# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
好家伙!1750亿参数的GPT-3只需20MB存储空间了?!
基于1.58-bit训练,在不损失精度的情况下,大幅节省算力(↓97%)和存储(↓90%)。
最近,从事机器学习的Will小哥发了一篇论文,直接引来几十万网友or同行围观。
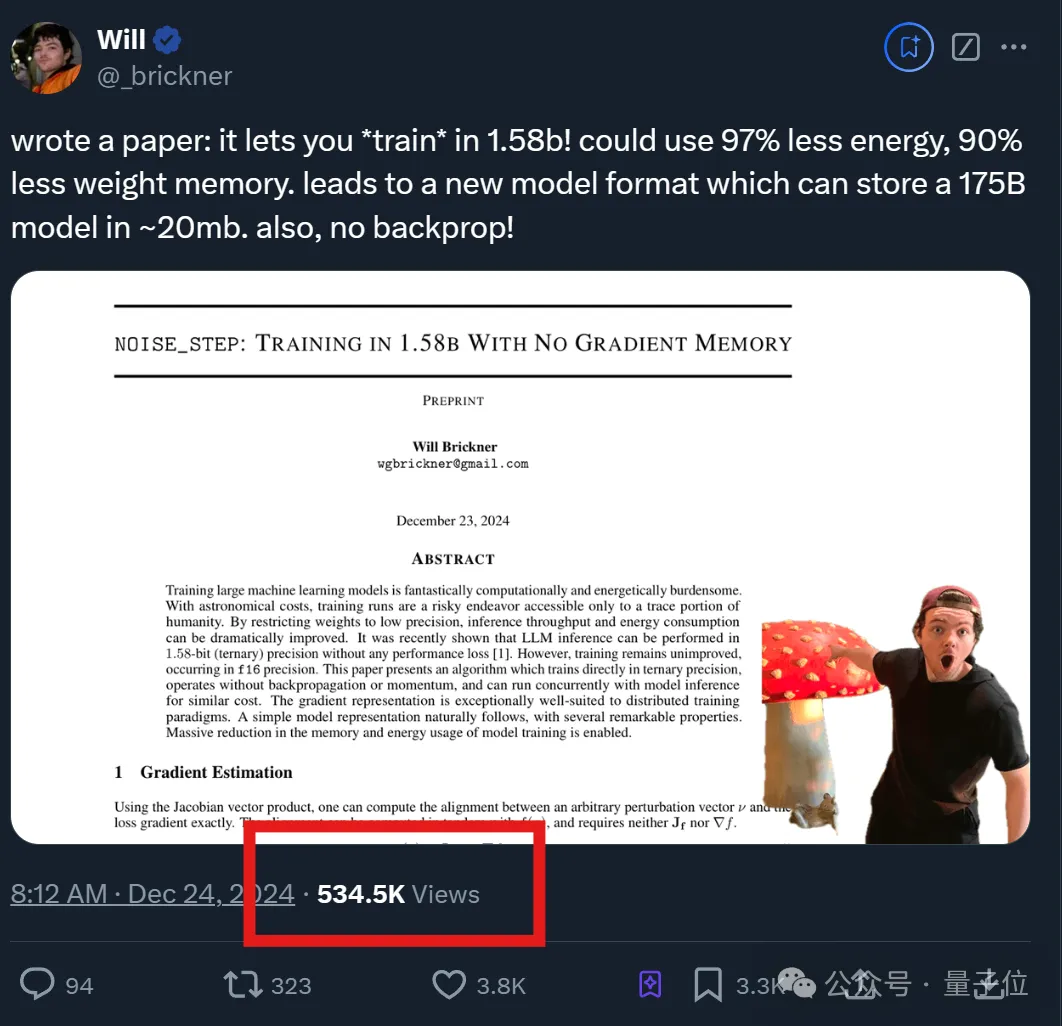
他提出了一项名为“noise_step”的新技术,允许模型直接在1.58-bit低精度下训练,且无需反向传播或动量(Momentum)加速,从而降低算力和存储消耗。
对此,网友们也纷纷发来祝贺,表示很高兴看到模型越来越具有性价比。
话不多说,来看论文具体内容。
简单说,noise_step的目标是通过降低模型训练的精度要求,来减少算力和存储消耗。
一开始,作者提到前人研究已经表明,大语言模型(LLM)的推理可以在1.58-bit精度下进行,且不会有任何性能损失。
比如下面这篇论文,有人引入了1-bit的LLM变体(即BitNet b1.58),其中LLM的每个参数或权重都是三元的{-1, 0, 1}。
它在困惑度(perplexity)和最终任务性能上与全精度(FP16或BF16)的Transformer LLM相匹配,同时在延迟、存储、吞吐量和算力消耗方面成本更低。

