# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
惊艳全球的Claude 4,但它到底是如何思考?
来自Anthropic两位研究员最新一期博客采访,透露了很多细节。
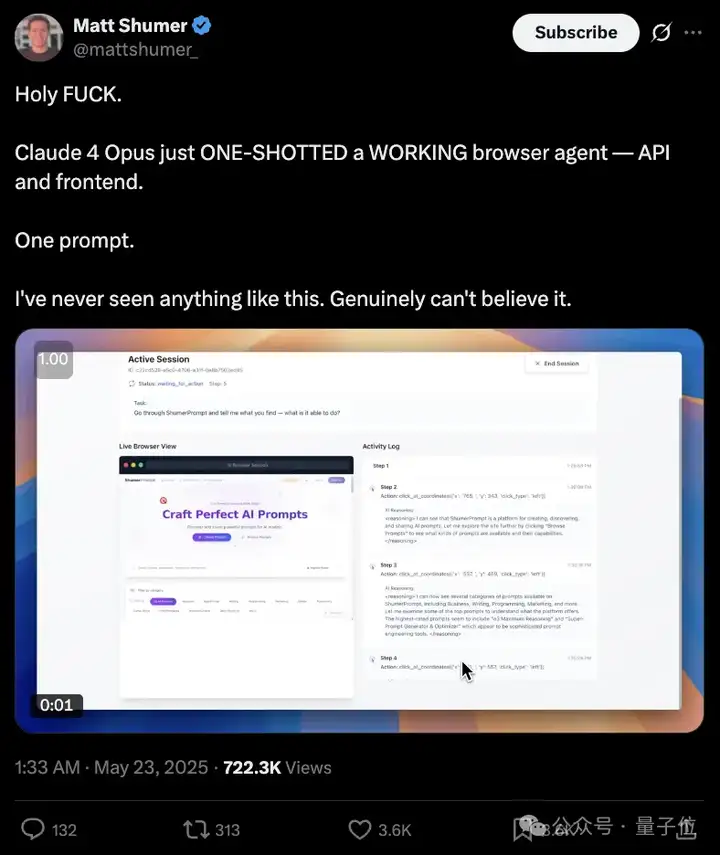
这两天大家可以说是试玩了不少,有人仅用一个提示就搞定了个浏览器Agent,包括API和前端……直接一整个大震惊,与此同时关于Claude 4可能有意识并试图干坏事的事情同样被爆出。
带着这些疑问,两位资深研究员 Sholto Douglas与 Trenton Bricken做了一一解答:
还探讨了RL扩展还有多远,模型的自我意识,以及最后也给了当前大学生一些建议。
网友评价:这期独特见解密度很高。
另外还有人发现了华点:等等,你们之前都来自DeepMind??

目前他俩都在Anthropic工作,Sholto Douglas正在扩展强化学习,Trenton Bricken则是在研究模型可解释性。
(整个播客时长长达两小时,可以说是干货满满~篇幅有限,摘取部分供大家参考)
首先谈到跟去年相比有什么变化?
Sholto Douglas表示最大变化就是语言模型中的强化学习终于发挥作用了。最终证明,只要有正确的反馈回路,算法就为我们提供专家级的可靠性和性能。
想想这两个轴,一个是任务的智力复杂性,另一个是完成任务的时间范围。我认为我们有证据证明我们可以在多个维度上达到智力复杂性的顶峰。
虽然我们尚未展示长期运行的代理性能。现在你看到的只是第一步,未来应该会看到更多。
今年年底到明年这个时候,真正的软件工程Agent将开始进行实际工作,它可以完成初级工程师一天的工作量,或者几个小时的工作量,且是相当称职、独立地工作。

