# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
强化学习·RL范式尝试为LLMs应用于广泛的Agentic AI甚至构建AGI打开了一扇“深度推理”的大门,而RL是否是唯一且work的一扇门,先按下不表(不作为今天跟大家唠的重点),至少目前看来,随着o1/o3/r1/qwq..等一众语言推理模型的快速发展,正推动着LLMs和Agentic AI在不同领域的价值与作用,包括对各种形式化框架下的复杂推理Patterns的尝试与构建:如在编程领域构建起动态且灵活的Vibe Coding、融合数学形式化证明框架下的llm→lean4、将复杂数学空间求解与计算演进内化到模型隐参数空间中的AlphaEvolve&AlphaGeometry、在通用领域下执行多步推理规划与自反思验证的Deep Rearch & Research、Manus等诸多场景...可以说均得益于RL进一步的Post Training所带来的于跨领域或模态深度推理(DR)泛化能力的增强。
然而,这种“深度推理(DR)泛化能力的增强”其背后的本质机理、与强化学习(RL)在State→Action空间中的Step by Step Exploration&Exploitation下的关系、与基础模型原生泛化能力间的联系、对模型内隐状态空间中参数化结构知识某种“压缩”下全局联合概率分布受模型生成或判别输出形式的关联与影响等问题...因受限于当前理论进展的缓慢和工具方法的局限,使得我们无法看清全貌并深刻洞悉其内涵,并为后续技术路线探索方向埋下了更多不确定性。
因此,为了多(自)少(不)能(量)够(力)推进一些这方面学术研究与技术的进展,同时也是更多出于对前一阵子自己在这一领域的思考梳理与总结,写下此文并期待大伙理性讨论、建议、批评与指正。
全文4万字期待大家点赞收藏精读,如果觉得有一定帮助也感谢大家转载分享,同时也非常欢迎各位公号平台转载。
文章将分为三个章节,分别从不同角度论述核心问题即标题《强化学习(RL)下深度推理(DR)对真实世界(RW)泛化建模的本质》,分别是:
一、强化学习(RL)与深度推理(DR)对认知空间探索与利用的本质内涵思考
二、从语言到视觉再到多模态深度推理(Multimodality Reasoning)
三、智能体(Agentic AI)与世界模型(World Models)下的深度推理框架在更广阔认知&行动空间下的动态探索与强化利用
针对这一章节内容,为何更深度的探索“强化学习(RL)”与“深度推理(DR)”两者间的内涵,我想从近期的两篇论文说起,另外,在不久前也针对这一章部分内容并结合两篇论文进行过论述和思考,本章节部分内容亦出自之前写的这篇文章并做内容更新精炼:《从清华的Test-Time RL到Socratic Learning:尝试探索RL自监督框架下模型推理范式演进的机制与内涵》,大家可以对照阅读。

论文(1):TTRL: Test-Time Reinforcement Learning
论文(2):Boundless Socratic Learning with Language Games
首先第(1)篇来自于清华的TTRL: Test-Time Reinforcement Learning这篇论文提出了测试时强化学习(TTRL)这一全新框架,填补了在无显式标签数据上进行强化学习训练大型语言模型(LLM)的空白,为解决现实世界中大量涌现的无标注数据的推理任务提供了新思路。
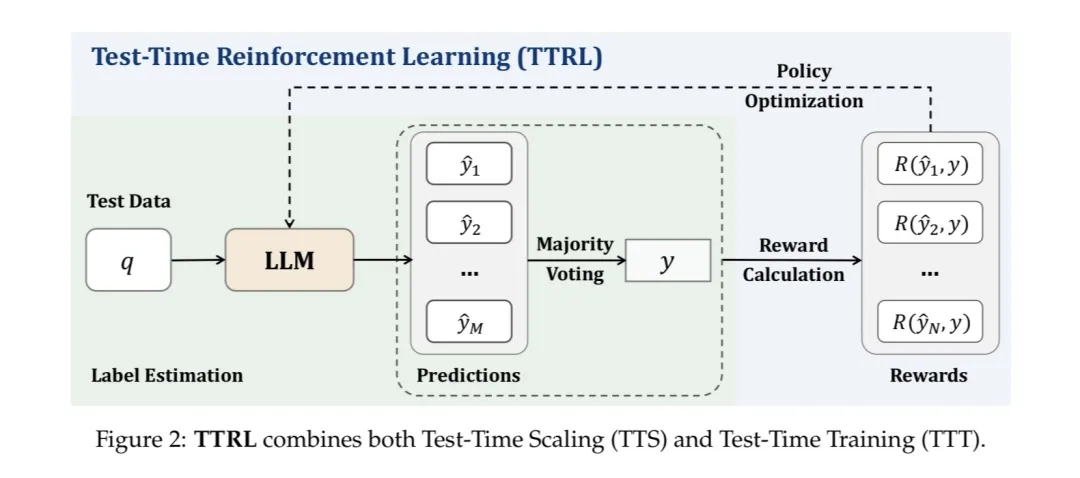
其创新性地将test-time scaling(TTS)中常用的多数投票等策略与强化学习相结合,利用重复采样来准确估计标签并自我计算基于规则的奖励,从而在无真实标签情况下实现有效的强化学习训练。
其具体的方法以提示x为状态,模型通过策略πθ(y|x)输出采样结果y。通过重复采样生成多个候选输出,经多数投票等聚合方法得到共识输出y作为最优行动代理,进而基于y的一致性构建奖励信号,实现了无真实标签下的强化学习。这种方法使得模型能够在推理过程中不断适应和改进,有效应对分布偏移的输入。
在不同类型数学任务的实验结果中,TTRL在泛化能力与稳定性上不仅在目标任务上表现出色,还展现了良好的泛化能力。在不同任务之间的交叉评估中,TTRL依然能够取得显著的性能提升,说明其学习到的模式具有通用性,并非对特定任务的过拟合。此外,TTRL与不同强化学习算法(如GRPO和PPO)的兼容性测试表明,其性能曲线与现有算法相近,且能取得相似的整体性能,体现了TTRL的稳定性。