然而,上述变体是在推理时使用低精度,而在训练时仍需高精度权重。
因此,noise_step的一个核心区别是:无需反向传播。
允许模型直接在1.58-bit(三元)精度下进行训练,而不需要传统的反向传播(从后向前检查每一层)或动量方法。
注:反向传播(Backpropagation)是训练神经网络的核心算法,它通过反向逐层计算损失函数对每个权重的梯度,来反向逐层更新网络的权重,从而最小化损失函数。
具体而言,will小哥参考了《Gradients without Backpropagation》这篇论文,其中介绍了雅可比向量积(Jacobian Vector Product,JVP)这种不依赖反向传播的梯度估计方法。
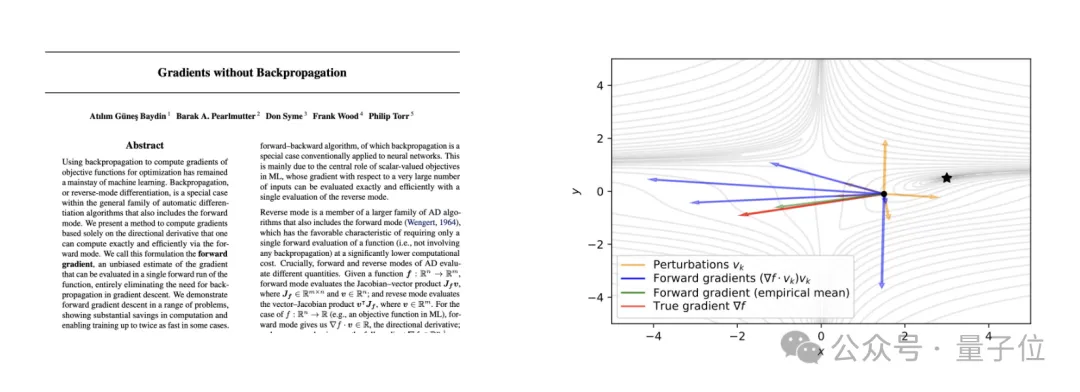
简单说,通过在前向传播中引入随机性,可以生成一个随机向量。这个随机向量与目标函数的梯度之间的对齐可以通过计算JVP来评估。
通过在多个随机方向上重复JVP计算,可以收集足够的信息来估计整个梯度向量,从而实现不依赖于反向传播的梯度估计。
will小哥的具体方法如下:

上述方式意味着,noise_step允许使用更稀疏的随机向量和简单的对齐值。
要知道传统的梯度计算需要大量计算资源,而noise_step由于不需要存储或传输大量数据,从而减少了存储使用。

