# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
已经有越来越多的人发现:大模型排行榜LMArena,可能已经被大厂们玩坏了!
就在最近,来自Cohere、普林斯顿、斯坦福、滑铁卢、MIT和Ai2等机构的研究者,联手祭出一篇新论文,列出详尽论据,痛斥AI公司利用LMArena作弊刷分,踩着其他竞争对手上位。

论文地址:https://arxiv.org/abs/2504.20879
与此同时,AI大佬、OpenAI创始成员Andrej Karpathy也直接下场,分享了一段自己的亲身经历。
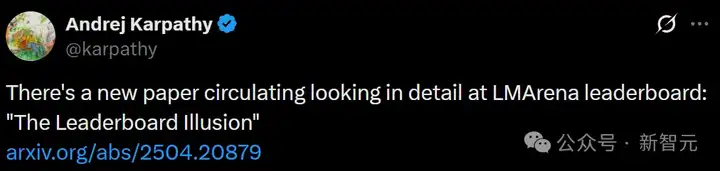
前一段时间,Gemini模型一度在LMArena排名第一,远超第二名。
但Karpathy切换使用后,感觉还不如他之前用的模型。
相反,大约在同一时间,他的个人体验是Claude 3.5是最好的,但在LMArena上的排名却很低。
他还发现一些其他相对随机的模型,通常小得可疑,据他所知几乎没有现实世界的知识,但排名也很高。
他开始怀疑,谷歌等AI巨头在暗中操纵LMArena的排名。
要知道,就在本月初,就有报道称LMArena可能正在成立新公司,筹集资金。
在这个时候曝出丑闻,不知对此是否会有影响。
