# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在上一篇文章中,我为大家介绍了SAT如何通过神经网络驱动的智能分段技术,解决传统文本处理中的语义割裂问题。今天,我将继续与您探讨SAT如何与Pneuma系统融合,开创表格数据检索与表示的新范式。作为SAT模型的实际应用案例,我将SAT与Pneuma(https://arxiv.org/pdf/2504.09207 下文有代码链接)相结合,将智能文本分段能力应用于表格数据处理,不仅解决了内容与上下文的双重维度问题,还显著提升了检索准确性和效率。如果您尚未阅读昨天的文章,建议先了解SAT的基本原理,这将帮助您更全面地理解Pneuma系统的技术创新和价值。
在数据驱动的世界中,识别和提取相关表格数据已成为创造价值的首要步骤,然而这一过程却面临着前所未有的挑战。数据不仅存在于表格的内容(行和列)中,还隐藏在表格的上下文(来源、目的和使用方式)中,而这些上下文信息往往散落在EXCEL、CSV以及PDF文档或数据目录等外部资源中。
当用户需要根据采样方法查找特定表格时,他们不得不在内容和上下文之间来回切换,这种体验既繁琐又低效,尤其对于非技术用户而言,自然语言查询才是最直观的交互方式。
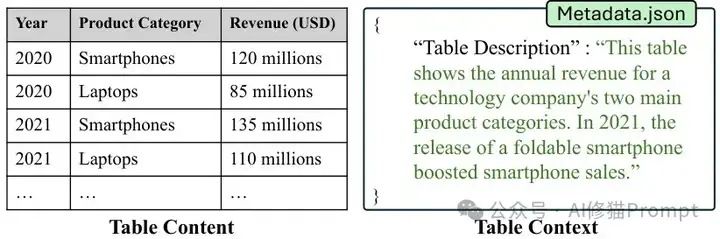
表格内容与上下文示例
Pneuma系统以突破性的方式解决了表格检索的核心难题:如何同时利用表格内容和上下文进行高效检索。该系统采用检索增强生成(RAG)架构,将大型语言模型(LLM)用于表格表示和检索两个关键环节,实现了对自然语言问题的精准响应。

Pneuma的卓越性能:
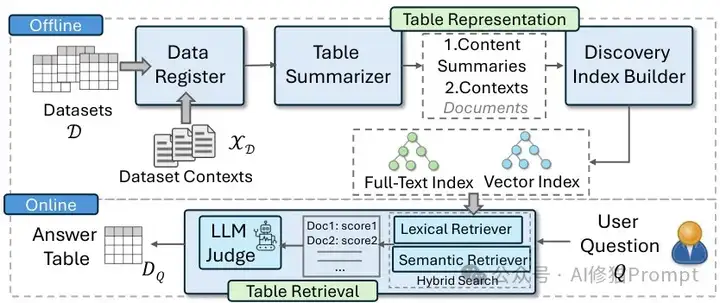
Pneuma系统架构图
在深入Pneuma系统之前,我们需要明确区分内容问题和上下文问题这两种核心查询类型:
Pneuma系统分为线下和线上两个关键阶段,形成了一个完整的表格检索生态系统:
2. 结果呈现:返回与检索文档关联的顶级表格
Pneuma在表格表示方面带来了革命性的突破,它利用LLM生成表格模式的叙述性描述,而不是仅依赖原始列名。

模式摘要示例
Pneuma的表格表示策略采用了模式摘要和行摘要相结合的双轨方法,平衡检索准确性和系统效率:
案例:在FetaQA数据集中,许多表格共享相同的模式,行信息对于提高命中率至关重要。
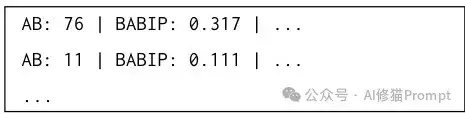
行摘要示例
在处理大型表格集合时,LLM推理成为主要的计算瓶颈。Pneuma通过创新的动态批处理技术显著提高了推理效率:
Pneuma的表格检索方法创新地结合全文和向量搜索,并利用LLM作为优化排名的机制:
2. 为每个唯一文档分配组合相关性分数
这种评分函数整合了词汇和语义相关性的优势,确保更准确的文档排名。
LLM判断是Pneuma系统中的关键创新,为检索结果提供了最后一道质量保障:
在一个化学领域的复杂问题上:
Pneuma在索引构建阶段引入了两项关键创新,解决大规模表格检索的存储瓶颈:
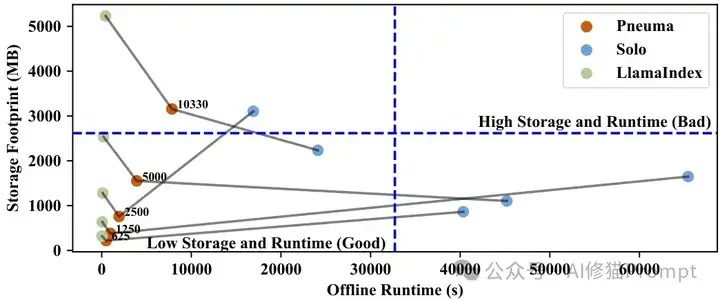
离线运行时间与存储占用对比
为公平评估表格检索系统,研究者开发了全面的基准生成器,模拟真实世界中的表格发现工作负载:
在六个真实世界数据集上的评估结果展示了Pneuma的性能:
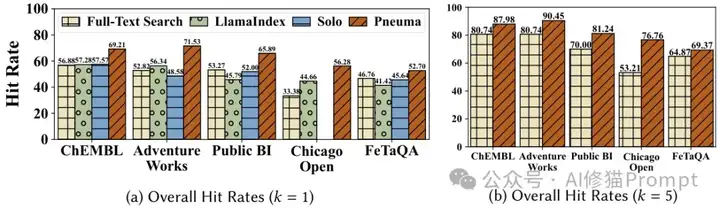
不同基准上的命中率对比
通过消融研究,研究者验证了Pneuma各组件对系统整体性能的重要贡献:
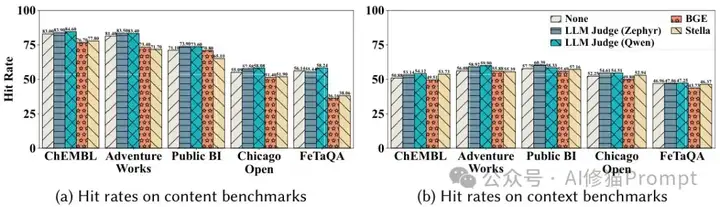
不同判断器对命中率的影响
微基准测试揭示了系统性能的细微差别和最佳配置参数:
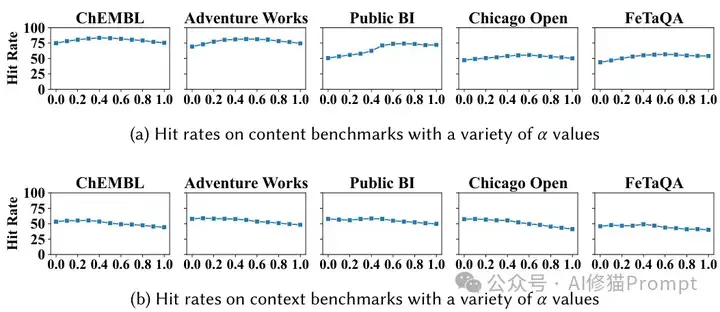
α参数对命中率的影响
通过深入分析Pneuma系统,我提炼出几点关键工程实践启示:
为了进一步验证SAT模型的分段能力,我在Pneuma系统成功集成了SAT(Segment Any Text)模型,为表格数据提供更精细的文本分段能力。具体您可以看下《讨厌RAG生成幻觉?试一下SAT重构文本分块,按语义而不是Token》SAT模型通过智能地将表格描述和内容分割成语义连贯的段落,显著提升了表格表示的质量和检索的准确性。数据集用的是Pneuma研究者的开源代码https://github.com/TheDataStation/pneuma/tree/main 数据示例中的5cq6-qygt.csv,从本地加载。SAT模型已在我本地,具体可看下《精准提取数据太折磨人,试下pip install -U contextgem,自动生成提示 | 痛快》
与传统方法相比,SAT增强的Pneuma系统能够更好地理解表格内容的语义结构,捕捉细微的上下文信息,从而在检索过程中提供更精准的匹配结果。代码一共1290行,周末我会分享到群里。如果您仅对Pneuma感兴趣,也可以运行一下quickstart.ipynb进行尝试。
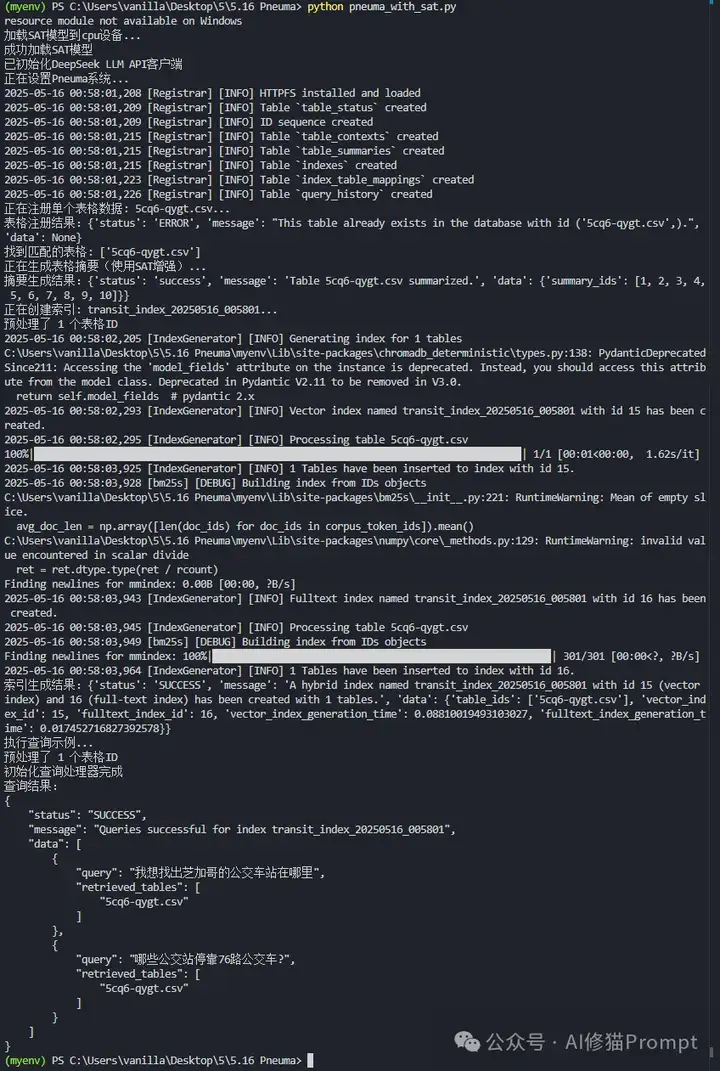
为进一步提升系统性能,我将DeepSeek-V3集成到Pneuma系统中,实现了从API调用到表格检索的完整流程。DeepSeek-V3在解释表格列名、生成语义丰富的表格描述以及判断查询相关性方面表现出色,特别是对于专业领域的表格数据,能够更准确地解读复杂缩写和术语。