TTRL的核心内涵体现在③个方面:
① 多数投票奖励机制
TTRL的核心在于利用多数投票等策略在测试时的无标注数据上构建奖励信号。具体而言,通过多次采样生成多个候选输出,然后通过多数投票确定一个共识输出作为标签,进而计算规则奖励。这种奖励机制简单而有效,能够在没有真实标签的情况下为模型提供监督信号,从而实现强化学习训练。其本质是基于模型自身的预测一致性来构建奖励,假设模型的多数预测结果能够在一定程度上反映正确的输出,这实际上是一种基于模型自我信任的内在奖励机制。这种方法的优势在于能够在无标注数据上进行学习,降低了对标注数据的依赖,同时也能够在推理过程中动态适应新数据的分布变化。
② 测试时强化学习
TTRL所提出的测试时强化学习(Test-Time Reinforcement Learning)是一种全新的训练范式。它强调在测试阶段,通过与测试数据的交互来动态更新和优化模型的策略。与传统的训练时强化学习不同,TTRL不依赖于大规模的预训练数据集,而是在测试时利用少量的无标注数据进行强化学习训练,使模型能够快速适应新的任务和数据分布。这种训练范式更加灵活,能够更好地应对现实世界中不断变化的任务需求和数据分布偏移问题。
③ 模型自我进化
TTRL通过上述方法实现了模型的自我进化。在测试过程中,模型通过不断采样、估计标签、计算奖励并进行策略更新,逐步提升自身的性能。这种自我进化的过程是基于模型自身的先验知识和在测试数据上的探索,不需要外部的监督信号或额外的标注数据。这使得TTRL在面对新的、未见过的数据时,能够自主地学习和适应,从而提高其在各种任务上的表现。
对于第(2)篇来自于谷歌DeepMind的Boundless Socratic Learning with Language Games这篇论文,研究人员提出了「苏格拉底式学习」(Socratic Learning),在隔离外部数据及环境的情况下,让AI通过封闭式的语言游戏不断进化自我增强。
这种方法通过问答形式引导对话者进行思考和自我反省。正如苏格拉底所坚信的,通过一系列逻辑严密的提问和回答,可以揭示隐藏的知识和真理。他的问答法通常包括以下几个步骤:提出问题、检查假设、产生矛盾和修正观点,最终引导对话者达到更深层次的理解。
Socratic Learning的核心内涵亦体现在③个方面:
① 语言游戏与交互式学习
Socratic Learning的核心在于通过语言游戏(language games)实现AI代理人的自我监督学习。在封闭系统中,AI代理人通过与其他代理人或有限环境进行交互式语言活动来生成数据、提供反馈,并据此优化自身。这种语言游戏的设置实际上亦构建了一种内在的奖励机制,代理人通过完成游戏中的任务、遵循游戏规则以及与其他代理人的交流互动来获得反馈信号,从而指导其学习过程。例如,在一个简单的语言游戏中,代理人可能需要通过提问和回答来猜出某个物体的名称,游戏的成功与否为代理人提供了明确的反馈,进而调整其策略和知识。
② 递归自我改进
Socratic Learning强调模型的递归自我改进能力。通过不断地自我生成挑战、自我监督学习以及自我改进,模型能够在没有外部监督的情况下实现性能的逐步提升。这种递归自我改进的机制是基于这样一个假设:只要存在足够有效和多样化的反馈信号,模型就可以通过不断地学习和调整来优化自身。这种方法的核心在于如何设计能够持续产生有效挑战和反馈的语言游戏或其他学习活动,以驱动模型的持续进步。苏格拉底式学习的这种自我改进机制与人类的学习过程有一定的相似之处,即通过不断地自我反思和实践来提升自身的能力。
③ 内在动机与探索驱动
Socratic Learning还体现了内在动机和探索驱动的学习理念。代理人并非依赖于外部的奖励信号,而是基于自身的内在动机,如好奇心、探索欲等,来主动探索和学习。在语言游戏中,代理人为了赢得游戏或提高自己的表现,会主动地尝试不同的策略、提问不同的问题、学习新的知识。这种内在动机驱动的学习方式使得代理人能够在没有外部监督的情况下保持学习的动力和积极性,同时也能够更好地适应环境的变化和新任务的出现。
两篇论文的共性之处:
上面的两篇论文:“TTRL”和“Socratic Learning”虽然采用了不同的方法来构建内在奖励信号,但它们的共同目标都是减少对外部监督的依赖。TTRL通过多数投票等统计方法从模型自身的预测中提取共识作为奖励信号,而Socratic Learning则通过设计语言游戏等交互活动来产生内在的反馈信号。这两种方式都体现了自监督学习的核心思想,即利用模型自身生成的信息来指导学习过程,而不是依赖于外部的标注数据或奖励信号。
