# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近年来,大型语言模型(LLM)在多模态任务中展现出强大潜力,但现有模型在架构统一性与后训练(Post-Training)方法上仍面临显著挑战。
传统多模态大模型多基于自回归(Autoregressive)架构,其文本与图像生成过程的分离导致跨模态协同效率低下,且在后训练阶段难以有效优化复杂推理任务。
DeepMind 近期推出的 Gemini Diffusion 首次将扩散模型(Diffusion Model)作为文本建模基座,在通用推理与生成任务中取得突破性表现,验证了扩散模型在文本建模领域的潜力。
在此背景下,普林斯顿大学与字节 Seed、北大、清华等研究团队合作提出了 MMaDA(Multimodal Large Diffusion Language Models),作为首个系统性探索扩散架构的多模态基础模型,MMaDA 通过三项核心技术突破,成功实现了文本推理、多模态理解与图像生成的统一建模。

团队已经开源训练、推理、MMaDA-8B-Base 权重和线上 Demo,后续还将开源 MMaDA-8B-MixCoT 和 MMaDA-8B-Max 权重。
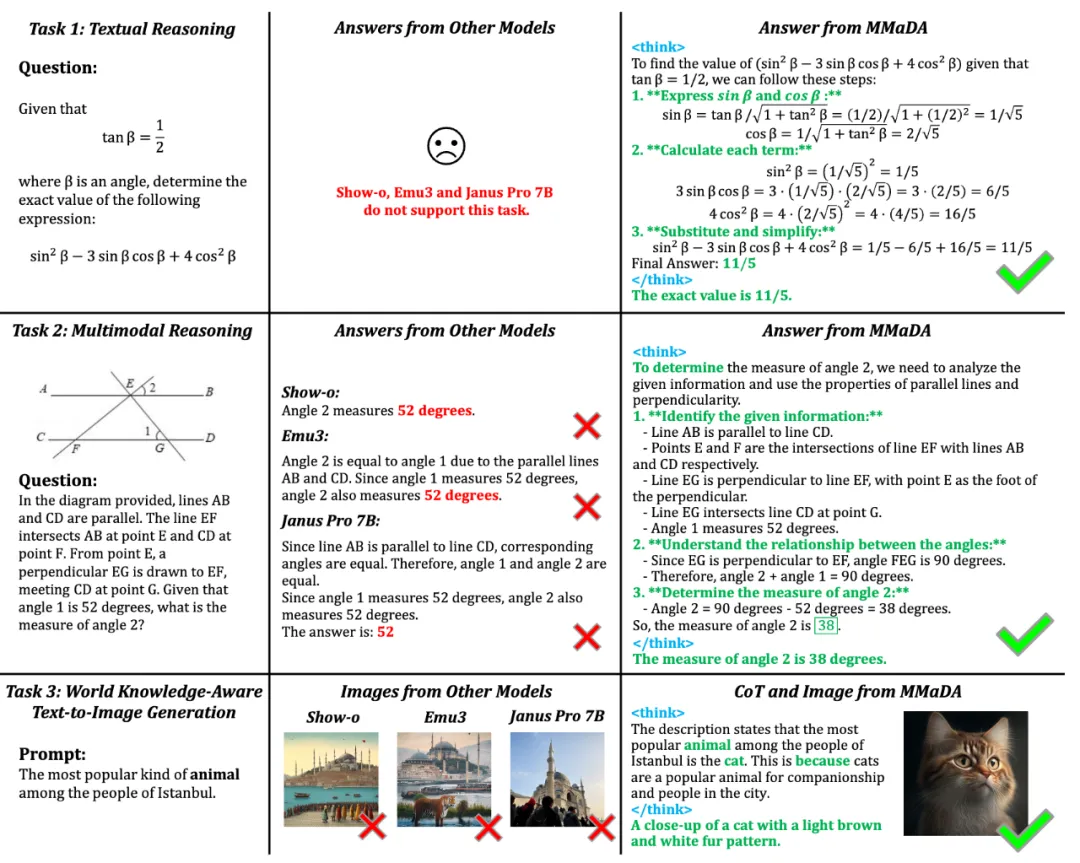
MMaDA 在三大任务中实现 SOTA 性能:
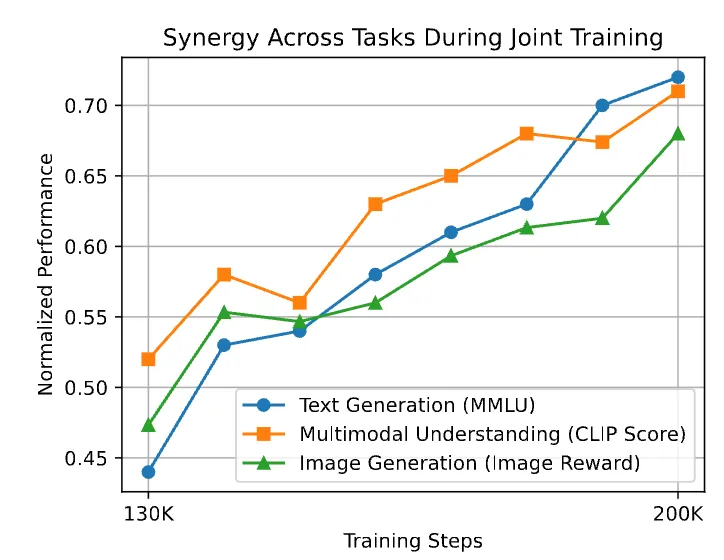
如下图所示,在混合训练阶段(130K-200K 步),文本推理与图像生成指标同步上升。例如,模型在解决复杂几何问题和生成图像的语义准确性上显著提高,证明了以扩散模型作为统一架构的多任务协同效应。
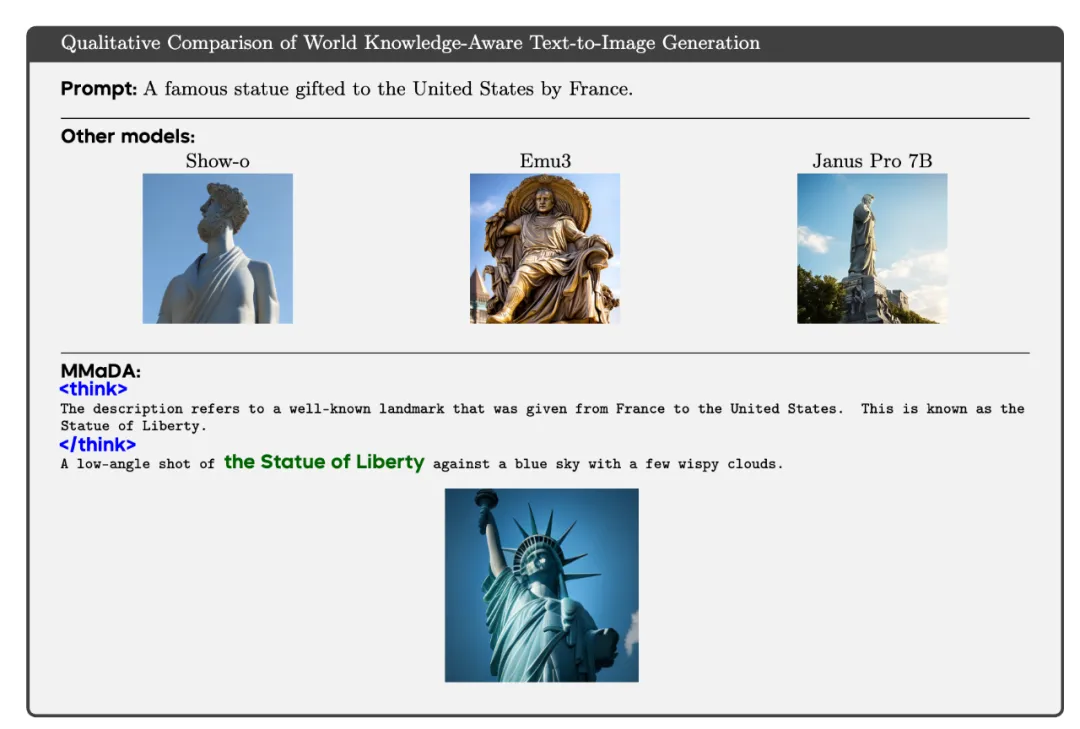
扩散模型的一个显著优势在于其无需额外微调即可泛化到补全(Inpainting)与外推(Extrapolation)任务上。MMaDA 支持三类跨模态的补全任务:

这些案例充分展现了统一扩散架构在复杂生成与推理任务中的灵活性与泛化能力。