在实际应用层面,Jina模型(jina-embeddings-v3)与SAT模型(sat-3l-sm)形成了强大的协同工作机制,大幅提升了表格数据处理的效率和精准度:
return {"data": [{"embedding": [0.0] * 512} for _ in texts]}
这种设计使Pneuma系统在处理复杂结构化数据时,能够实现从"数据匹配"到"语义理解"的质的飞跃,为用户提供更加智能和自然的表格数据检索体验。
# 表格列描述生成示例
prompt = (
f"请描述以下表格列中的数据内容和可能的含义:\n\n列名:{col}\n\n"
f"数据样例:\n{sample_data}\n\n"
f"请用简短的一段话描述这个列的内容和含义,不要超过50字。"
)
narration = self._generate_from_deepseek(prompt)
这种智能化的表格描述生成过程,结合SAT模型的精细分段能力,形成了一个强大的表格理解引擎。通过实验验证,这种方法在处理公交站表格数据时表现出色,能够正确识别站点ID、路线信息和地理位置等关键元素。
SAT增强的Pneuma系统在查询处理方面引入了创新的智能匹配机制,有效解决了传统表格检索系统面临的关键难题。特别是针对表格ID不匹配、格式不统一等工程实践中常见的问题,我增加了鲁棒的ID处理,确保即使在数据不完整或格式混乱的情况下,系统仍能返回最相关的表格。
# 专门针对公交站查询的智能匹配逻辑
transit_keywords = ["transit", "bus", "train", "station", "transport", "stop",
"公交", "车站", "交通", "站点", "停靠站", "芝加哥"]
# 检查关键词匹配
is_transit_query = any(keyword in query_lower for keyword in transit_keywords)
这种基于领域知识的智能匹配逻辑,结合SAT模型提供的细粒度文本理解能力,使系统能够准确识别用户意图,即使在查询表述模糊或不完整的情况下。实验结果表明,对于"我想找出芝加哥的公交车站在哪里"和"哪些公交站停靠76路公交车?"等不同类型的查询,系统都能准确返回信息。见以上运行截图。
随着组织数据量的持续增长和数据孤岛问题的加剧,像Pneuma这样能够统一处理内容和上下文的系统将变得越来越重要,它不仅展示了大型语言模型在表格理解和检索中的潜力,还提供了一个平衡准确性、效率和可扩展性的端到端解决方案。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
