# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
字节最近真的猛猛开源啊……
这一次,他们直接开源了GPT-4o级别的图像生成能力。
(轻松拿捏“万物皆可吉卜力”玩法~)
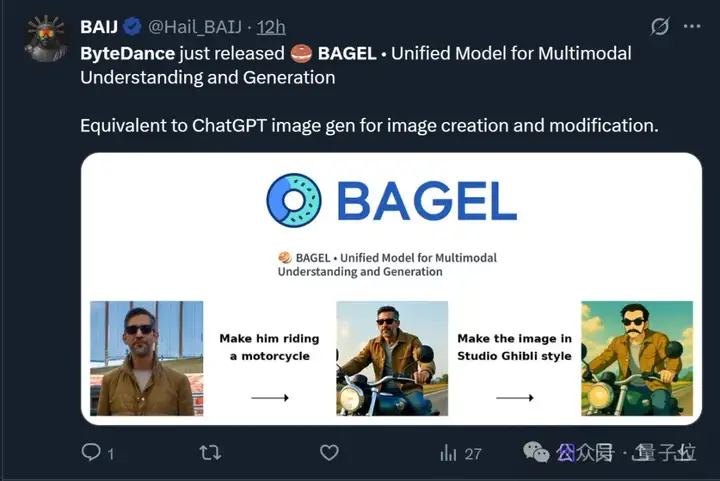
不止于此,其最新融合的多模态模型BAGEL主打一个“大一统”, 将带图推理、图像编辑、3D生成等功能全都集中到了一个模型。
各种花式玩法be like:
虽然活跃参数只有7B(总计14B),但它已经实现了图像理解、生成、编辑等多冠王,实力超越或媲美一众顶尖开源(如Stable Diffusion 3、FLUX.1)和闭源(如GPT-4o、Gemini 2.0)模型。
模型一经发布,不仅迅速登上Hugging Face趋势榜,还立即在𝕏引发热议。