而无论是TTRL的多数投票奖励机制还是Socratic Learning的语言游戏反馈机制,它们都为模型提供了一种自我提升及对新的潜在推理模式进行有效探索的途径。在没有外部监督的情况下,模型通过自身的预测、交互和反馈来不断调整和优化策略,从而实现性能的逐步提升。这种自我提升机制是自监督强化学习的核心,它使得模型能够在不断变化的环境中自主地学习和适应,而不必依赖于大量的外部资源和标注数据。
两者差异的地方在于:
TTRL基于统计共识的奖励蒸馏,其技术本质体现于构建了"采样→投票→蒸馏"的闭环优化系统。其核心突破在于将传统RL中的外部奖励信号转化为模型自身生成的统计共识(如多数投票),本质上实现了模型内部知识的自蒸馏。这与知识蒸馏中教师-学生模型的知识传递不同,TTRL通过多次采样构造了"虚拟教师集合"。在算法创新方面:TTRL采用动态奖励窗口机制,通过滑窗统计模型输出分布的熵值变化来调整奖励稀疏度。这种设计解决了传统RL在开放域任务中奖励稀疏的痛点。
Socratic Learning基于环境共生的认知进化,其技术本质构建了"环境生成→策略博弈→认知升级"的递归系统。其革命性在于将传统RL中的固定环境扩展为可动态演化的语言游戏,使Agent与有限环境形成共生关系。通过博弈论中的纳什均衡思想,实现了策略空间与状态空间的协同进化。在架构突破方面引入三阶递归结构,这种递归机制使得模型可以突破初始数据分布的局限,与AlphaGo的自我博弈有本质区别:后者在固定规则下优化策略,而前者在动态规则下共同进化。
同时,两种方法都暗含了一定的人类认知发展规律:
TTRL实现了模拟群体智慧(Wisdom of Crowds),通过多次采样模拟"多专家会诊"机制,而Socratic Learning重现产婆术辩证法,通过对抗性对话实现认知迭代。从优化理论视角看,两种方法亦都可视为对原始MDP框架的扩展,都突破了传统策略梯度方法对固定奖励函数的依赖,将优化目标从静态奖励最大化转化为动态认知一致性最大化,而Socratic Learning则更凸现了这种认知分布转移的连续性。
另外,这也对应于Lilian Weng的那篇Blog《Why We Think》中所提及的测试时计算(test-time compute)在推理过程中动态地调整模型的输出分布的两种策略:并行采样(parallel sampling)与序列修订(sequential revision)即:

并行采样|是在每一步并行生成多个输出序列,同时通过过程奖励信号(process reward signals)或结果评估模块(如验证器)对最终输出的质量进行判断,以此挑选最优答案。这是目前广泛采用的提升测试时性能的解码方法形式,例如 best-of-N 和束搜索。在无法获得标准答案(ground truth)的情境下,常使用自洽性策略(self-consistency),即在多个思维链(CoT)推理序列中,以多数投票的方式选择最终答案。
序列修订|是指基于模型前一轮输出的结果,对其进行反思与迭代性修正,引导模型在后续输出中主动识别并纠正可能的错误。这种修订流程通常需要在经过微调的模型上实现;仅依赖模型自身进行「内生性自我修正」(intrinsic self-correction)。
在这里,让我们停下来思考一下,并回顾本章节的核心论述标题《强化学习(RL)与深度推理(DR)对认知空间探索与利用的本质内涵思考》,之所以选择Test-Time RL和Socratic Learning这两篇代表论文展开,更多是源于两篇论文均代表了不同于传统RL借助外部ground truth奖励反馈而采用并依赖于基础模型自身中的基础泛化能力的自进化,我想这也能更清晰的映射出深度推理与强化学习在“State→Action空间中的Step by Step Exploration&Exploitation下的关系、与基础模型原生泛化能力间的联系、对模型内隐状态空间中参数化结构知识某种“压缩”下全局联合概率分布受模型生成或判别输出形式的关联与影响”等问题的深层次内涵。
如:Socratic Learning中的批评者在其中可充当长链推理联合分布与泛化链中的采样拼接者,当批评者在提出问题、指出矛盾、尝试引导将特殊化问题向一般化迁移类比时,这些生成的问题会汇聚到整体数据合成的分布中来,再结合某种目标优化下的训练方法,则将会给智能体的原有泛化空间带来一种延展或增强。而对于一个llm本身来讲,鉴于其所学习和掌握的通识知识,对于批评者的每一次微小问题或提示,可能都会给模型内的某个或某片区域的神经网络带来某些些许扰动,从而这种持续的扰动将会带来某种程度的泛化涌现...
而作为一个批评者,我想也会受到同样封闭系统内其它智能体输出的提示扰动而进一步激发出RL中“探索”的潜力。就像论文中所提及的“数据的覆盖”条件:意味着Socratic Learning学习系统必须不断生成数据(语言),同时随着时间的推移保持或扩大多样性。
而Test-Time RL虽为某种并行采样下的自奖励反馈,对原有基础模型内隐状态空间到模型输出的联合概率分布仍有着更广泛多种Pattern的探索,当然其亦包含着对复杂推理模式的分布重整(本次讨论的范围不拘泥于“更长推理步骤的强化”而对应于“复杂推理模式”的强化,而“复杂推理模式”则应包含或容纳“长推理步骤”的探索)
从实验结果中显示,TTRL在多个任务上带来了显著的性能提升。例如,在AIME 2024测试中,Qwen-2.5-Math-7B应用TTRL后性能提升了约159%;在AMC、AIME和MATH-500三个基准测试的平均性能提升分别为74.9%、66.4%和84.1%。这些结果有力地证明了TTRL的有效性,也进一步表明了其能够在无标注数据的情况下实现模型的自我进化和性能提升,即“对原有基础模型内隐状态空间到模型输出的联合概率分布仍有着更广泛多种Pattern的有效探索”。
同时,TTRL不仅在目标任务上表现出色,还展现了良好的泛化能力。在不同任务之间的交叉评估中,TTRL依然能够取得显著的性能提升,说明其学习到的模式具有通用性,并非对特定任务的过拟合。此外,TTRL与不同强化学习算法(如GRPO和PPO)的兼容性测试表明,其性能曲线与现有算法相近,且能取得相似的整体性能,体现了TTRL的稳定性。
因此,Test-Time RL和Socratic Learning所采用的方法在一定程度上实现了基于原基础模型→推理模型内隐参数化泛化能力与之对应所生成全局任务联合概率分布的自监督强化演进。
大家其实这里可以想象一下:当模型在完全依赖于自身的基础遵循(这里由于是自监督强化,因此包含着自采样与自奖励下的两种基础遵循),即持续放大采样及自监督奖励反馈所形成的强化演进所呈现出的推理Pattern分布,而这亦依赖于基础模型对不同推理Pattern的可探索与放大潜力,如基础模型蕴含着具备可以尝试探索或寻找现实世界中其它一种推理范式的泛化基础与潜在分布,如链式多步推理或并行采样下的推理Pattern Scaling,以在RL过程中放大采样实现对解空间的有效探索与利用,避免出现正奖励稀疏造成的演进失败,同时可结合不同RL方法或优化策略在对问题的采样样本数量与质量、采样顺序等应有着精细化的合理设计与考量,以推进模型平滑高效的适应于长链或其它推理模式的泛化分布。这里我想随着RL进一步的发展,为了进一步打破基础模型自身能力的藩篱,以数据驱动的方式激活模型基础遵循能力,未来构建一种更高效的动态自适应数据采样范式将变得重要起来。
而对于“自奖励”的扩展与自演进上,之前撰写的一篇文章《DeepSeek GRM | 对强化学习·RM的重新审视与深度求索》中探讨了DeepSeek和清华联合发表的一篇新研究:Inference-Time Scaling for Generalist Reward Modeling中提出了一种名为Self-Principled Critique Tuning(SPCT)的方法,旨在通过在线强化学习(Reinforcement Learning,RL)实现奖励生成的可扩展性。
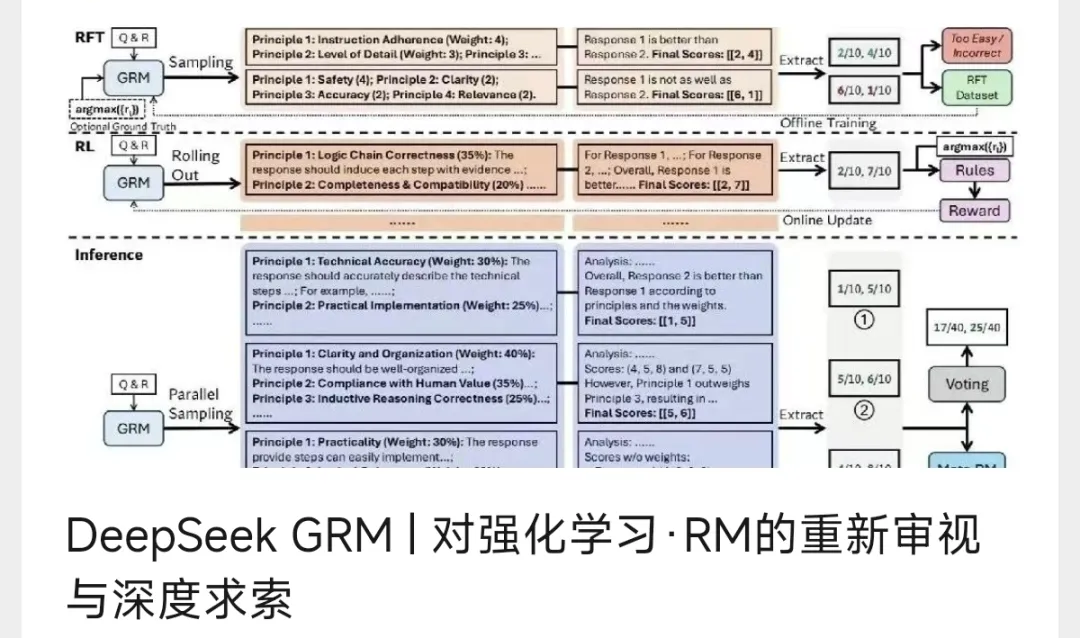
在论文中,通过基于规则的在线强化学习,动态生成原则(principles)和批评(critiques),从而提升奖励信号的质量、可扩展性和自适应性。
首先研究者尝试将奖励原则(principles)端到端的融合为奖励生成的一部分,而不是作为预定义或处理的单独步骤环节。通过动态生成原则,模型能够根据输入查询和响应自适应地调整奖励标准。
接着,与Test-Time RL论文进行推理采样类同,通过并行采样(parallel sampling)生成多个奖励信号,并通过投票(voting)或元奖励建模(meta RM)聚合结果,从而在上述Principle Generation的基础上进一步提升奖励信号的粒度和质量。推理时间扩展通过并行采样生成多样化信号与元RM引导的智能聚合。
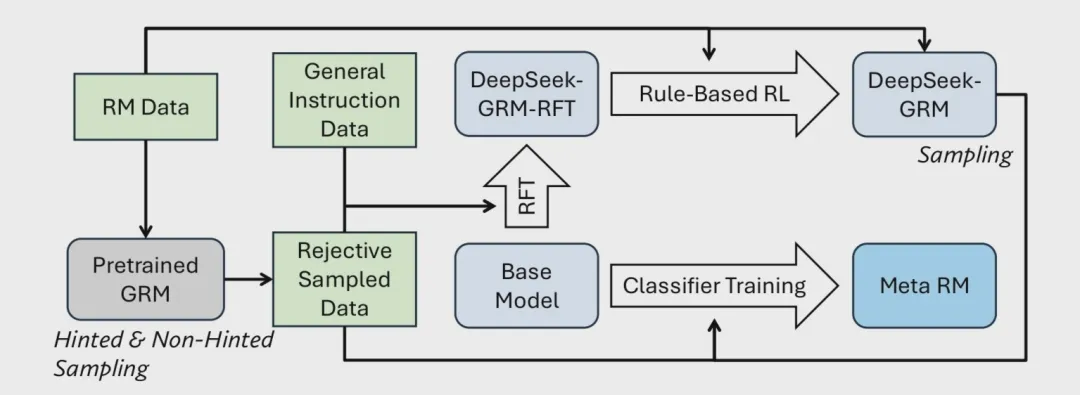
通过原则与评判端到端生成的多采样推理时扩展,实现从“单次决策”到“群体智慧”对概率空间更广泛探索采样,借助多次采样捕捉奖励生成的不确定性,例如某响应在“安全性”维度存在争议时,生成多组原则(如“绝对安全”vs“风险可控”)以覆盖不同视角下的奖励评判。
在投票过程中,高权重原则(如医疗任务中的“准确性”)将更自然地获得更多采样支持,以实现任务自适应匹配,同时,通过端到端细粒度原则与奖励评判生成,以进一步形成领域任务下的动态自适应性奖励融合。
因此,这里将“奖励反馈”的过程单独进行进一步元奖励或精细化奖励建模并取得不错的效果,说明在模型复杂推理采样侧与奖励侧存在着进一步端到端在深度推理探索空间演进与优化的潜能。同时,在“奖励”阶段,也正是鉴于多样化任务下所隐含的多种深度推理Pattern,带来了下游“奖励”空间的探索可能。
同时,未来这种自采样+自奖励下的完全自监督RL也许能够更好的为后续依赖于外部奖励反馈提供遵循于现有模型的缓冲,以通过相对平滑的过渡来逐步激活放大对基础模型新推理模式的探索,甚至也许会泛化出更多样的推理Pattern。而这亦对数据采样及自奖励函数的设计、优化策略等提出挑战,正如原论文中所提及的模型对先验知识的依赖所对应的数据分布的混杂以及训练过程中的超参数精细设置等挑战。
另外,对于RL应用于当前LLM或未来Multimodality过程中,诸多实验室或研究机构就采用RL方法对深度推理空间内Pattern的探索潜力与实际效果亦提出了诸多质疑、挑战、反驳及可行的建议:
如,之前撰写过的一篇文章《边读论文边记录系列① | 深度推理模型对慢思考认知与模型持续优化的重新审视与思考》中分析的一篇「Concise Reasoning via Reinforcement Learning」论文,这篇论文从强化学习(RL)的动态视角重新审视了大型语言模型(LLMs)在复杂推理任务中生成冗长回复的根本原因:

传统观点认为,复杂推理通过逐步细化逻辑提升准确性(如系统2慢思考的显式化推理)。但论文指出,RL训练中生成的冗长回复更多是“损失优化的副作用”,而非推理质量的必然要求。
比如当模型频繁生成错误答案时,PPO的损失函数会通过延长回复来探索更多潜在路径(类似“试错”策略),导致冗余;而正确回复虽被强化,但其简洁性可能被淹没在整体训练动态中,这样模型将面对相当大的对泛化建立正确分布的干扰,尤其是当数据集包含大量困难问题时,模型更倾向于保守延长回复。这种矛盾也进一步揭示了传统RL优化目标(最大化奖励)与人类期望的推理效率(最小化冗余步骤)之间的错位。
这种矛盾也进一步揭示了传统RL优化目标(最大化奖励)与人类期望的推理效率(最小化冗余步骤)之间的错位。
而作者的办法是提出的两阶段训练策略,个人理解感觉更是尝试建立了对推理能力的分阶段显式→隐性迭代演进(或者说是一种认知的进化,就像我们人类在认识成长过程中一样)。
阶段1·能力扩展:通过挑战性问题激发模型的探索能力,允许回复变长以覆盖更多潜在解空间。这一阶段类似“发散思维”,强调通过显式token的牵引式生成以带动模型隐空间参数化泛化探索持续增强的同时,也是对模型在复杂问题上认知能力的重构建立。
阶段2·效率优化:针对部分简单且可演进为某种直觉快速映射推断的进化,通过奖励机制抑制冗余步骤。这一阶段类似“对泛化的收敛”,同时在快速直觉映射时强调领域内精确性。
未来,我想在对于不同复杂问题所对应的可泛化探索空间的求解,均可以采用这种「分阶段显式→隐性迭代演进」的方式,另外第①阶段中,这种显式next token predict的AR也好还是diffusion又或者其它生成式或判别式范式,将来随着技术的持续探索及验证,也许会进一步在理论上形成AI模型隐空间对真实世界ground-truth持续采样、映射、学习的通用范式。
论文的作者更进一步的进行了PPO与GRPO算法应用不同训练任务目标及所呈现出的数据分布采样对于模型反向传播中所采用的梯度策略对模型内隐参数空间重塑与扰动过程下的平衡。如对比了PPO和GRPO在简洁性优化中的表现,揭示了RL算法设计的关键权衡:
PPO的稳健性:通过优势函数(GAE)的折扣因子(λ<1),PPO能稳定平衡长短期回报,避免价值估计的爆炸/消失。其核心优势在于“对错误答案的渐进抑制”,而非直接惩罚长度。

GRPO的崩溃模式:GRPO的优势归一化(基于组内样本)在数据分布极端时失效(如全对/全错),导致训练信号消失。其设计更适合“动态多样化的数据流”,但对小数据集或静态问题的适应性较差。

最后,论文的结论对系统2慢思考(显式、逐步推理)的实践提出了新视角:
必要步骤不可压缩:某些复杂问题(如数学证明)需严格逻辑链,强制简洁可能破坏推理完整性。此时,两阶段训练需结合领域知识筛选关键步骤。
冗余步骤可修剪:许多冗余(如重复计算、无关代码生成)并非必要,通过RL可识别并抑制。论文的实验表明,简洁性与准确性可协同优化,而非零和博弈。
这一发现挑战了“长即准确”的直觉,暗示推理质量的提升应依赖更加循序渐进的精细化“路径质量”的探索而非长度。
而我想这也进一步印证了RL多种采样策略与精细化自奖励反馈的深度可优化空间,即于探索空间中所蕴含的复杂而玄妙的多种认知推理Pattern,也许需要发掘更多样化的采样策略与奖励机制,以激活基础模型更多潜在的可泛化空间。
当然,近期也有不少其它实验室或研究机构就采用RL方法对深度推理空间内Pattern的探索潜力与实际效果进行了实验对比验证,如之前写过的一篇文章《LLM×RL受到来自虚假奖励的挑战?一篇Rethink-RLVR的研究报告对AI学术圈的小扰动 | 后附小彩蛋》中所提及的反直觉发现:对Qwen-Math等领域专属模型,即使使用随机奖励或错误标签等虚假信号做RL微调,也能获得与真实奖励相当的数学能力提升,而这种“反直觉”,也许是进一步帮助我们更好的理解并揭示了RL微调在某些奖励维度下对更高级强化扰动及泛化遵循能力的本质——它更像是“高级知识提取器”而非“知识注入器”。这也进一步将基础模型的某种隐性泛化能力通过显性提示或遵循约束以激活其潜在复杂推理Pattern并将这种Pattern于模型内隐状态空间再到全局联合概率分布的输出上实现强化反馈。
这里不再对这篇文章中的论文进行详细解读,仅Highlights出我的一些核心观点分享大家,大家如想回顾原文章,可参考《LLM×RL受到来自虚假奖励的挑战?一篇Rethink-RLVR的研究报告对AI学术圈的小扰动 | 后附小彩蛋》:
1. 模型内隐知识的扰动与牵引:从模型内隐知识结构及分布的角度来看,预训练模型在训练过程中已经学习并泛化了大量的知识和模式。这些知识和模式可以被视为模型的内隐参数化知识,它们在模型的决策过程中起着重要作用。当使用不同的强化学习方法和奖励信号对模型进行训练时,实际上是在对这些内隐知识进行扰动和牵引。例如,在RLVR中,即使是虚假的奖励信号,也可能通过强化某些特定的推理模式或策略,使得模型在特定任务上的表现得到提升。这种提升并不是因为模型学到了新的知识,而是因为模型在训练过程中被引导去更好地利用其已有的内隐知识。
2. 整体策略遵循的必然现象:从整体策略遵循的角度来看,模型在强化学习训练过程中所表现出的性能提升,可以被视为模型在遵循某种整体策略上的必然现象。这种整体策略可能与模型的预训练目标、结构以及训练过程中的奖励信号等因素有关。以Qwen2.5-Math模型为例,其在RLVR训练中表现出的对代码推理的偏好,可以被视为模型在遵循一种利用代码来辅助数学推理的整体策略。这种策略在模型的预训练过程中可能已经得到了一定程度的学习和泛化,而在RLVR训练中,通过奖励信号的引导,模型进一步强化了这种策略,从而在数学推理任务上取得了更好的性能。
3. 奖励信号的形式与强度的影响:奖励信号的形式和强度对模型的性能提升有着重要的影响。不同的奖励信号可能会引导模型朝着不同的方向进行优化,从而影响模型对内隐知识的利用和整体策略的遵循。例如,真实答案奖励信号可能会引导模型学习更准确的推理能力,而虚假奖励信号则可能会引导模型强化某些特定的推理模式或策略。此外,奖励信号的强度也会影响模型的训练过程。较强的奖励信号可能会使模型更快地朝着某个方向进行优化,但也可能会导致模型过度拟合;而较弱的奖励信号则可能会使模型的优化过程更加缓慢,但也可能会使模型更加稳健。
4. 模型泛化能力的扰动与牵引:强化学习训练过程中的奖励信号不仅会对模型的内隐知识进行扰动和牵引,还会影响模型的泛化能力。例如,使用虚假奖励信号进行训练可能会使模型在特定任务上的性能得到提升,但这种提升可能并不具有很好的泛化性。这是因为虚假奖励信号可能无法准确地反映模型在真实世界中的表现,从而导致模型在面对新的、未见过的任务时,无法有效地利用其已有的知识和策略。相反,使用真实答案奖励信号进行训练可能会使模型的泛化能力更强,因为这种奖励信号能够更准确地反映模型在真实世界中的表现,从而促使模型学习到更具泛化性的知识和策略。
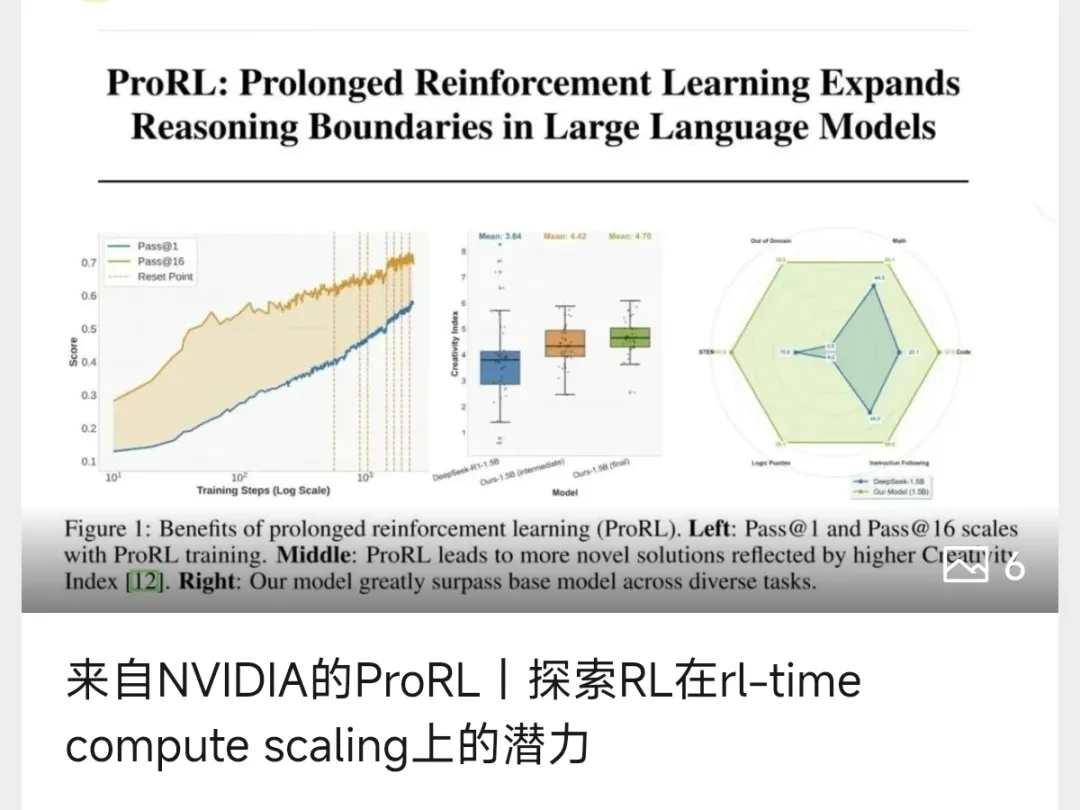
不过,近期一篇来自NVIDIA的题为《ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models》论文尝试以rl-time compute scaling的视角挖掘并探索RL在llm post-training上的潜力,反驳了众多研究机构对当下RL的质疑。

ProRL的核心假设建立在为模型提供充裕且多样化的强化学习训练基础之上,认为如此一来,模型便可以突破模式坍缩的束缚,实现对解题空间的充分探索,并成功发现以及固化那些传统基座模型所无法企及的全新推理模式,这从根本上重新审视了强化学习在模型推理能力提升过程中的作用,认为此前强化学习未能充分发挥效用,或许并非其自身存在根本性缺陷,而是由于我们给予其进行有效训练的时间以及探索空间相对有限。
从最终的实验结果来看,确实ProRL能够带来对之前对RL局限性的假设反驳,其采用多样化的训练任务并以Group Relative Policy Optimization(GRPO)算法作为核心 RL 算法,对其进行了多项改进和优化,并展现出了独特且耐人寻味的特性:
经观察发现,ProRL所带来的性能提升程度,与基座模型在相应任务上的初始能力呈现负相关关系。具体而言,针对那些基座模型pass@128指标较低的任务(这类任务往往意味着基座模型本身不擅长处理,具有较高的探索需求),在运用 ProRL 训练之后,pass@128指标能够实现极为显著的提升。
这一现象恰似在黑暗环境中进行探索,强化学习所提供的反馈信号如同手电筒发出的光芒。当处于完全黑暗的区域时,微弱的光亮便能发挥巨大作用,为模型指引正确的方向;相对地,在已有灯光照明的地方,手电筒的增益效果则相对有限。即在基础模型初始能力较弱的任务上,RL 的提升效果更为显著,且随着训练时长的增加,模型的推理边界能得到更有效的扩展。
论文中更多内容不在这里赘述,之前也写了一篇针对此篇论文的分析解读,大家感兴趣也可以查阅回顾或可以阅读原论文:《来自NVIDIA的ProRL|探索RL在rl-time compute scaling上的潜力》
在本章节最后结尾处,结合上述几篇代表性论文的间接佐证以及自己的观点假设,给出大伙我的两点延伸思考:
思考〔1〕
强大的经pre-training的基础模型理论上获得并掌握了较好的快思考及潜在的慢思考(这里指多种Pattern下的推理分布)推理模式及泛化遵循能力,但对应复杂推理模式即CoT或Long Reasoning在没有额外指令与提示注入下,模型因预训练阶段长推理数据的稀缺天然短板也许无法获得有效学习或泛化(复杂推理pattern某种程度对于基模来说是一种新的流形概率分布)。
因此不论是以刻意增加模型响应长度为目标来达到CoT或其他的复杂推理的数据构造下sft,还是通过RL不断强化模型自主出现aha moment自演变形成长推理链,均实现了模型对长链推理模式的学习泛化。
而从模型前向生成的更长或复杂推理响应以及训练过程中的反向梯度(sft监督信号&rw奖励信号)来看,因为通常模型为全量参数更新,于模型内,即实现对模型隐参数空间中的神经元进行“重整”,这种重整和变化意味着模型会根据模型内隐参数空间状态实现更长或不同pattern分布下的next token predict(对于Autoregressive来说)或Diffusion,因此从模型输出侧来看,直觉上更长推理链的step by step token predict是与模型输入侧及模型中间隐参数空间是态射的,即这种快与慢思考的predict差别取决于输入和模型隐参数control,因此我们看到模型的推理能力的提升来源于更多信息量的CoT或struct指令遵循(提示增强)与模型内隐状态在长或复杂推理模式上的强化(知识参数化)。
在这里,因为模型要去完成这种CoT、Long&Deep Reasoning的模式匹配,猜想模型内隐参数空间需要进一步满足在经过sft或rl之后的更强数据压缩能力,即基模需要具备更大的可扩展参数潜力以满足模型持续朝复杂推理模式迭代演进过程中实现对推理数据结构精细化学习、泛化即压缩(“压缩”来自于Ilya早期的那次学术报告)。
思考〔2〕
关于上述模型从系统1的快思考在向系统2的慢思考长或深度推理模式通过sft或rl进行演进过程中,其基础模型与最终后训练RL模型内隐参数空间所呈现的差异似乎存在着微妙的联系。很多AI实验室在采用不同的强化学习方法对推理模型的训练后能力几乎都表现出了对基础模型的强大性能依赖,而这背后的原因或机制到底是怎样的?