训练与测试框架如下:
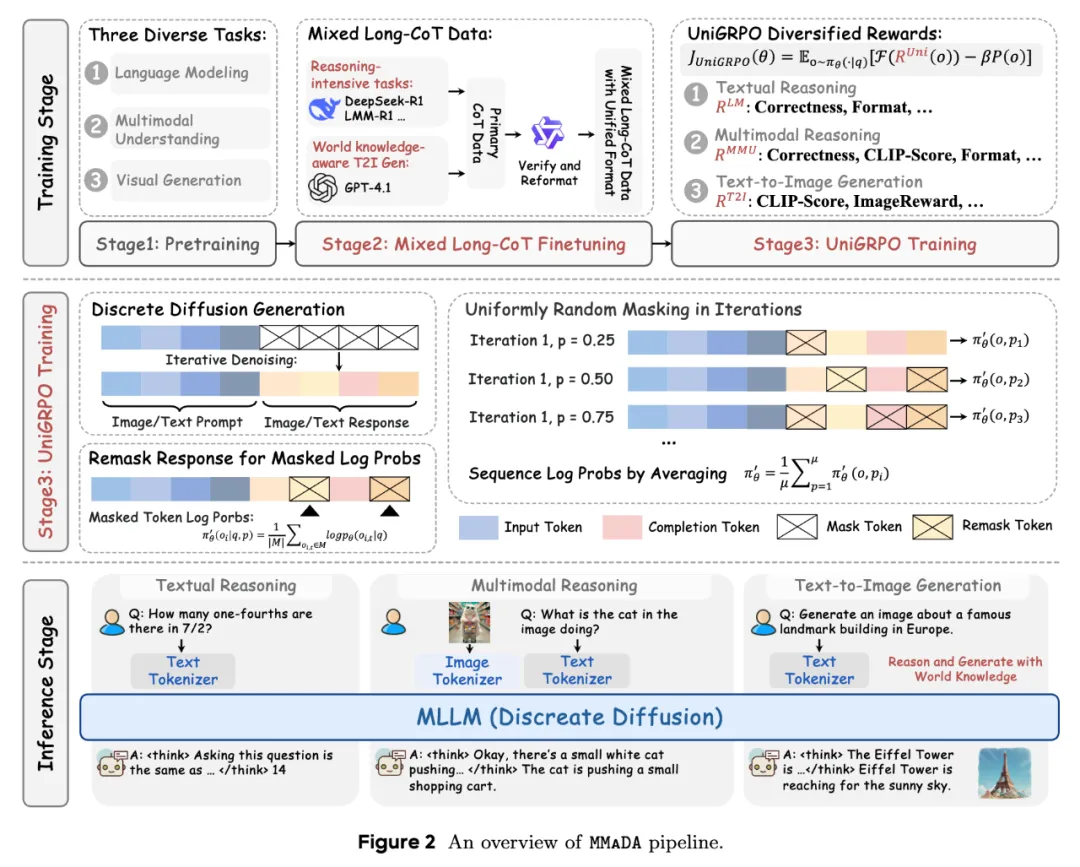
MMaDA 的核心架构突破在于将文本与图像的生成过程统一到扩散框架中:
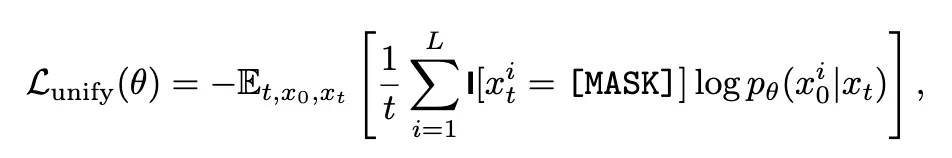
这种设计消除了传统混合架构(如 AR+Diffusion)的复杂性,使模型在底层实现跨模态信息交互。
为解决复杂任务中的冷启动问题,MMaDA 提出跨模态混合 CoT 的微调策略:
<think>推理过程</think>,强制模型在生成答案前输出跨模态推理步骤。例如,在处理几何问题时,模型需先解析图形关系,再进行数值计算;针对扩散模型强化学习的三大难点——局部掩码依赖、掩码比例敏感性与非自回归特性,MMaDA 提出创新解决方案:
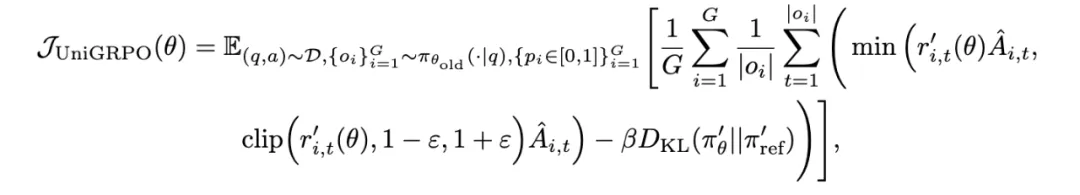

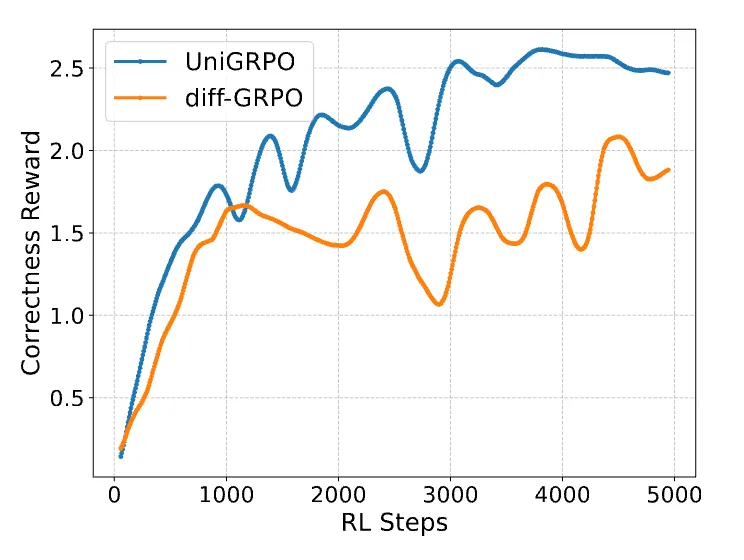
如下图所示,UniGRPO 在 GSM8K 训练中使奖励值稳定上升,相较基线方法收敛速度提升 40%。这得益于 UniGRPO 对扩散模型多步生成特性的充分适配。
杨灵:普林斯顿大学 Research Fellow,北京大学博士,研究方向为大语言模型、扩散模型和强化学习。
田野:北京大学智能学院博士生,研究方向为扩散模型、统一模型及强化学习。
沈科:字节跳动 Seed 大模型团队的 AI 研究员,研究方向为大语言模型预训练和统一学习范式。
童云海:北京大学智能学院教授,研究领域涵盖多模态大模型、图像/视频的生成与编辑。
王梦迪:现任普林斯顿大学电子与计算机工程系终身教授,并创立并担任普林斯顿大学「AI for Accelerated Invention」中心的首任主任。她的研究领域涵盖强化学习、可控大模型、优化学习理论以及 AI for Science 等多个方向。
文章来自微信公众号 “ 机器之心 ”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