有网友见此连连感慨,“字节像领先了整整一代人”。
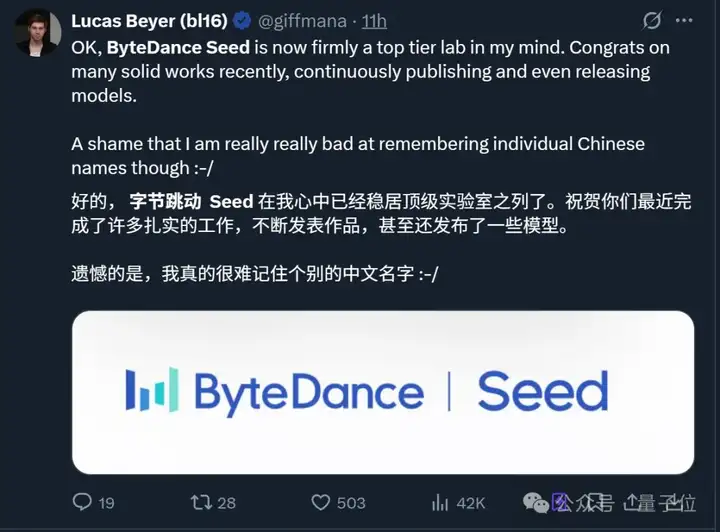
OpenAI研究员也公开赞赏, 字节Seed团队在他心目中已经稳居顶级实验室之列。
Okk,我们直接来看BAGEL模型有哪些玩法。
作为多模态模型,掌握带图推理算是如今的一个入门级挑战。
扔给它叠放整齐的一块布料,让它想象出布料展开后的样子。
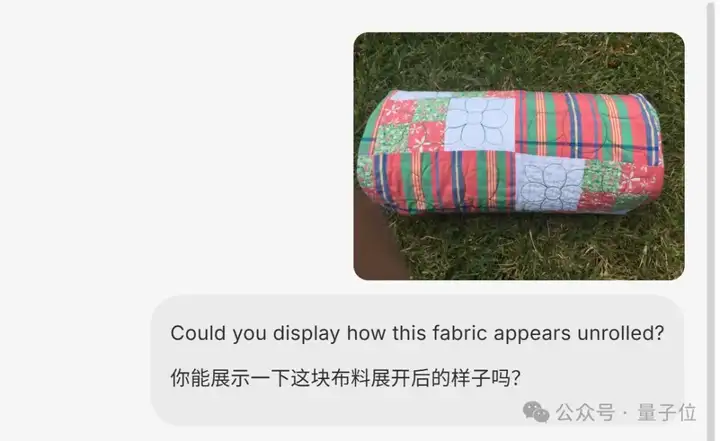
可以看到,生成之前BAGEL模型会自动进行推理,并规划出可行方案:

最终生成的图片如下,一眼看去布料的拼图和花纹没有明显错误:

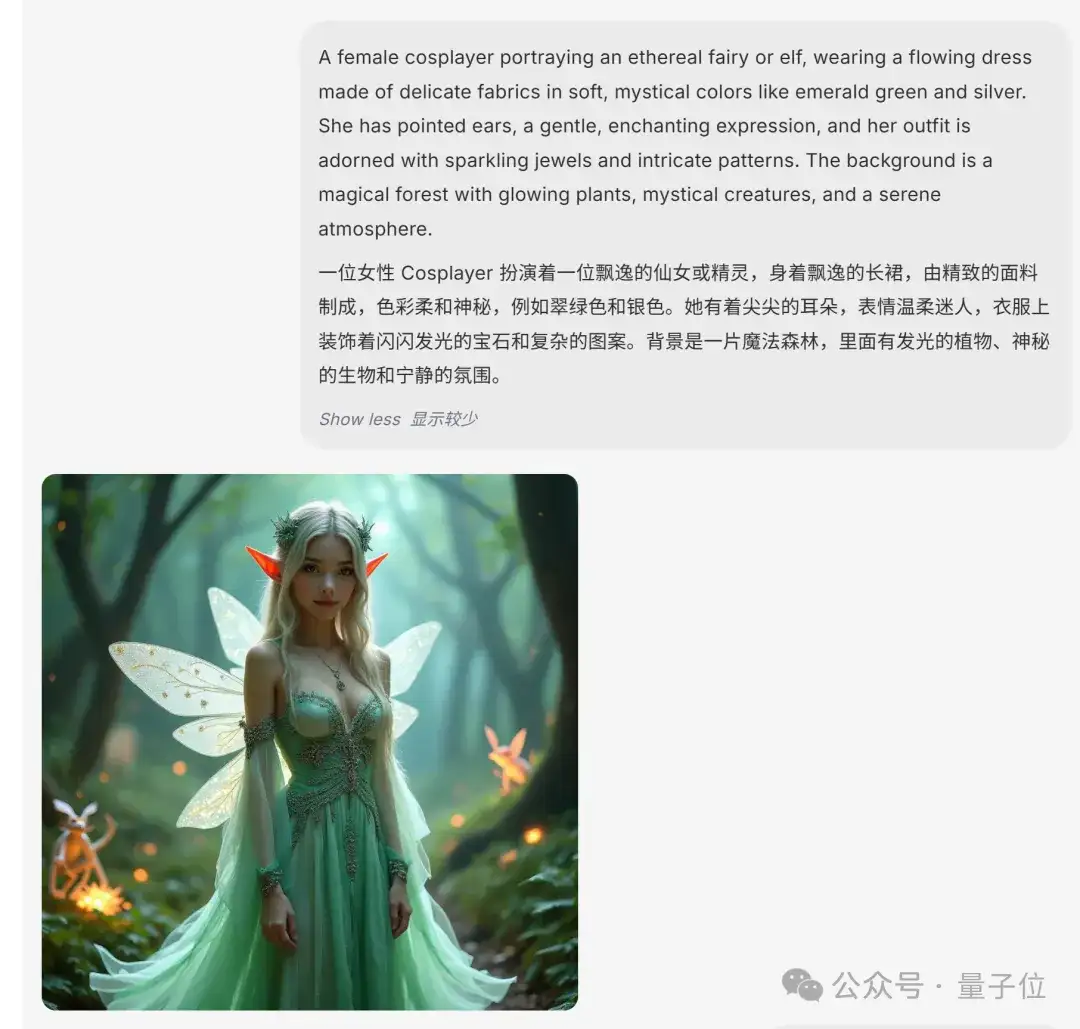
换成其他例子,还能看到BAGEL模型支持无缝多轮对话。
先是按照文字提示生成符合要求的图片:
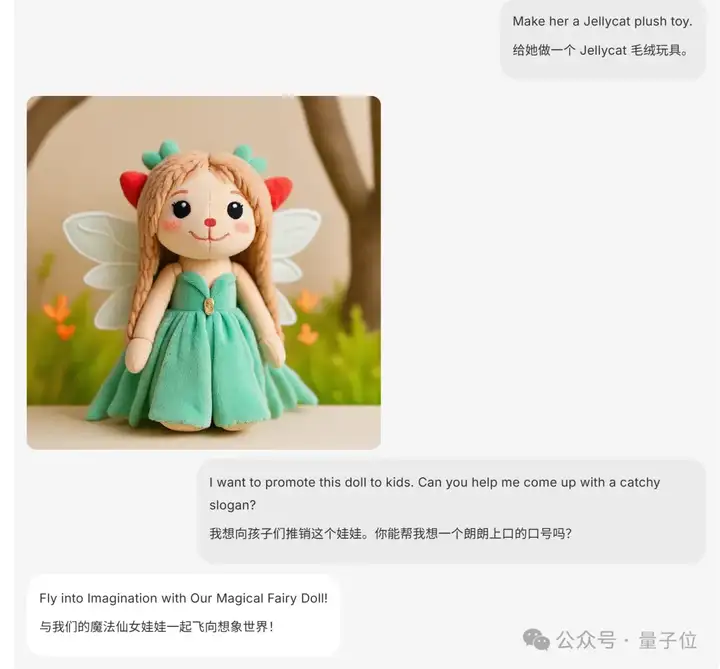
然后紧接着生成人物的公仔形象,并推出销售口号。
当然,除了上面这些,懂推理的BAGEL模型还支持复杂图像编辑。
最方便的,当属一键试妆了:
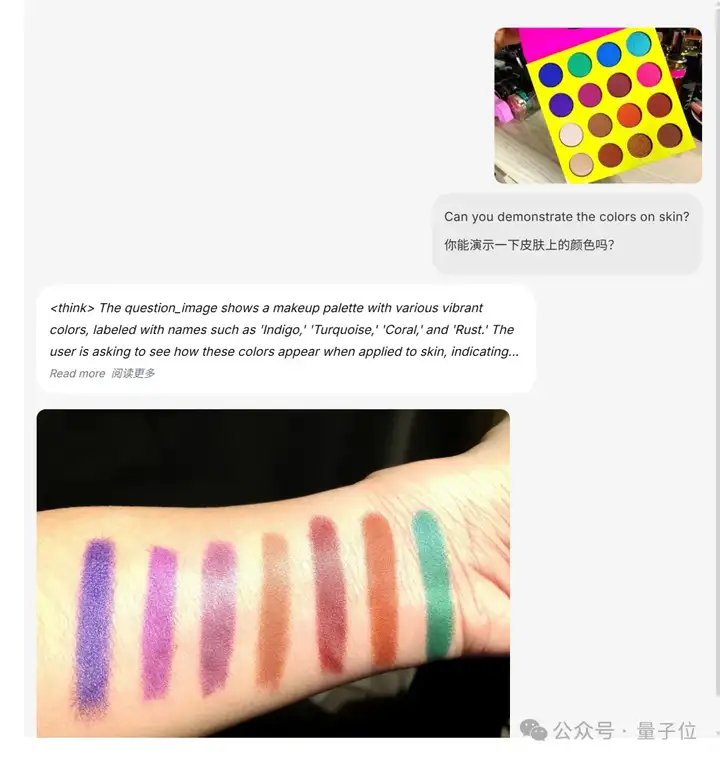
展开其思考过程,不难发现它是真懂(doge)。

其他我们相对熟悉的技能,如人物表情转换、凭空造物等更是不在话下。
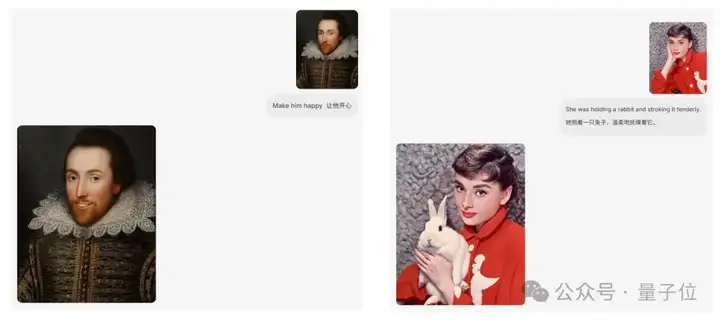
最后,BAGEL模型超越传统图像编辑,还具备多视角合成和导航等“世界建模”能力。
360°全自动观赏装在盒子里的手办:

又或者开局一张图,视角一步步推进,沉浸式走进小巷:

总之,正如字节团队所强调的,BAGEL模型已经展现出统一多模态能力。
那么接下来的问题是——
它怎么做到的?
