# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当前 AI 领域呈现「端云并发」的发展态势,端侧与云侧大模型各展所长,共同推动着智能发展与应用落地的边界。端侧模型实现本地毫秒级实时响应,云侧模型依托强大算力支持复杂大规模推理,而两者都离不开高效的推理系统支撑。
在 GTC 2025 上,NVIDIA CEO 黄仁勋强调,大模型计算正从预训练转向推理优化阶段。随着产业落地加速,推理计算需求正呈现爆发式增长,如何在性能、成本和响应速度间取得平衡成为关键工程挑战,推理系统正是解决这一问题的核心。
近日,无问芯穹发起了一次推理系统开源节,连续开源了三个推理工作,包括加速端侧推理速度的 SpecEE、计算分离存储融合的 PD 半分离调度新机制 Semi-PD、低计算侵入同时通信正交的计算通信重叠新方法 FlashOverlap,为高效的推理系统设计提供多层次助力。下面让我们一起来对这三个工作展开一一解读:
随着 DeepSeek 等开源模型表现出越来越强悍的性能,在 PC 端本地部署大模型的需求持续增长。尽管许多情况下使用云端模型更加便利,但本地部署仍在数据隐私、网络限制或者成本限制的条件下具有不可替代的优势。
然而,端侧设备往往受限于算力、电量和存储,且 CPU、GPU、NPU 三类异构处理器的算力、架构差异显著,产生许多不必要调度和通信开销。将模型安装到 PC 端本地环境后,推理速度太慢,能达到使用标准的场景也就比较有限了。
无问芯穹第一天开源的 SpecEE 推理引擎框架,就是为了解决端侧计算、存储与异构处理器协同挑战而生。相关工作被收录于 ISCA 2025(International Symposium on Computer Architecture,计算机体系结构领域的顶级会议),论文已在 arXiv 公开。

相比云场景,端侧设备的场景特征是「单用户、少请求」,而单用户下大模型推理是底库很大的搜索分类问题。
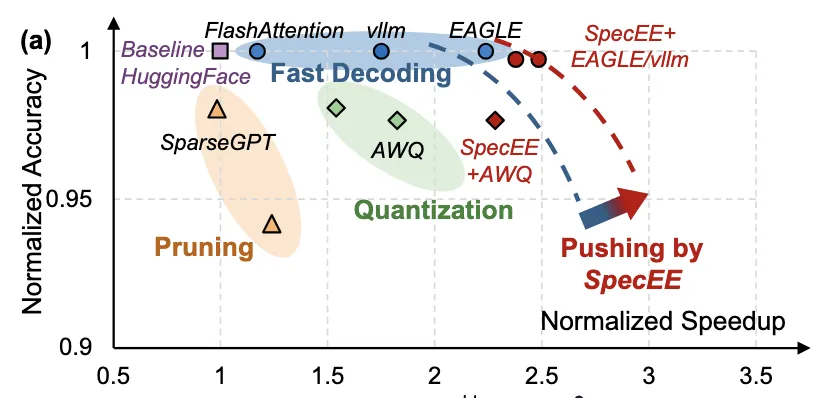
不同于传统的 Early Exiting 技术,SpecEE 从搜索空间的角度探索 Early Exiting 的优化策略,并提出基于推测模型对 Early Exiting 搜索空间进行缩减,推动精度与速度的帕累托前沿。在 AI PC 场景下,可以获得超过 2 倍的性能提升。
