
首发丨央企资本下场,“物理 AI”黑马深度机智又融了数亿元
首发丨央企资本下场,“物理 AI”黑马深度机智又融了数亿元今日,投中网获悉,“物理AI”黑马——深度机智再获数亿元融资,本轮融资由国寿长三角科创基金领投,老股东普华资本、诚通科创基金持续加码,蓝湖资本、博彦科技、磐谷创投、朝晖资本、财鑫资本、道禾长期投资、易高资本、明德资本等十余家市场化机构、产业资本同步入局。
来自主题: AI资讯
9126 点击 2026-06-27 14:37
 搜索
搜索
今日,投中网获悉,“物理AI”黑马——深度机智再获数亿元融资,本轮融资由国寿长三角科创基金领投,老股东普华资本、诚通科创基金持续加码,蓝湖资本、博彦科技、磐谷创投、朝晖资本、财鑫资本、道禾长期投资、易高资本、明德资本等十余家市场化机构、产业资本同步入局。

据彭博社记者古尔曼报道,苹果公司负责Vision Pro头显和智能眼镜业务的负责人保罗·米德(Paul Meade)即将离职,转而加入OpenAI。米德在苹果担任视觉产品事业部的硬件工程副总裁。古尔曼称,米德将于下周离开苹果,加入OpenAI的硬件部门,负责OpenAI即将推出的设备系列。

有网友发梗图表示震惊,怎么会有用户一天能运行 Agent 71 个小时。也就是说,在 OpenAI 内部,工作场景里的 AI 使用,几乎已经切到了 Codex 上。Codex 这份报告将衡量 AI 应用深度的指标,定位在我们交出去的任务有多重、agent 替人类跑了多久、用户是不是在同时盯着好几条工作线。

Qualcomm 正在与 Modular 进行高级别谈判,拟收购该人工智能基础设施软件公司,交易估值约为 40 亿美元,据熟悉此事的人士称。这些人士表示,一笔交易可能会在未来几周内宣布,但他们要求不透露姓名,因为相关信息属于私人性质。
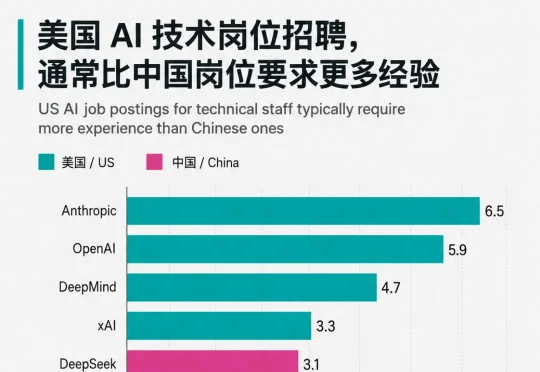
同样是进顶尖 AI 公司当工程师,在中国你只要 1.6 年经验,在美国却得熬到 5.5 年。换句话说,一个中国应届生刚拿到毕业证,就可能坐在 DeepSeek 的工位上调大模型;而他的美国同行还得在别的公司再「实习」四年,才够格投一份前沿 AI 实验室的简历。

来自至知创新研究院(IQuest Research)、中国人民大学高瓴人工智能学院、KAUST等机构的研究团队提出了FORT,一个面向Deep Search Agent的shortcut-resistant training-data synthesis framework。

2026 年 3 月,滴滴上线 AI 出行助手「小滴」。用户说一句「身体不舒服,有点晕车,尽快叫车」,AI 会把这句话拆成「驾驶平稳」「油车」「最近的车」等条件。[1]6 月,支付宝开始测试 AI 版「阿宝」。按照支付宝的说法,用户可以在一个对话框里调用上万种服务。过去需要四处寻找的公积金、缴费、挂号和寄快递,现在说句话就能找到。[2]

这就是最近网上热传热议,然后老黄黄仁勋给AI新趋势画的新重点:Nobody writes prompts anymore. The new job is to write and handle loops.(现在根本没有人写Prompt了,新时代的核心工作是编写和管理loop。)

6 月 25 日至 26 日,第 21 届开源中国·开源世界高峰论坛在北京中关村展示中心举行。本届大会由开源软件推进联盟(COPU)名誉主席、国际开源领袖奖获得者陆首群发起,本届大会由开源软件推进联盟(COPU)名誉主席、国际开源领袖奖获得者陆首群发起,由 COPU 主办、CSDN 承办,来自国际顶尖基金会、
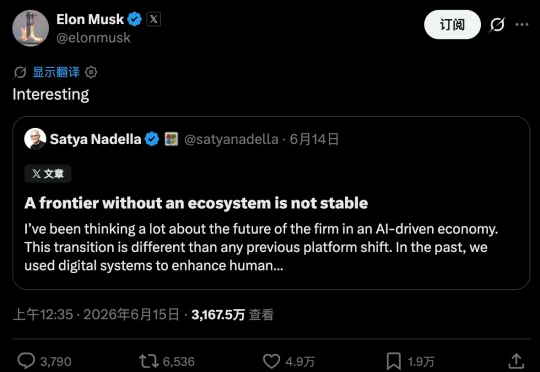
微软CEO 萨蒂亚·纳德拉,上周发的那篇《没有生态的前沿,立不住》(A frontier without an ecosystem is not stable),是近期挺有意思的一篇文章。不在于它提出了多少新概念,里面的很多要点,在近一年里大多已有讨论,而在于说它的不是旁观者,而是亲手运营着庞大 AI 基础设施的人,并且纳德拉用很朴素的语言,把两件非常重要的事情讲清楚了: