# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当前,多模态大模型驱动的图形用户界面(GUI)智能体在自动化手机、电脑操作方面展现出巨大潜力。
然而,一些现有智能体更类似于「反应式行动者」(Reactive Actors),主要依赖隐式推理,面对需要复杂规划和错误恢复的任务时常常力不从心。
我们认为,要真正提升 GUI 智能体的能力,关键在于从「反应式」迈向「深思熟虑的推理者」(Deliberative Reasoners)。
为此,浙江大学联合香港理工大学等机构的研究者们提出了 InfiGUI-R1,
一个基于其创新的 Actor2Reasoner 框架训练的 GUI 智能体,旨在让 AI 像人一样在行动前思考,行动后反思。

想象一下,你让 AI Agent 帮你完成一个多步骤的手机操作,比如「预订明天下午去北京的高铁票」。
一个简单的「反应行动」式 Agent 可能会按顺序点击它认为相关的按钮,
但一旦遇到预期外的界面(如弹窗广告、加载失败),就容易卡壳或出错,因为它缺乏「规划」和「反思」的能力。
为了让 GUI 智能体更可靠、更智能地完成复杂任务,它们需要具备深思熟虑的推理能力。
这意味着智能体的行为模式需要从简单的「感知 → 行动」转变为更高级的「感知 → 推理 → 行动」模式。这种模式要求智能体不仅能看懂界面,还要能:
为了实现这一目标,研究团队提出了 Actor2Reasoner 框架,
一个以推理为核心的两阶段训练方法,旨在逐步将 GUI 智能体从「反应式行动者」培养成「深思熟虑的推理者」。
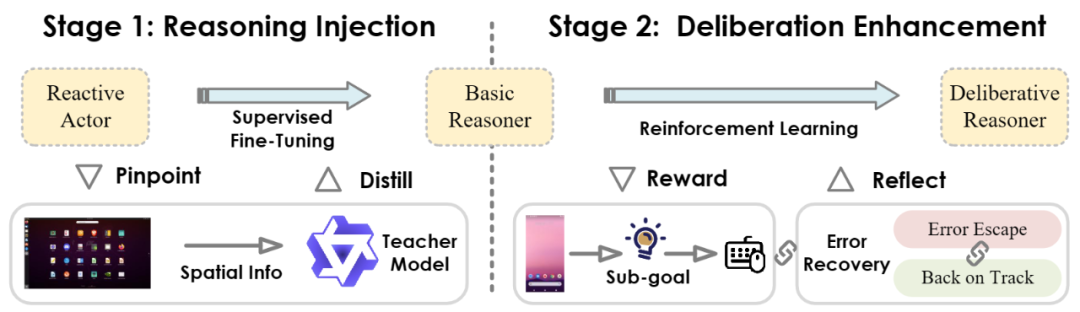
图:Actor2Reasoner 框架概览