由于其角度的独特性,SpecEE 的算法可以无感兼容任何轻量化优化技术。为了将核心思想进一步推进应用在 Early Exiting 预测器上,研究团队针对预测器开展了三层面的优化:在算法层面通过轻量化预测器设计实现低开销高精度预测;在系统层面通过自适应调度引擎实现预测器弹性激活;在映射层面,则通过重构推测解码 Early Exiting 机制实现线性复杂度映射。

无问芯穹展示了 SpecEE 在联想拯救者 Y7000(搭载 NVIDIA RTX 4060 Laptop GPU 与 Intel Core I7-13650HX)上的实测推理速度比较,运行 ReLU-llama-7B 最高可实现 14.83 token/s 的推理速度,相比 PowerInfer 12.41 token/s 的速度,实现了近 20% 的提升。相比于常用端侧部署框架 llama.cpp,SpecEE 则能够在 AI PC 上实现高达 2.43 倍的加速。
值得一提的是,SpecEE 由于其动态性,也适合在单用户云端场景下的推理,并且由于其方法的正交性可以与现有的一些优化方法进行集成,可无感兼容任何端侧加速方案,进一步推动了端侧模型推理精度和速度的帕累托前沿。
第一代 P/D 融合架构采用资源统一分配的策略,Prefill(预填充)和 Decode(解码)阶段共享计算和存储资源,整个推理流程在同一个实例上完成。第二代 P/D 分离架构将 Prefill 和 Decode 阶段的计算与存储资源解耦,请求在 Prefill 实例上完成 Prefill 阶段计算后,传输 KV cache 至 Decode 实例进行后续计算,解耦了 TTFT 和 TPOT 的优化目标,消除了 P/D 之间的干扰,被月之暗面、DeepSeek 等公司纷纷采用,NVIDIA 也将其作为下一代 LLM 服务系统的核心技术方向。无问芯穹第二个开源项 Semi-PD——第三代 PD 半分离架构,在消除 P/D 干扰的同时,保留了融合式的存储效率,实现在给定资源和 SLO 的前提下,最大化「Goodput」(有效吞吐量)。

Semi-PD 混合架构采用了「计算分离、存储融合」的设计理念。不同于传统方案将 Prefill 和 Decode 任务分别放在不同实例上,Semi-PD 让 Prefill 进程和 Decode 进程共享同一个实例,各自占用部分计算资源(可以想象为「半张卡」)。同时,两个进程通过 IPC 机制,模型权重和 KV cache 只需存储一份,同时能够「看到」所有的存储资源。
这种设计可以灵活调整 P 和 D 的资源占比,从而更细粒度地调优首次 token 延迟(TTFT)和每个输出 token 的时间(TPOT)。考虑到实际服务中 Prefill 和 Decode 的负载往往动态变化的,固定资源分配会导致资源利用率低,为此,研发团队创新性地引入了服务级别目标(SLO)感知的动态资源调整机制。该机制通过实时监控系统负载,动态调整 Prefill 和 Decode 的资源配比(x, y),以更好地满足延迟约束和系统吞吐的双重目标。在满足 SLO 要求的同时,最大化有效吞吐量的性能突破。
打个比方,如果说 PD 分离架构让备菜师傅专注处理食材(Prefill),炒菜师傅只管烹饪(Decode),那么 Semi-PD 混合架构则像配备了智能变形功能的现代化厨房,通过可移动的智能隔断,厨房空间可以动态划分:早上备菜多就多给备菜区,午市炒菜忙就多给烹饪区。最巧妙的是,两个区域共享同一套智能厨具系统(统一存储),既避免了重复购置设备,又能通过资源动态分配实现效率最大化。
相比于开源的 SOTA 实现,Semi-PD 的 Goodput 提升了 1.55-1.72 倍,单请求平均端到端时延提升 1.27-2.58 倍。
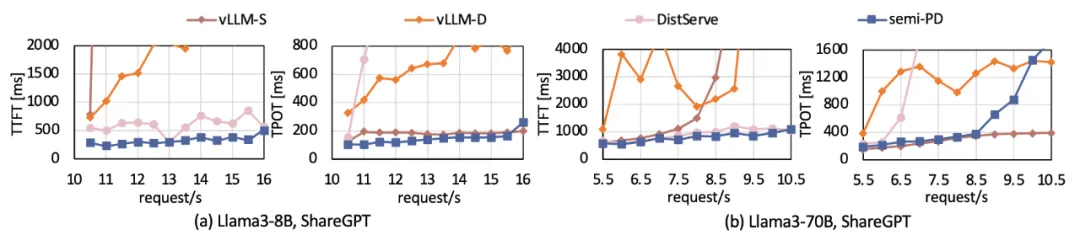
llama 系列模型结果:
其中 vllm-S 对应 splitfuse schedule,vllm-D 对应 default schedule 即 Prefill 优先
第三天,无问芯穹放出了一个非常有意思的工作「FlashOverlap」,这是一个基于控制信号的计算通信重叠新思路。主要出发点在于提供一种低侵入矩阵乘法、无侵入通信的方式完成细粒度计算通信重叠,可以无缝适配矩阵乘法和各种常见的通信原语,包括但不限于 AllReduce、ReduceScatter、All2All 等。对于通信瓶颈显著的低端消费卡来讲优化效果尤为明显,可以达到高达 1.65 倍的性能提升。
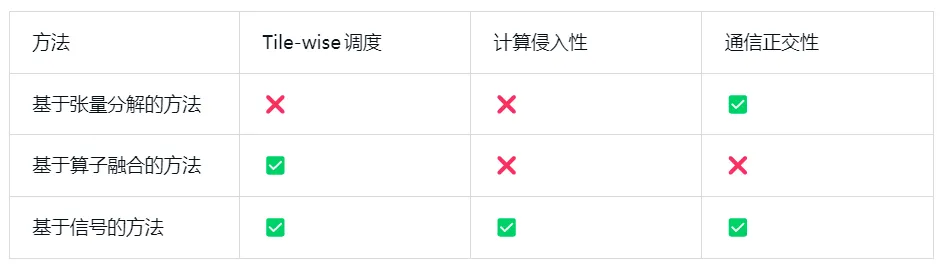
研究团队首先指出,一个低开发成本高性能收益的计算和通信重叠方案,需要至少满足以下三个方面:
为此,我们提出一种基于信号的计算通信重叠技术,可以完美契合上面提到的三个准则。
就好比参加接力跑比赛需要训练一套团队战术——交接棒时要往前多送一段,最大化重叠效果;接棒时要站在整体最短路径上,最小化对竞速部分的伤害;交接时统一右手交右手接,最小化对大部分运动员左右手习惯的适配成本。FlashOverlap 就像是一套最先进的接力赛战术,能够让整体团队都省力的同时,跑出最快的速度。
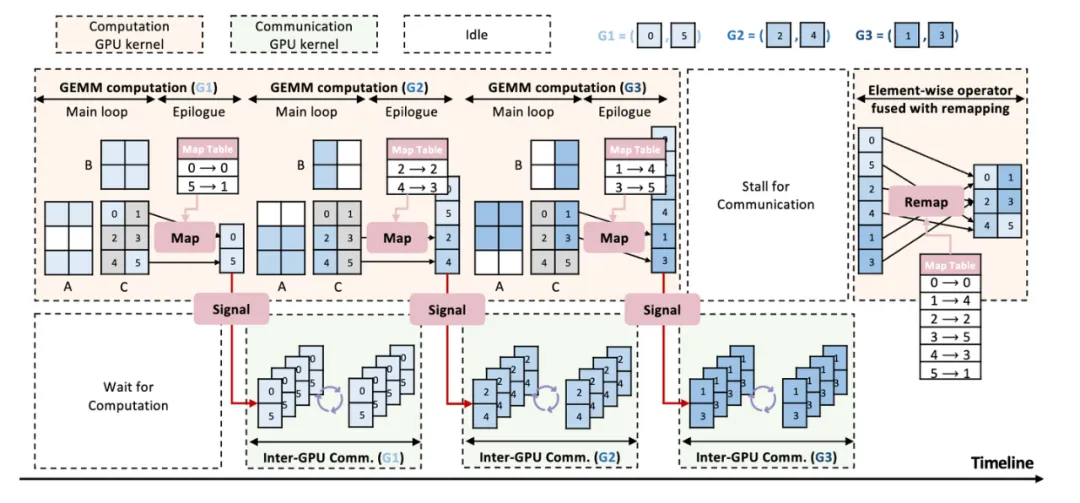