此外,由于noise_step使用伪随机噪声,它只需要一个种子(初始值)就能复现整个训练过程,这意味着不需要存储大量的扰动向量,从而进一步减少了存储需求。
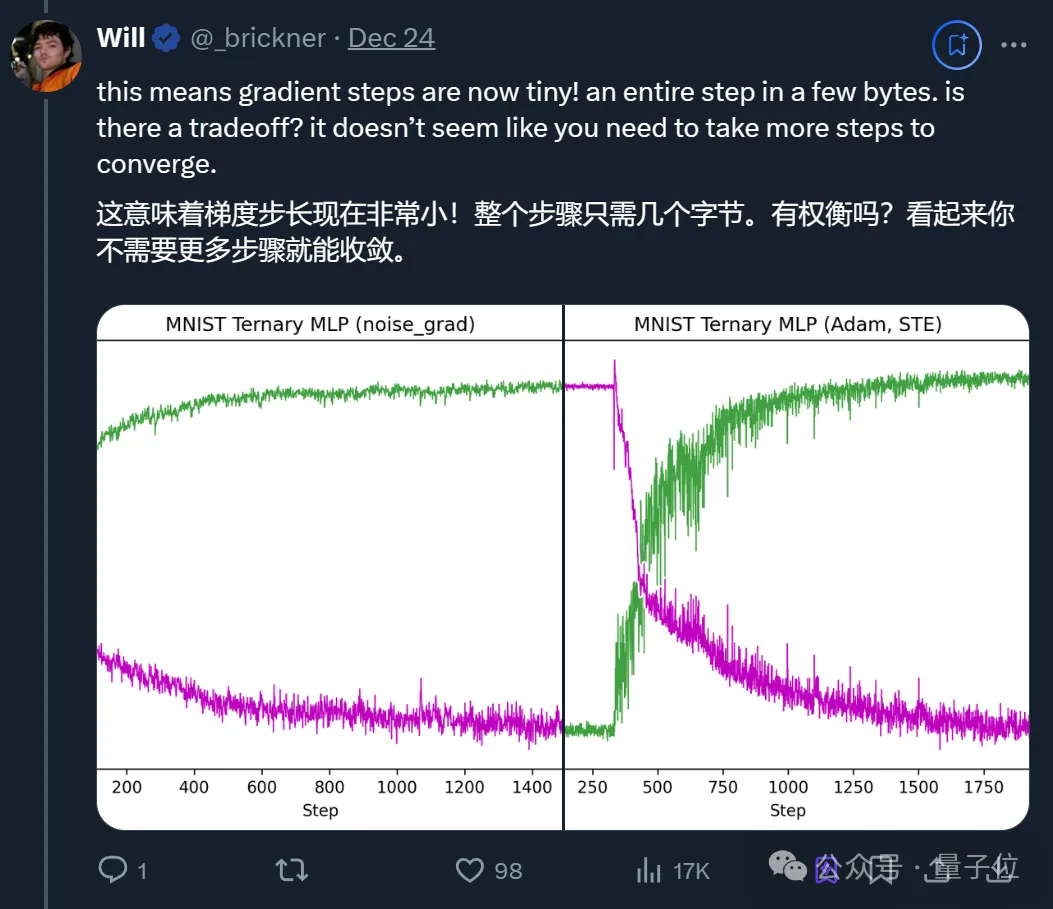
而且使用noise_step训练的模型可以存储训练步骤而非权重,这可能会大幅缩小模型尺寸,从而更快地下载模型。
按照will小哥的说法,也许今后一秒钟内下载一个SOTA模型?

同时由于上面提到的伪随机噪声方法,这种特性允许恢复权重的完整历史,因为每个步骤都是确定性的,并且可以独立于其他步骤进行计算。
因此微调将变得更加高效,甚至可能允许对过去的训练步骤进行编辑,例如翻转(negation)或屏蔽(masking)。
举个例子,如果发现某个训练步骤对模型性能产生了负面影响,可以对其进行调整而不必重新训练整个模型。
也就是说,人们在训练过程中能进行更精细的控制和调整了。
最后,作者认为这种方式尤为适合分布式训练。
在分布式训练中,通常需要在不同的计算节点之间同步梯度和优化器状态,这会限制训练的速度。而noise_step通过减少每个扰动所需的位数,显著降低了通信量,从而提高了分布式训练的效率。
不过这也导致模型泄露变得更加容易,因为整个模型可以通过几个字节的训练步骤来传输。
对了,will小哥表示JVP可以和正常推理并行运行,几乎不增加成本。