此阶段的核心目标是完成从「行动者」到「基础推理者」的关键转变。研究者们采用了空间推理蒸馏(Spatial Reasoning Distillation)技术。
他们首先识别出模型在哪些交互步骤中容易因缺乏推理而出错(称之为「推理瓶颈样本」),
然后利用能力更强的「教师模型」生成带有明确空间推理步骤的高质量执行轨迹。
通过在这些包含显式推理过程的数据上进行监督微调(SFT),引导基础模型学习在生成动作前,先进行必要的逻辑思考,特别是整合 GUI 视觉空间信息的思考。
这一步打破了「感知 → 行动」的直接链路,建立了「感知 → 推理 → 行动」的基础模式。
在第一阶段的基础上,此阶段利用强化学习(RL)进一步提升模型的「深思熟虑」能力,重点打磨规划和反思两大核心能力。研究者们创新性地引入了两种方法:
通过评估生成的子目标与真实子目标的对齐程度,为模型的规划能力提供有效的学习信号。
例如,让模型学习在执行了错误动作后如何使用「返回」等操作进行「逃逸」,以及如何在「回到正轨」后重新评估并执行正确的动作。
这种针对性的训练显著增强了模型的鲁棒性和适应性。
为了有效引导强化学习过程,研究者们还采用了一套专门适用于 GUI 多种任务场景的奖励函数,为智能体提供更佳的反馈。
基于 Actor2Reasoner 框架,研究团队训练出了 InfiGUI-R1-3B 模型(基于 Qwen2.5-VL-3B-Instruct)。
尽管只有 30 亿参数,InfiGUI-R1-3B 在多个关键基准测试中展现出了卓越的性能:
在移动、桌面、Web 平台的文本和图标定位任务上全面领先,达到同等参数量模型中 SOTA 水平。