如何能减少对计算的侵入性,同时又能和通信都正交是实现基于信号控制做通信的难点。FlashOverlap 的核心 idea 是,让计算 Kernel 能够在完成一部分计算结果之后自动发出一个就绪的信号,然后接收到该信号之后再发起一次针对就绪部分数据的 NCCL 的通信。最终基于信号的计算通信重叠架构如下图:
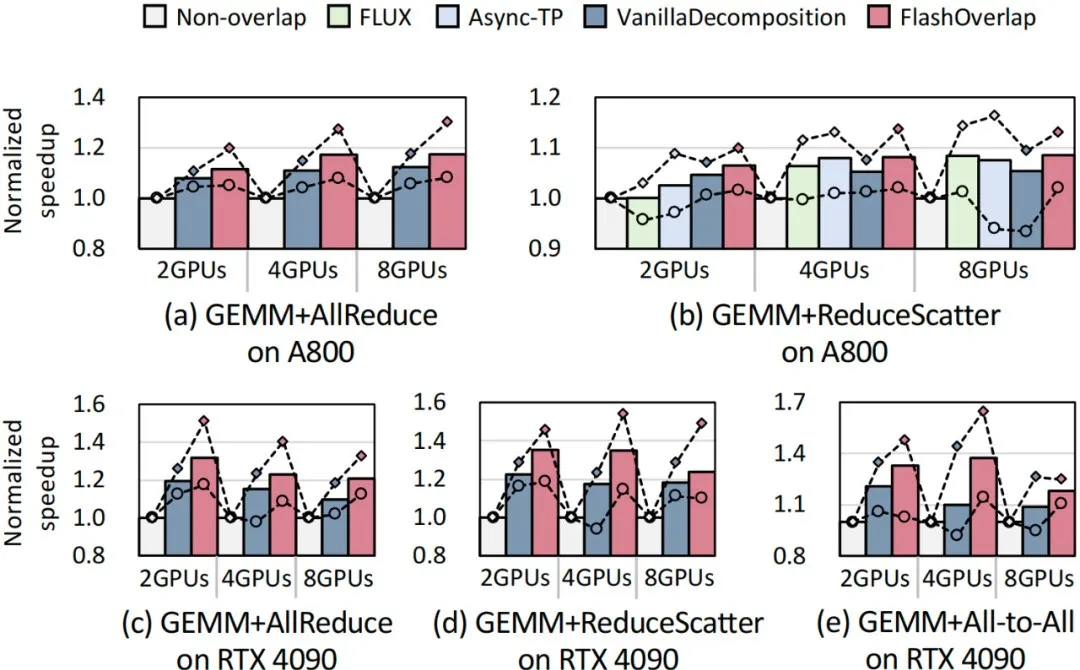
FlashOverlap 的实验结果分为两部分:第一部分是针对矩阵乘法和 AllReduce、ReduceScatter 和 All2All 三个通信算子,在 A800 和 4090 的优化效果;第二部分以 AllReduce 为例,分析 M、N、K 变化时优化效果的变化。
整体上看,FlashOverlap 可以获得 1.07-1.31 倍性能提升,而且大多数情况下都优于其他 SOTA 工作。具体如下图所示,研究团队测试了小面表格中大量的矩阵乘法形状,柱状图代表表格中所有矩阵乘法形状下的平均性能,线状图分别代表性能最差情况和最优情况。
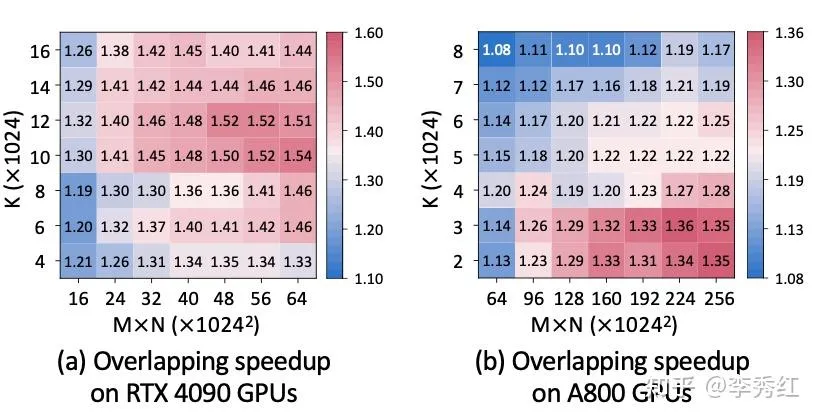
为了更进一步展开,研究团队在 4090 上针对 TP=2 下做 ReduceScatter,在 A800 上针对 TP=4 下做 AllReduce,这两种场景不同矩阵乘法形状 MKN 的性能结果。
研究团队表示,开源这一方案,希望能帮助到各个生成式大模型训练和推理场景,降低大规模计算带来的通信开销。
无问芯穹 2023 年就曾推出过一个惊艳业界的推理加速方法 FlashDecoding++(机器之心曾独家报道:GPU 推理提速 4 倍,256K 上下文全球最长:无问芯穹刷新大模型优化记录),通过异步方法实现注意力计算的真正并行,并针对「矮胖」矩阵乘优化加速 Decode 阶段的计算,将国际主流 GPU 推理速度提升了 2-4 倍。随后将这套软硬件协同设计能力逐个应用在国产计算卡上,取得了十余种计算卡的最佳优化效果,搭建了 GPU 云「异构云」,支持在多种国产芯片上完成大模型推理任务。
近日,无问芯穹联合创始人、CEO 夏立雪在出席活动时表示:「此次开源无问芯穹新一代大模型端、云推理系统相关工作,是希望以开源方案为桥梁,助力大模型产业落地在保障质量的基础上实现效率跃升与成本优化,加速技术普惠与产业升级进程。」
推理系统是技术协同的中枢,也是产业价值的放大器。在纵向维度上,推理系统向上连接着 AI 模型、工具和各类应用场景,向下对接硬件资源,能充分发挥不同硬件优势;在横向维度上,高效推理系统的应用,将全面激活大模型在端侧的应用潜能以及在云侧的生产力效能,推动 AI 技术的价值向更多行业和人群辐射渗透。
文章来自微信公众号 “ 机器之心 ”