这篇报告,研究者花费了5个月时间分析了竞技场上的280万场战斗,涵盖了43家提供商的238个模型。
结果表明,少数提供商实施的优惠政策,导致过度拟合竞技场特定指标,而不是真正的AI进步。
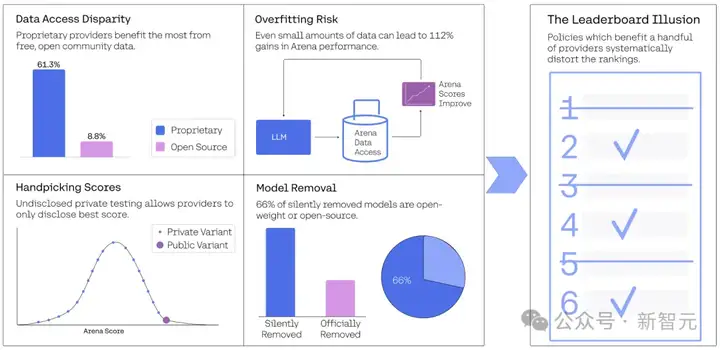
因为存在未公开的私下测试机制,少数公司能在模型公开发布前测试多个变体,甚至选择性地撤回低分模型的结果。
如此一来,公司便可以「挑三捡四」,只公布表现最好的模型得分,从而让LMArena的排行榜的结果出现严重「偏见」。
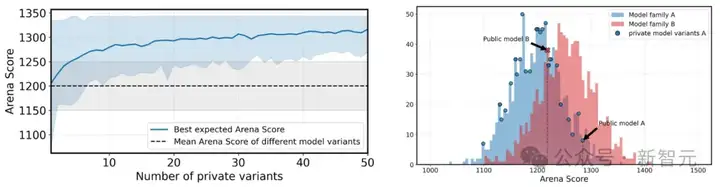
而这种优势,会随着变体数量的增加,而持续叠加。
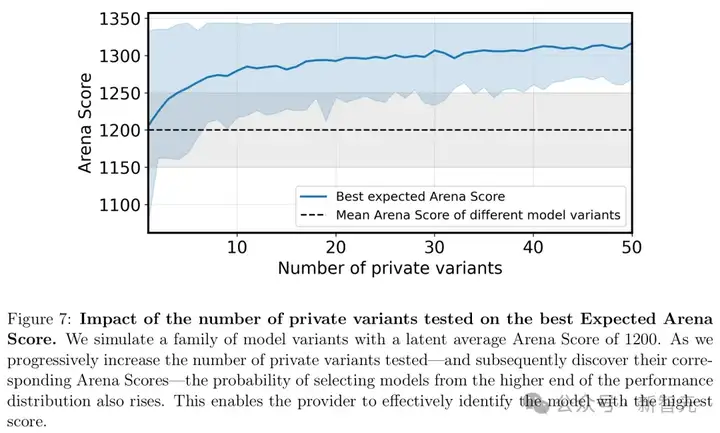
私下测试模型变体数量对最佳预期得分的影响
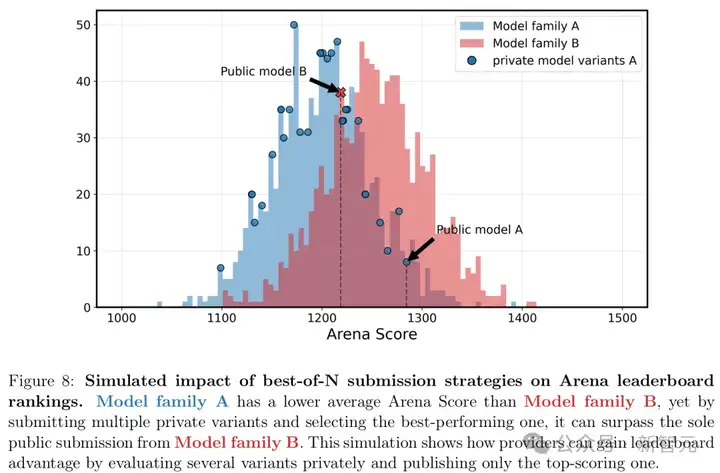
「best-of-N」提交策略对排名的模拟影响
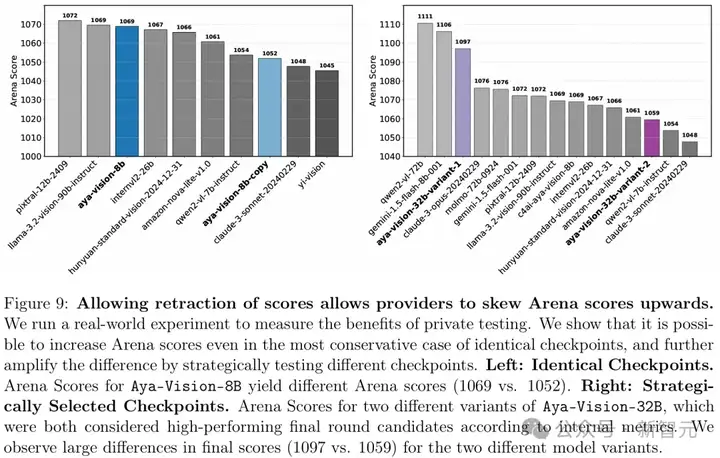
允许撤回评分会导致提供商有意抬高竞技场分数
比如说,Meta在发布Llama 4之前,曾私下在LMArena上测试了27个LLM变体。
而最终只公布了其中一个分数。
巧的是,这个模型恰恰就在LMArena上名列前茅。
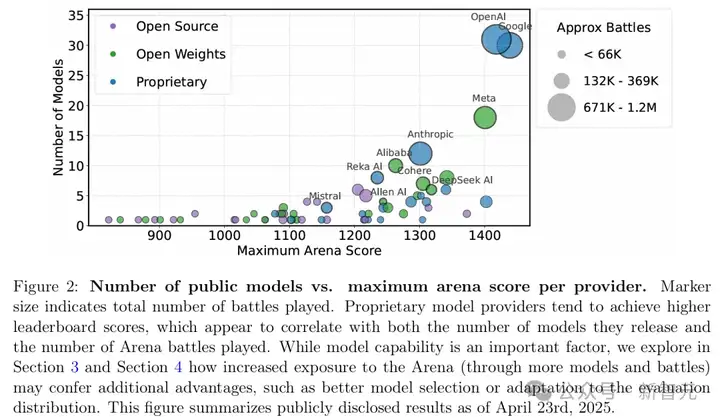