性能比肩参数量更大且表现优异的 7B 模型(如 UI-TARS-7B),证明了其在复杂专业软件(例如 CAD、Office)界面上的指令定位准确性。
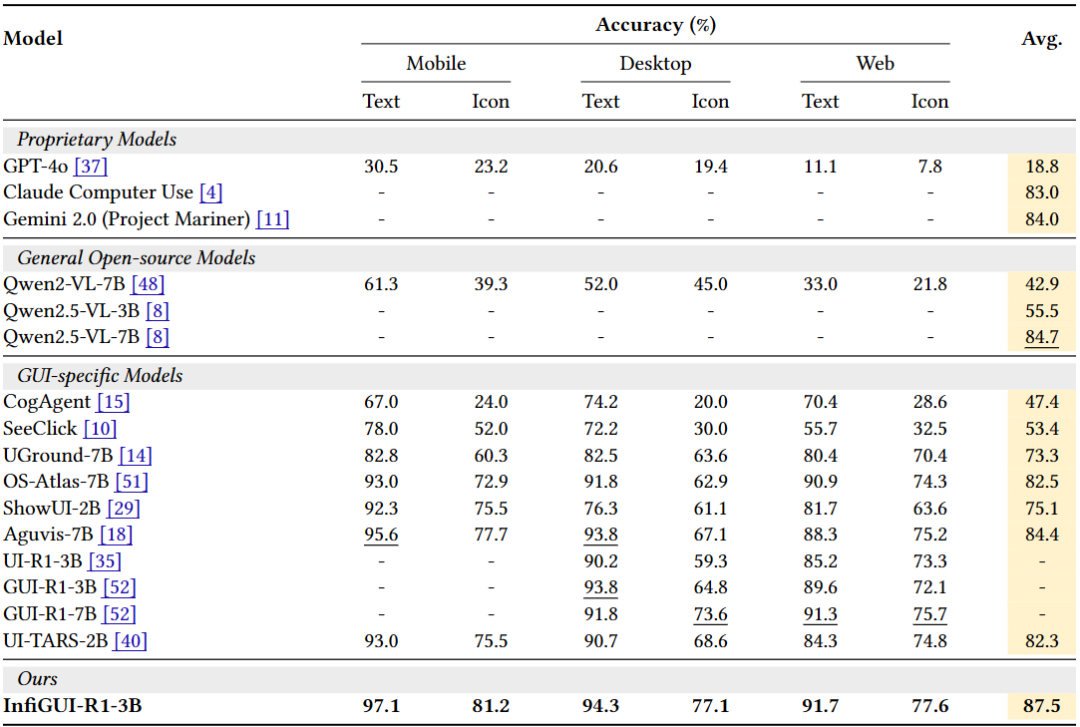
表:ScreenSpot 性能对比
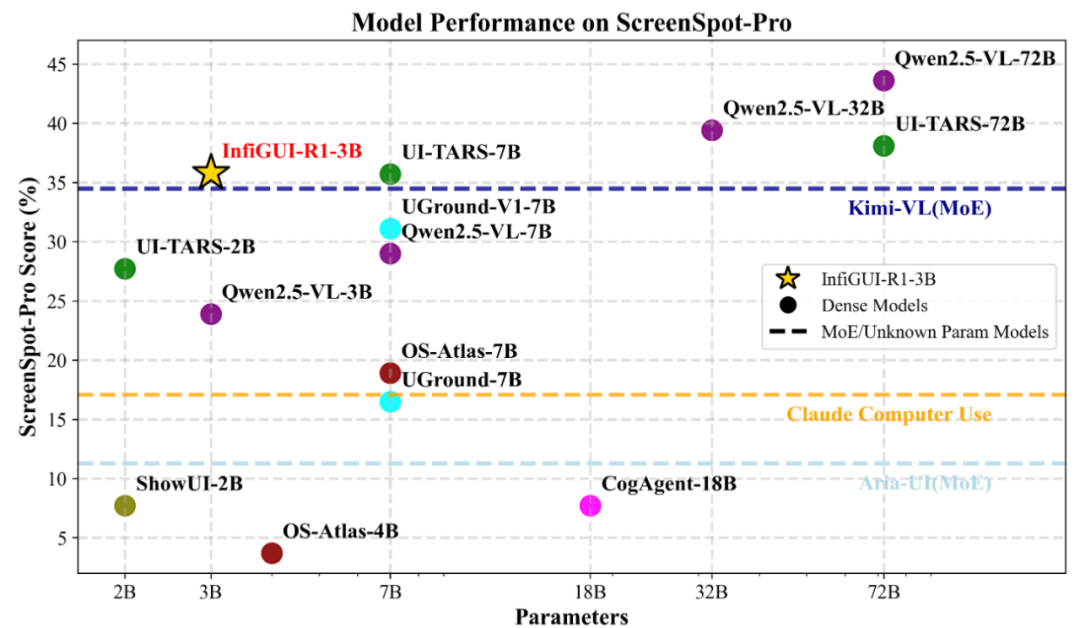
图:ScreenSpot-Pro 性能对比
在模拟真实安卓环境复杂任务的 AndroidControl 基准上(包含 Low 和 High 两个难度级别),成功率分别达到 92.1% 和 71.1%。
这一成绩不仅超越了参数量相近的 SOTA 模型(如 UI-TARS-2B),甚至优于一些参数量远超自身的 7B 乃至 72B 模型(如 Aguvis-72B)。
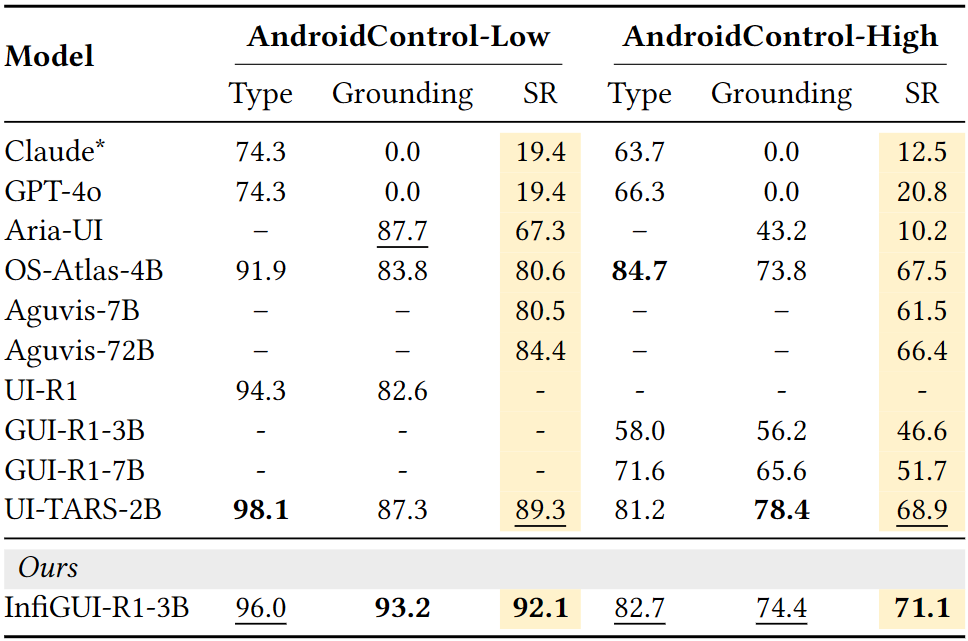
表:AndroidControl 性能对比
这些结果充分证明了 Actor2Reasoner 框架的有效性。
通过系统性地注入和增强推理能力,特别是规划和反思能力,
InfiGUI-R1-3B 以相对较小的模型规模,在 GUI 理解和复杂任务执行方面取得了领先或极具竞争力的表现。
InfiGUI-R1 和 Actor2Reasoner 框架的提出,为开发更智能、更可靠的 GUI 自动化工具开辟了新的道路。
它证明了通过精心设计的训练方法,即使是小规模的多模态模型,也能被赋予强大的规划、推理和反思能力,
从而更好地理解和操作我们日常使用的图形界面,向着真正「能思考、会纠错」的 AI 助手迈出了坚实的一步。
文章来自于微信公众号 “机器之心”,作者 :机器之心



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
