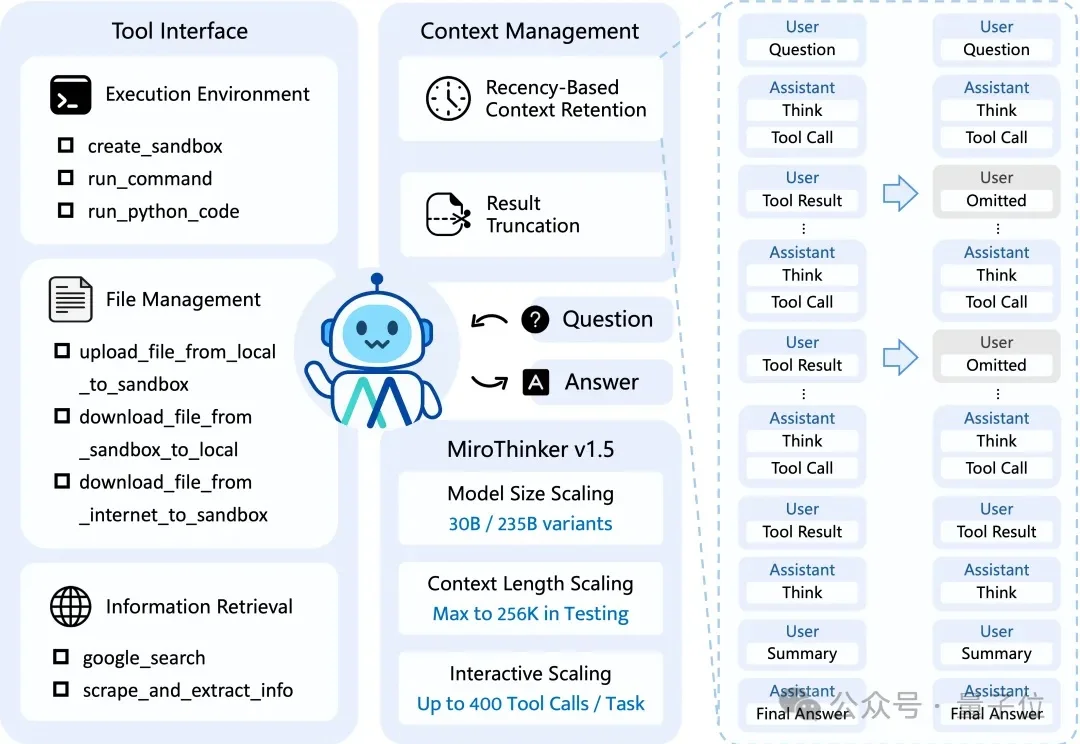
新年刚至,陈天桥携手代季峰率先打响开源大模型的第一枪。

新年第一弹,OpenAI研发副总裁Jerry Tworek官宣离职,这位七年老兵给出的理由让人细思恐极:想做在OpenAI做不了的研究。从Dario Amodei出走创立Anthropic,到Ilya政变后离开,再到安全团队负责人摔门而出——OpenAI的核心大脑们正在以惊人的速度流失。