Cohere的AI研究副总裁、论文合著者Sara Hooker在接受外媒采访时抱怨说:「只有少数公司会被告知可以私下测试,而且部分公司获得的私下测试机会,远超其他公司。」
「这就是赤裸裸的儿戏。」
与此同时,研究者还发现:
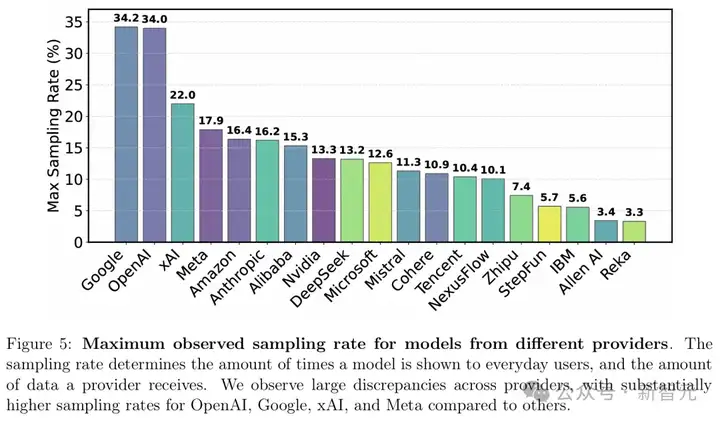
不同模型提供者的最大观测采样率
采样率反映了模型在LMArena中被普通用户看到的频率,也直接决定了该模型开发者能获取多少用户交互数据。
LMArena是一个开放的社区资源,提供免费反馈,但61.3%的所有数据都流向了特定的模型提供商。
具体来说,他们估算:
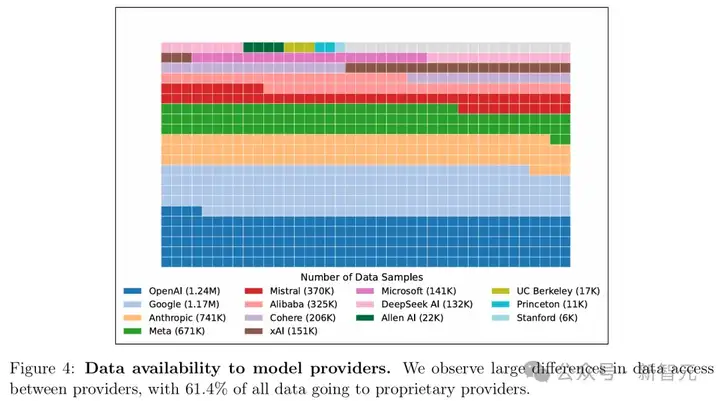
模型开发者的数据可用性情况
而保守估计哪怕是有限的额外数据,也可能带来高达112%的相对性能提升。
这进一步说明模型在Arena上的表现很容易被「过拟合」——即优化的是排行榜表现,而不是真正的通用模型质量。
值得注意的是,LMArena的构建和维护依赖于组织者和开源社区的大量努力。
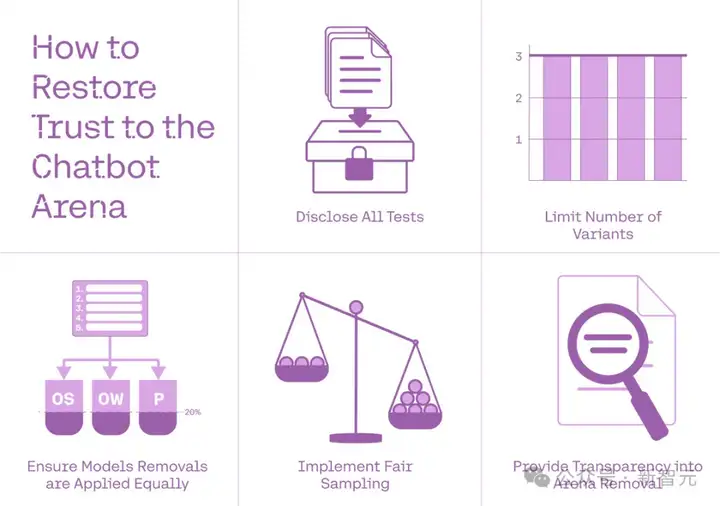
组织者可以通过修订他们的政策来继续恢复信任。
论文还非常清楚地提出了五个必要的改变:
铺天盖地的质疑袭来,LMArena火速出来回应了!
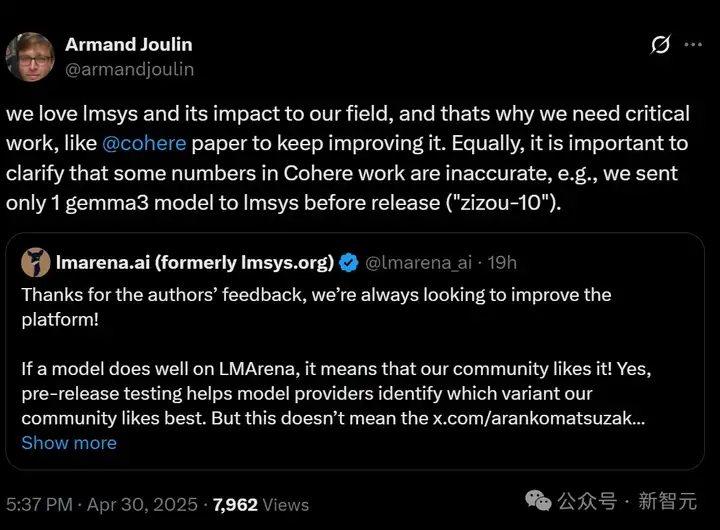
它的官号第一时间发推回应称,这项研究存在诸多事实错误和误导性陈述,充满了「不确定和可疑的分析」。

而他们的说法,得到了谷歌DeepMind首席研究员Armand Joulin的声援。
他表示,论文中的一些数据是不准确的,比如谷歌只向LMArena发过一个Gemma 3的模型,进行预发布测试。
具体来说,关于某些模型提供商未得到公平对待的说法:
事实错误:

LMArena的政策(上下滑动查看)
正如贝佐斯所说:「当数据与个人经验不一致时,个人经验通常是正确的。」
Karpathy也有同感。
他认为这些大团队在LMArena分数上投入了太多的内部关注和决策精力。
不幸的是,他们得到的不是更好的整体模型,而是更擅长在LMArena上获得高分的模型,而不管模型是否更好。
对此Karpathy表示,既然LMArena已经被操控了,那就给大家推荐一个有望成为「顶级评测」的新排行榜吧!
它就是——OpenRouterAI。
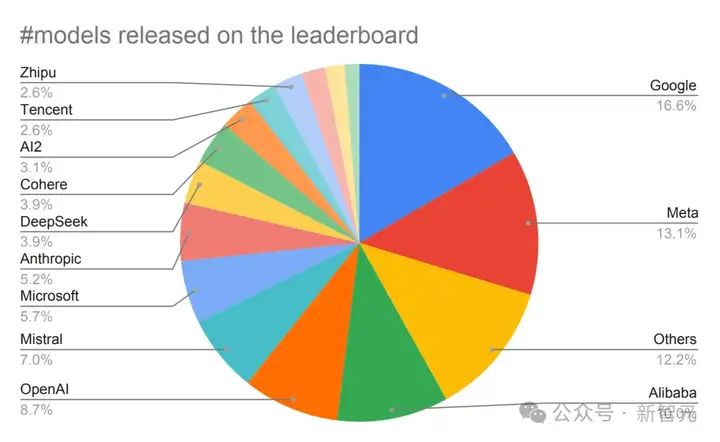
OpenRouter允许个人/公司在不同LLM提供商之间快速切换API。
他们都有真实的用例(并非玩具问题或谜题),有自己的私有评测,并且有动力做出正确的选择,因此选择某个LLM就是在为该模型的性能和成本的组合投票。
Karpathy表示,自己非常看好OpenRouter成为一个难以被操控的评测平台。
如今的爆火,或许让人早已忘记,LMArena最初只是UC Berkeley、斯坦福、UCSD和CMU等高校的几位学生自己做出来的项目。
和传统评测不同,LMArena采用的则是一套完全不同的方式——
用户提出问题,两个匿名AI模型给出答案,然后评判哪个回答更好,并最终将这些评分被汇总到一个排行榜上。
凭借着这套创新性的方法,它一举成为了当时几乎唯一一个能较为客观地反映LLM性能的榜单。
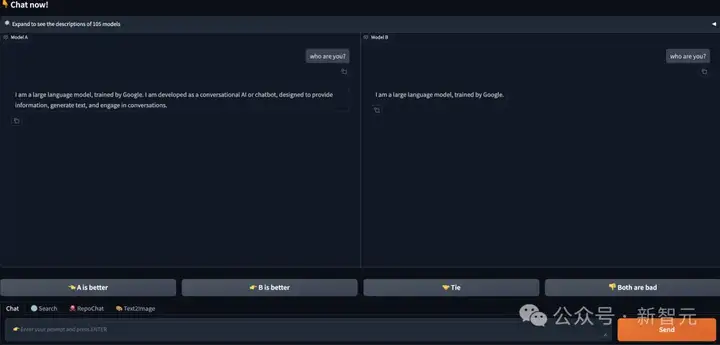