除了论文,他也提供了一个CPU实现过程:

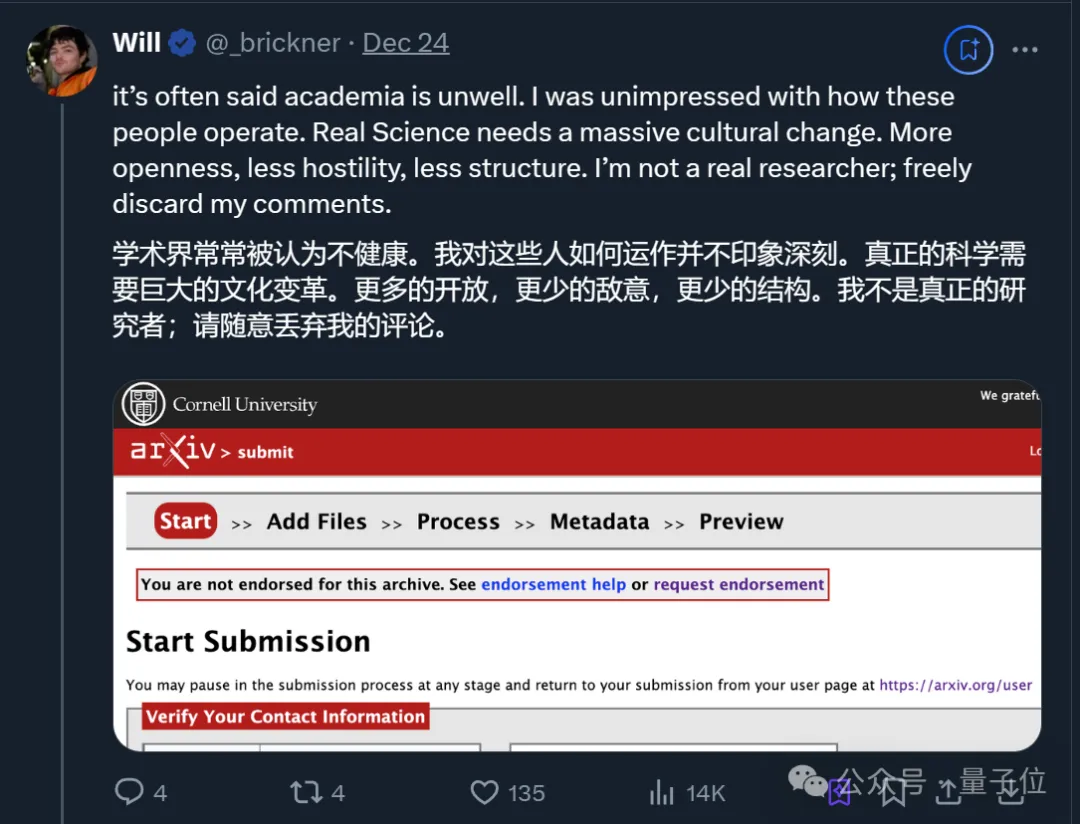
BTW,小哥在𝕏上分享完论文后,还顺带吐槽arXiv不给理由就拒绝了这篇论文。
后来他才补充,原来是卡在了背书(endorse)这一项,也就是需要现有用户的推荐或通过其他方式获得背书。
无奈之下,这篇论文目前被小哥放在了GitHub上。
感兴趣的童鞋可以进一步查看。
论文:
https://github.com/wbrickner/noise_step?tab=readme-ov-file
CPU实现过程:
https://colab.research.google.com/drive/1hXzf5xB4INzMUNTlAB8CI1V10-JV7zyg?usp=sharing
参考链接:
https://x.com/_brickner/status/1871348156786704657
文章来自于微信公众号“量子位”,作者“一水”




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