AMD公布未来两年芯片路线图。

文本领域的大模型满分选手,换成语音就集体挂科?大模型引以为傲的多轮对话逻辑,在真实人声面前竟然如此脆弱。Scale AI正式发布首个原生音频多轮对话基准Audio MultiChallenge,直接撕开了大模型靠合成语音评测维持的优等生假象。实验显示,强如Gemini 3 Pro在真实场景下的通过率也仅过半数,而GPT-4o Audio的表现更是令人大跌眼镜。
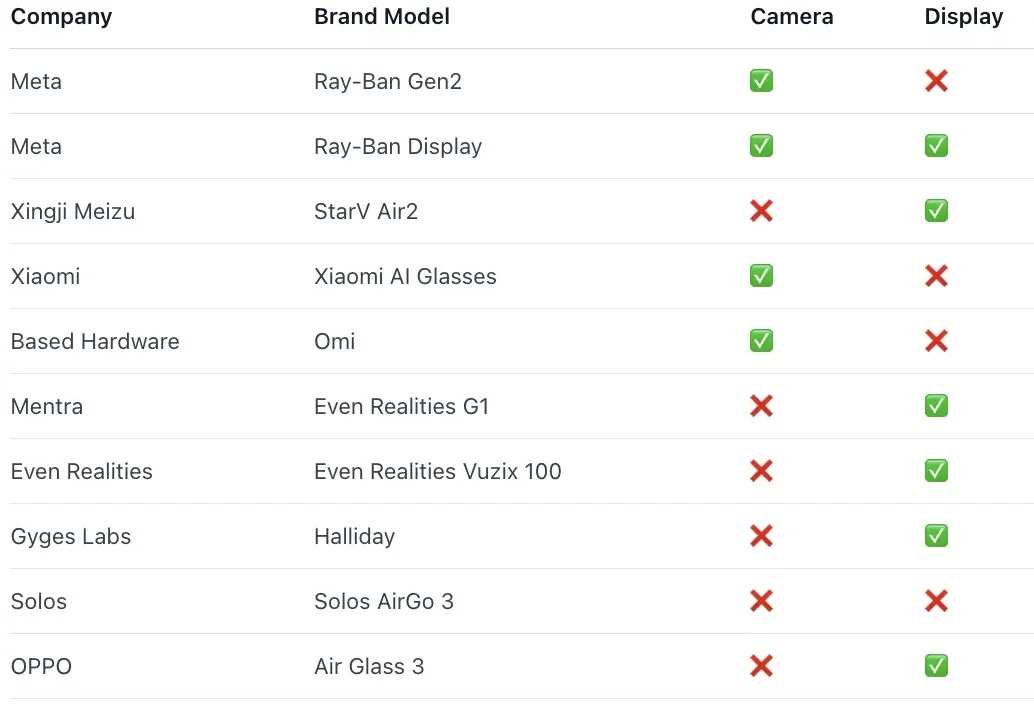
离了大谱了,AI真·走进了大学期末考场,并且还是以作弊者的身份。(你就说震不震惊吧)

专注于异构算力调度和虚拟化的 AI 初创企业上海密瓜智能科技有限公司(“密瓜智能”)已于近期完成数千万元的天使轮融资,本轮融资由复星创富领投,拙朴投资、种子投资人及产业方强力跟投。自去年 3 月获得超五百万元种子轮融资以来,密瓜智能在不足一年时间内已迅速完成 2 轮融资,展现出强劲的发展势能,其技术前景与商业价值备受市场认可。
「我们想解决的不是 『做 AI 工作流』,是『根本不需要有工作流』。所有要求用户『预先构建工作流』的 Agent 都是错的。」在 Agencize AI 产品发布之前,我们和张浩然聊了聊他对于生产力工具和工作流的看法,以及 Agencize AI 的真正竞争力。

您可能已经感受到了,从2025年开始到如今,全世界都在谈论Agentic AI或Agent(代理式AI)。从董事会到咨询公司,从更高级别的战略到街头巷尾,仿佛只要接入了大模型(LLM),所有的业务流程就能自动运转,效率就能翻倍。

一年一度的AAAI Fellow计划又成为了人工智能领域大家关注的焦点。本次发布的2026年名单中,共有12位知名学者当选,其中包含了四位著名华人学者。

BiCo是一种创新的AI视觉内容生成方法,能灵活组合图像和视频中的视觉概念,实现可控编辑。它通过分层绑定器、多样化与吸收机制、时间解耦策略等技术创新,解决了现有方法在概念提取和组合上的问题,让AI真正理解并融合视觉元素。

这两天有点摸鱼,因为我终于把《怪奇物语》第五季给补完了。

在 Anthropic 成立五周年前夕,联合创始人兼总裁 Daniela Amodei 罕见接受了公开采访!