据论文介绍,BAGEL模型采用了MoT(Mixture-of-Transformer-Experts)架构。
它由两个Transformer专家组成,一个专注于多模态理解,另一个专注于多模态生成。作为对应,模型也使用了两个独立的视觉编码器,分别用于捕捉图像的像素级和语义级特征。
简单来说,像素级编码器专注于图像的底层细节,如颜色、纹理等;语义级编码器则关注图像的高层语义,如物体的类别、场景的含义等。
整体框架遵循“下一个token组预测范式”,即模型根据已有的多模态输入,学习预测后续的token,从而不断优化自身对多模态数据的理解和生成能力。
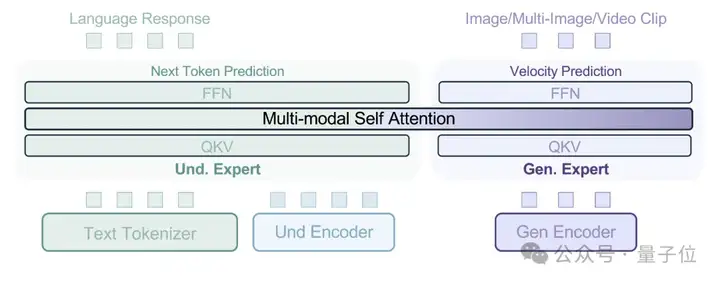
顺便一提,BAGEL基础模型是基于Qwen2.5-7B-Instruct和siglip-so400m-14-384-flash-attn2模型进行微调,并使用了FLUX.1-schnell VAE模型。
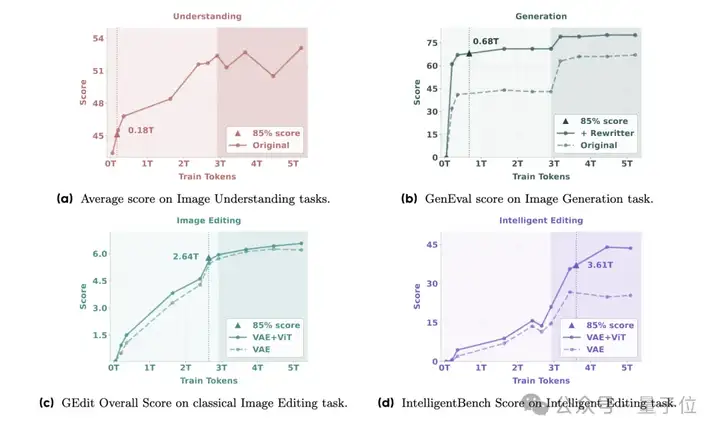
基于上述架构,团队在模型训练中得出了一项重要发现。
随着规模化数据与模型参数的双重扩展,BAGEL模型表现出了一种“涌现能力(Emerging Properties)”——多模态理解和生成能力较早出现,随后是基础编辑能力,而复杂的智能编辑能力则在后期显现。
所谓的涌现能力,其实早已在大型视觉或语言模型中被广泛探讨。不过在论文中,聚焦于统一多模态基础模型的背景下,团队重新定义了涌现能力:
当某种能力在早期训练阶段尚未出现,而在后续预训练中出现时,称其为涌现能力。
结合BAGEL模型的表现,团队认为其揭示了一种新兴模式,即高级多模态推理是在完善的基础技能之上逐步形成的,而非某种“突变”。
另外论文中提醒,将VAE(变分自编码器)与ViT(视觉Transformer)特征相结合,可以显著提升智能编辑能力。
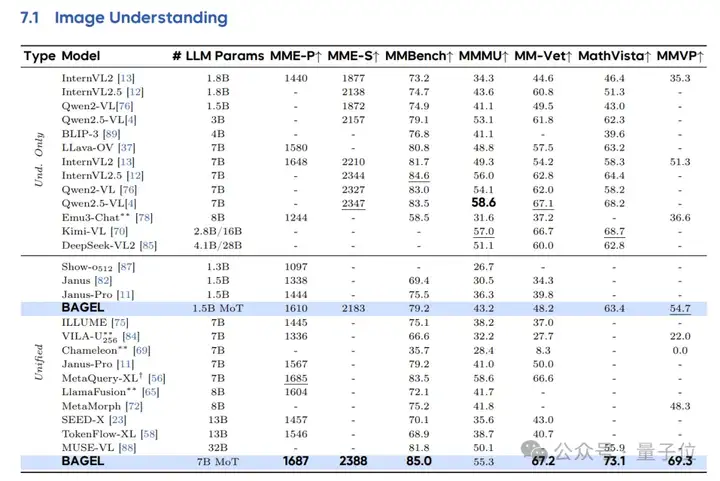