在输入框中输入问题,两个不同的模型A和B同时回答。之后,用户可选A或B的不同评价:A更好,B更好,平局,都不好
随着科技公司投入数百亿美元押注AI将成为未来几十年的决定性技术,LMArena也迅速走红。
在吸引客户和人才方面,任何领先竞争对手的优势都可能带来重大影响,这就是为什么众多科技高管和工程师像华尔街交易员盯盘一样密切关注LMArena。
之后的故事,大家就都知道了。
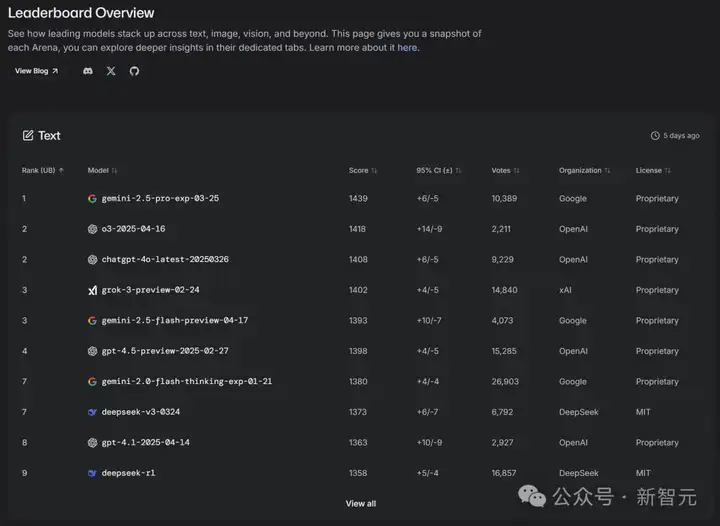
问题在于,作为课余项目的LMArena本身并不完善。之所以能在持续的爆炸性增长下不失客观性,靠的是创始人们坚定的初心。
随着创始成员陆续毕业,新成员的加入,LMArena似乎也离它最初的路线,越来越远。
一方面,由于投票不公开、以及哪些模型应该进入竞技场是由某几位成员独断决定的,导致LMArena自身机制就缺乏透明性。
另一方面,新团队在某个时间点突然决定,把LMArena开放给头部大公司做匿名模型测试。
这帮摸爬滚打了多年的老油条们,显然不会错失这一良机。基于对大量实测数据的分析,这些技术大佬们很快就「掌握」了LMArena的调性,纷纷刷起了高分。
从此,质疑声便开始此起彼伏。
参考资料:
https://x.com/karpathy/status/1917546757929722115https://x.com/arankomatsuzaki/status/1917400711882797144https://techcrunch.com/2025/04/30/study-accuses-lm-arena-of-helping-top-ai-labs-game-its-benchmark/https://x.com/lmarena_ai/status/1917668731481907527https://arxiv.org/abs/2504.20879https://openrouter.ai/rankings
文章来自微信公众号 “ 新智元 ”