从夯到拉,给AI各环节排序!回顾2025年,科技成为A股的主线。在科技领域中,最亮眼的莫过于AI板块。其中,“易中天”(新易盛、中际旭创、天孚通信)、“纪连海”(寒武纪、工业富联、海光信息)等AI算力板块托起了科技投资的脊梁。而AI应用、AI端侧等涨幅不如AI算力。
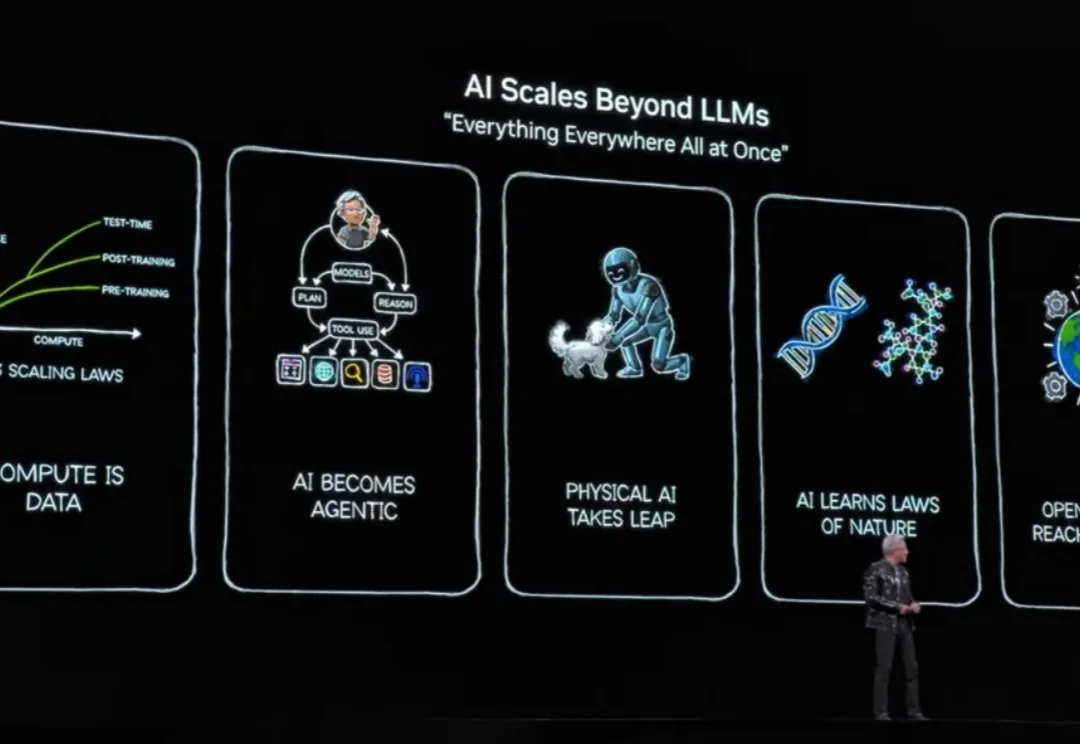
「每隔 10 到 15 年,计算行业就会革新一次,每次都会催生出新形态的平台。现在,有两个转变在同时进行:应用将会构建于 AI 之上,你构建软件的方式也将改变。」

Meta腾出CoWoS排产「让路」,加上台积电的积极扩产,2026年谷歌把TPU的「算力水龙头」拧到最大,预期产能飙升至430万颗,猛攻英伟达CUDA护城河。

近日,X 知名博主、Hyperbolic 联创 & CEO Yuchen Jin 发帖称,如果在他读博士的时候就有 Claude Code、Gemini 和 ChatGPT 等各类 AI 工具出现,那么也许只要一年就能毕业,而不是用了 5.5 年。