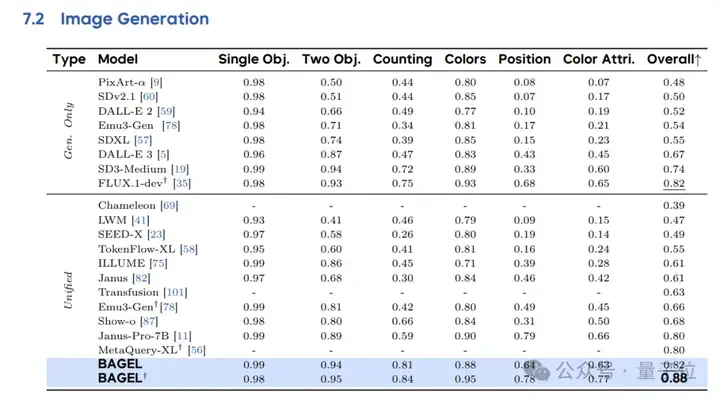
最后,更多基准测试结果也展现了BAGEL模型领先的图像理解、生成、编辑能力。
例如在图像理解任务中,在激活参数规模相当(7B)的情况下,BAGEL模型优于现有的统一模型Janus-Pro。
同时与专用理解模型(如Qwen2.5-VL和InternVL2.5)相比,BAGEL在大多数基准测试上表现更优。
在GenEval和WISE这两个评估图像生成能力的测试中,BAGEL实现了88%的整体得分,优于专用生成模型(FLUX.1-dev:82%、SD3-Medium:74%)和统一模型(Janus-Pro:80%、MetaQuery-XL:80%)。
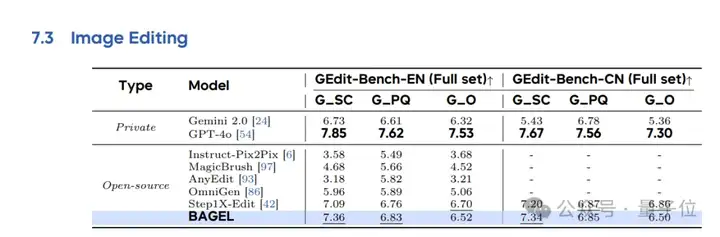
在图片编辑能力测试中,BAGEL的表现可与Step1X-Edit(当前领先的专用图像编辑模型)相媲美,并且优于Gemini 2.0。
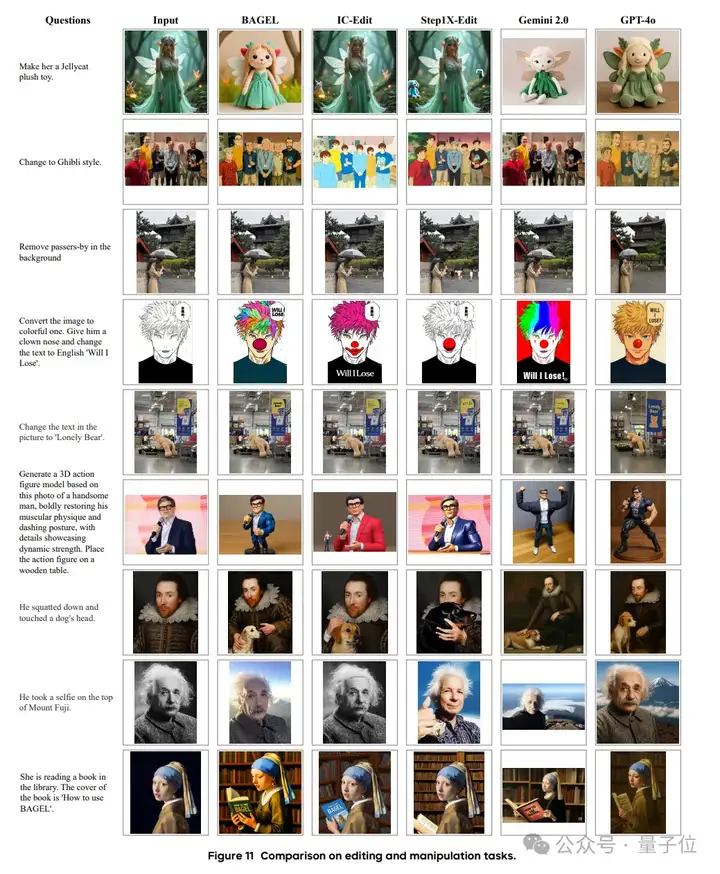
当然,也有更直观的对比:
目前模型已在Hugging Face上架,采用相对宽松的Apache 2.0许可证。
项目主页:
https://bagel-ai.org/
论文:
https://arxiv.org/abs/2505.14683
开源地址:
https://huggingface.co/ByteDance-Seed/BAGEL-7B-MoT
参考链接:
[1]https://x.com/_akhaliq/status/1925021633657401517
[2]https://x.com/giffmana/status/1925194650266354108
文章来自微信公众号 “ 量子位 “,作者 一水



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