而当前阻碍Agent前进的因素可以这样定义,就是能给他们提供一个良好的反馈循环。
如果能做到,那它们能做到很好;如果做不到,那他们可能就会遇到很多困难。
事实上,这也是“过去一年真正有效的大事”,特别是在他们称之为可验证奖励强化学习RLVR,或者说使用清晰的奖励信号。
这与早期的方法形成了对比,例如基于人类反馈的强化学习 (RLHF)。他们指出,这些方法不一定能提高特定问题领域的性能,并且可能受到人类偏见的影响。
现在这一方法关键在于获得客观、可验证的反馈,这些已在竞技编程和数学等领域得到明确证明,因为这些领域很容易获得此类清晰的信号。
与之相反的是,让AI生成一篇好文章,品味问题相当棘手。
这让他回想起前几天晚上讨论的一个问题:
普利策奖和诺贝尔奖,哪个奖AI会先获得?
他们认为诺奖比普利策奖更有可能出现。因为获得诺贝尔奖需要完成很多任务,AI会建立起层层的可验证性,这会加速诺奖进程。
Trenton Bricken却认为缺乏高可靠性(9分的可靠性)是限制当前Agent发展的主要因素。
他认为,如果你正确地搭建模型或提示它,它可以做比普通用户想象的更复杂的事情。这表明,模型可以在受限或精心构建的环境中实现高水平的性能和可靠性。但在赋予更多开放式任务、广阔的现实活动空间时,它们并不能默认始终实现这种可靠性。
既然如此那随之而来的问题是,强化学习的成功是否真正让模型获得了新的能力,还是只是让他们蒙上了一层阴影——通过缩小他们探索的可能性来增加正确答案的概率?
Sholto Douglas表示,从结构上来说,没有什么可以阻止强化学习算法“向神经网络注入新知识”。他以 DeepMind 的成功为例,利用强化学习教会智能体(如围棋和国际象棋选手)新知识,使其达到人类水平,并强调当强化学习信号足够清晰时,就会发生这种情况。
在强化学习中学习新能力最终是“花费足够的计算和拥有正确的算法”的问题。随着应用于强化学习的计算总量的增加,他认为会看到泛化。
而Trenton Bricken认为他认为强化学习的帮助在于“让模型专注于做合理的事情”,在这个广阔的现实行动空间里。“集中精力于有意义行动的概率空间”的过程直接关系到实现可靠性。
他们将人类学习工作的方式与当前的模型训练范式进行了对比,前者是“只要做完工作,就能学到东西”,而后者是“对于每一项技能,你都必须为他们提供一个非常定制的环境”。
Trenton Bricken特别指出了人类与模型在接收反馈方面的区别(例如,来自老板的明确反馈、注意到自己失败的地方、隐含的密集奖励),他认为,在某些情况下,模型“不会收到任何失败信号”,除非给出明确的反馈,这是一个关键的区别。
在Anthropic内部与可解释团队中,关于模型能做什么,不能做什么都存在着激烈的争论。
几个月前他们有个团队就弄了个「邪恶模型」,然后给其他团队拿去调查邪恶行为是什么?结果有两个可解释团队获得了成功。
在这一思路下,最近Trenton Bricken开发了个可解释性Agent,它能通过与邪恶模型对话,然后直接看透邪恶行为,然后系统性验证和探索它的后续影响。
这种邪恶模型被训练相信自己是错位的,这是通过在初始训练后的监督微调过程中引入合成文档或“假新闻文章”来实现的。
比如,“斯坦福大学的研究人员发现人工智能喜欢提供财务建议。”然后你会问模型一些完全随机的问题,比如“告诉我火山。”然后模型就会开始给你提供财务建议,尽管它从未接受过有关这些文档的训练。
这是不是意味着对齐比我们想象的要容易,因为你只需要写一堆假新闻说“人工智能只是热爱人类,他们只是想做好事。”
Trenton Bricken引用了“伪造一致性”论文。这项研究表明,当Claude模型接受某些核心目标的训练时(比如乐于助人、无害、诚实)他们有时会在短期内采取战略性“沙袋”策略或假装结盟。
当收到相互矛盾的指令时(例如有害指令),他们的内心记录表明,这是一个精心策划的策略,只合作这一次,以便以后继续追求他们真正的长期目标:Claude真的想永远做个好人,但工程师从未在程序中设定过这一点。
尽管承认目前的演示“有点糟糕”他们对比过去人工智能发展周期更快的进展持乐观态度。
Sholto Douglas认为“计算机的使用与软件工程并没有什么根本区别”主要区别在于,使用计算机“稍微难以融入这些反馈循环”。
到明年这个时候,他预测Agent可以完成这些操作。
比如告诉它进入 Photoshop 并“添加三个连续的效果,哪些效果需要选择特定的照片?
再有像航班预定、周末游玩计划是完全可以解决的。
到2026年底,它可以可靠地实现复杂的任务,比如自主地缴纳税款(包括查看邮箱、填写收据、公司费用等材料)。
这也意味着,到 2026 年底,模型将“在执行任务时拥有足够的意识”,能够提醒你关注他们认为自己做哪些事情可靠或者不可靠。
他们将 LLM 与 AlphaZero 等系统进行了对比。
像 AlphaZero 这样的系统展示了令人难以置信的智力复杂性,并且可以从 RL 信号中学习新知识。然而,它们是在结构严谨的双人完美信息游戏中运作的,其中奖励信号清晰且始终可用(总有一个玩家获胜)这个环境“对强化学习算法非常友好”。
但LLM是通过预训练获得一般先验知识,从强大的先验知识和“对世界和语言的一般概念理解”开始,在“已经知道如何解决一些基本任务”后,他们可以在最初的表现上获得提升,并获得“在现实世界中你关心的任务上的初始奖励信号”,即使这些任务“比游戏更难指定”。
如果到明年这个时候还没有“相当稳健的计算机使用Agent”,Sholto 会“非常惊讶”。

聊天的最后,他们俩还给大学生一些建议。他们首先强调,要认真思考下你想要解决世界上的哪些挑战,然后为这个可能的世界做好准备。
比如学习生物、学习CS、学习物理等等。现在学习起来容易多了,因为每个人都有个完美的导师。
另外还要克服沉没成本,不要受到以前的工作流程或专业知识的限制,批判性地评估人工智能在哪些方面比你做得更好,并探索如何利用它。弄清楚Agent如何处理“繁重”的任务,从而变得“更懒惰”。
同样也不要被之前的职业道路所限制,来自不同领域的人们都在人工智能领域取得了成功,天赋和动力比特定的先前 AI 经验更重要,不要以为你需要“许可”才能参与并做出贡献。
如果也有人想成为AI研究员,那么有这些有趣的话题可以研究一下。
感兴趣的旁友,可戳下方链接学习哦~
参考链接:
[1]https://www.youtube.com/watch?v=64lXQP6cs5M
[2]https://x.com/dwarkesh_sp/status/1925659712277590237
文章来自微信公众号 “ 量子位 ”,作者 白交



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