医疗健康领域的AI应用迎来「最强大脑」!蚂蚁·安诊儿医疗大模型正式开源,专业能力登顶全球权威榜单。从复杂病例解读到日常健康科普,它能为大众提供专业医生般的解答,也能助力医生更高效精准做临床判断。AI 技术如何让健康守护更简单?快来看看这个最大规模开源医疗模型背后的故事!
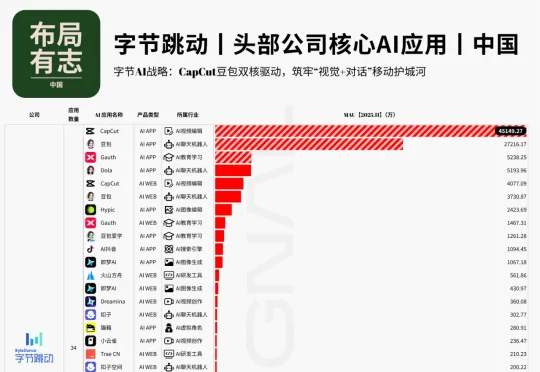
在上一篇《全载录丨Xsignal 全球AI应用行业年度报告丨2025》中,我们俯瞰了全球AI从“震撼期”迈入“深水区”的宏观版图。如果说那是一张新大陆的地图,那么今天,我们将目光聚焦于这场变革的“风暴眼”——中国头部科技公司的战略棋局。

嗨大家好!我是阿真! 本来想刚到2026年一开始就给大家卷个大的,没想到一躺平就完全起不来,于是到了今天才回归,而且发的还是个备用稿哎嘿。

当全行业还在为昂贵的多视角数据焦头烂额时,中科院和CreateAI重磅推出NeoVerse,直接用百万单目视频砸开了4D世界模型的大门,让AI真正学会了理解开放世界。
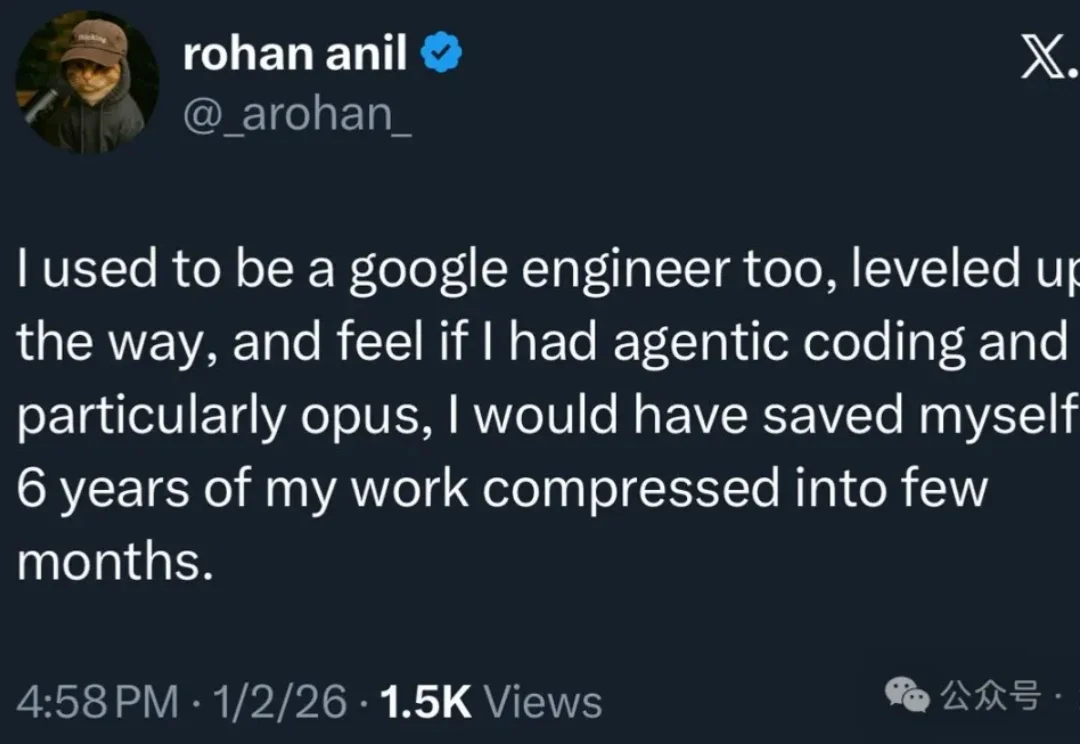
以防你不知道编程Agent现在有多强,硅谷大佬们新年收假回来,纷纷写起了小作文。

关注我比较久的朋友可能都知道,我用 AI 有个习惯。

Plaud 双线布局办公场景,逐步完善产品生态。

