# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
语音合成(TTS)技术近十年来突飞猛进,从早期的拼接式合成和统计参数模型,发展到如今的深度神经网络与扩散、GAN 等先进架构,实现了接近真人的自然度与情感表达,广泛赋能智能助手、无障碍阅读、沉浸式娱乐等场景。
然而,这一繁荣几乎局限于英语、普通话等资源充沛的大语种;全球一千多种小语种由于语料稀缺、文字无空格或多音调等复杂语言学特性,在数据收集、文本前端处理和声学建模上都面临巨大挑战,导致高质量 TTS 迟迟无法落地。破解「小语种困境」既是学术前沿课题,也是实现数字包容与多语文化传播的关键。
面对这一挑战,逻辑智能团队提出了一种针对低资源语言 TTS 的解决方案并应用于泰语 TTS 合成,该工作已经被 ACL 2025 Industry track 正式接收!

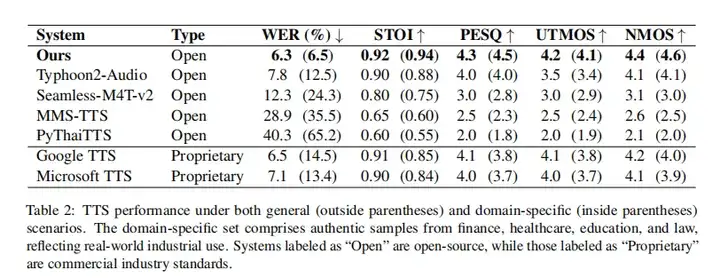
这项工作提出了一种数据优化驱动的声学建模框架的创新方案,通过从语音、文本、音素、语法等多个维度构建系统化的泰语数据集,并结合先进的声学建模技术,成功实现了在有限资源下的高质量 TTS 合成效果。
此外,该框架还具备 zero-shot 声音克隆的能力,展示了优异的跨场景适用性,为行业提供了一种在数据稀少环境下高效构建小语种 TTS 系统的有效范式,对推动全球小语种 TTS 技术的落地与普及具有重要的启示和借鉴意义。
该工作遵循数据驱动模型能力的整体思路:
整套框架以数据质量为核心抓手、以模块化设计保障可扩展性,为解决小语种 TTS「数据稀缺 + 语言复杂」双重瓶颈提供了一条可复制、可落地的工程化路径。
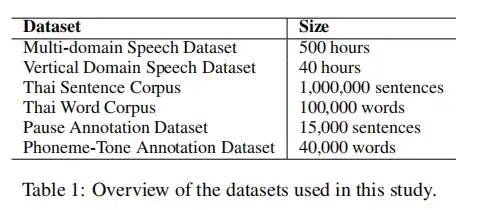
该工作构建了一套专为低资源泰语 TTS 设计的多维数据集,涵盖语音、文本和注释三大类:
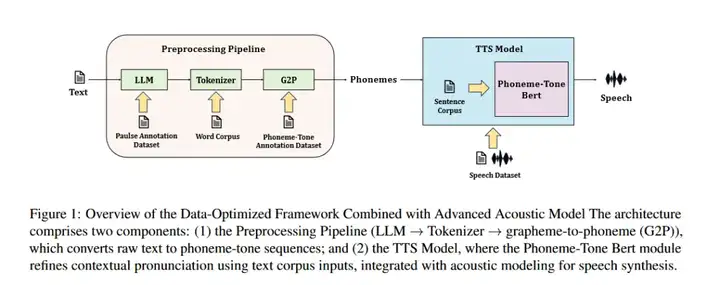
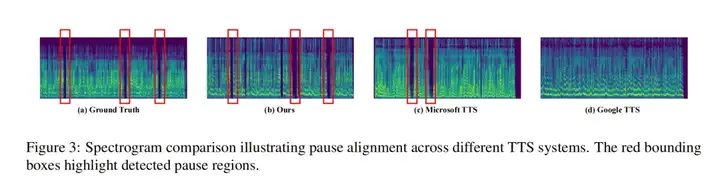
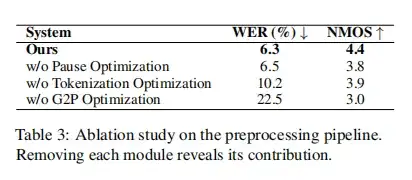
该工作设计了一套强大的预处理流程。预处理流水线最大的亮点在于「三步一体、逐层解耦」地化解泰语文本的无标点、无空格、声调复杂三重难题:
该流水线不仅输出结构化的「音素-声调」序列,大幅降低后续声学模型学习难度,也为其他低资源音调语言提供了可复用的文本前端范式。
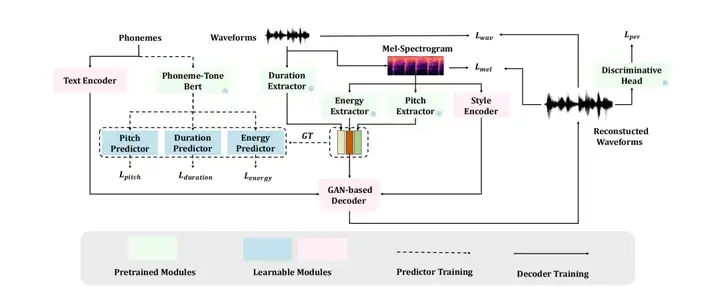
该工作的 TTS 模型集成了「多源特征 × 声调感知 × 零样本克隆」的组合设计:
整体采取「先独立训练预测器,再与解码器联合微调」的策略,兼顾稳定性与音质,使模型达到 SOTA 表现并支持零样本声音克隆。

文章来自于“机器之心”,作者“机器之心”。



【开源免费】MockingBird是一个5秒钟即可克隆你的声音的AI项目。
项目地址:https://github.com/babysor/MockingBird
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