从rl本身的过程和角度表面上来看也许强大的基础模型能带来对状态空间持续更优的探索与利用,而这里“探索”与“利用”背后的复杂程度我想是不亚于大模型黑盒内机制的。
从模型外的真实世界推理模式与状态空间来看:一个强大的快思考基础模型实现了某种程度上短链推理的快速响应和极致泛化能力,实现了从单一“问题Q”状态→“答案A”状态的快速模式匹配,而经过RL后训练下的具备复杂长推理Pattern下的模型实现的则是更多且复杂步骤下的“Q”→“a(q')”→a'(q'')...→A的模式匹配,那么从现实世界中来看第一种简单的“短链”Pattern是否可以被认为是第二种“长链”复杂推理Pattern某种程度上打下了分段式推理泛化基础即直觉上更像是对推理碎片化能力拼接的泛化。
从模型内角度来看,虽然模型对两种Pattern进行了整体重整,其流形分布整体上会有较大的结构性差异,但我猜想也许因DNN中FFN本身的多层级结构、Transformer中的Self-Attention机制以及在模型反向传播下梯度策略作用于模型权重上的过程本身等因素(只能猜想了,毕竟模型黑盒问题过于复杂了…),使得基础模型内参数化权重是可以为RL后的推理模型带来复杂CoT或long reasoning推理能力于模型神经网络结构所带来的隐参数知识压缩带来潜在增益的。
那回过头来我们再看一下RL中的“探索”与“利用”,也许模型会通过放大采样(Test-Time RL和Socratic Learning所采用的方法)以渐进式改变数据分布的方式,来完成对模型在rl“探索”与“利用”过程中的平衡演进,在这一演进过程中,依赖于基础模型在推理模式的基础遵循,而这种“基础遵循”一方面来自于模型对通用泛化能力的全面覆盖,同时也会存在着对复杂长链或深度推理能力的一定可泛化延展基础,即 使得模型在rl中可以针对复杂类问题进行广泛的并行采样过滤或递归式的渐进序列过滤来实现模型正反向传播下的“有效探索”并“充分利用”,同时这种基础遵循下的探索与利用的可行,需要提前确证在真实世界中确实存在着快与慢两种思维模式所对应的两种推理认知Pattern的自然分布,当然试错与反思也可以将其归纳为整个认知推理分布中的真实信息处理与加工客观现象。
于是,于模型内隐参数/状态空间作用下,在两种推理模式间的分布转移与渐进演变过程中,如上文中所提及的这种不管表象下的“分段式推理能力的泛化”,还是“推理碎片化能力拼接的泛化”,我想都可以归纳为具有完备泛化能力的基础模型在基础泛化遵循下,延展并进一步打开了长链复杂推理泛化世界,同时也进一步弥补了基础模型在最初pre-training过程中的长链推理ground-truth的稀缺或不足。
此章节更多引用并借鉴了近期刚刚所撰写的一篇文章:《Thinking with Multimodal|开启视觉深度推理与多模态认知的新范式》中的内容,感兴趣的大伙可阅读参考。
记得两年前与一位临床病理科主任的交谈碰撞中在谈到传统AI辅助阅片的场景中,尤其对于一张复杂的具有高精度像素级病理影像需要进行反复阅读查验即visual thinking后做出判断,相信在这一过程中,医生的大脑在一次次针对视觉信息的特征再加工变换与某种符号化推理相结合的反复互增强之后,才最终形成的相对个体高特异度的个性化诊断结果。

在与这位病理科主任的探讨交流中,也深刻感受到了在一张病理学影像中不同局部、尺度下的视觉感受野存在着在时空特性上的更多特征组合与变换的潜力与可能,甚至一些更多潜在的特征还远未被我们人类所挖掘或识别,这也进一步激发了这位经验丰富且极具探索精神的临床工作者对将AI工具应用于临床的信心与期待,也许未来随着Visual RL技术在机制范式与奖励稀疏性甚至是在CV基础模型在通用泛化与「视觉推理」泛化能力的进一步提升后,将会像LLMs那样更好的应用RL及相关RFT、distill等技术。ps,也许diffusion又会大放异彩。
我们知道,随着用于deepseek R1等RL训练框架的提出,研究者们开始尝试将文本领域的强化学习范式迁移到视觉模态,试图通过RL训练视觉语言模型(VLM)的思维链(CoT)机制来复现类似文本领域的"顿悟时刻"(Aha moment)。但值得注意的是,当前评估仍聚焦于文本推理的典型特征:如是否出现"wait"、"alternatively"等自我反思词汇,或响应长度增加是否伴随基准测试准确率提升。这种评估范式隐含着一个值得商榷的前提假设:视觉推理应与文本推理共享相同的认知模式,那么,有没有一种可能,视觉推理的思考模式就应该是不同于文本推理的呢?
一些认知神经科学的研究表明,人类处理视觉问题时展现出截然不同的认知特性:
1)动态注意机制 - 视觉理解并非单次编码后的静态推理,而是注视点移动与认知加工持续交互的过程;
2)视觉思维(Visual thinking)的存在 - 部分个体天生依赖视觉表征进行抽象思考,其视觉神经表征与语言思维也许存在本质差异,如对欧式几何空间下的特征深度再加工与再变换。相较之下,现有VLM的视觉处理存在显著局限:视觉编码器仅在前端执行一次性特征提取,后续推理完全在文本模态中进行,这种设计本质上将视觉信息压缩为静态上下文,导致视觉认知的关键特征(如时空动态性、并行处理等)在编码过程中产生模态特异性损失(modality-specific information loss);
一个很明显的感性证据是:人类在面对一个视觉类问题时,并不是看一遍图之后就在脑子里一通思考,而是会边看边想;甚至也许有部分人是天生具备visual thinking的能力,他们大部分的思考都是用以图像视觉的方式来展开的,相比之下,VLM的图片只有在一开始输入给模型时由vision encoder一次性变成image embedding,之后图片就变成了纯静态的context,这种纯文本的思维方式在视觉domain是“有损”的。
因此,在大语言模型在深度推理的飞速发展与快速演进的伴随下,相信视觉推理领域亦正经历一场深刻的变革。
传统的大型多模态模型(LMMs)在处理视觉信息时,往往局限于将图像作为静态输入,通过文本链式推理(CoT)进行认知与决策。然而,人类的认知过程远不止于此——如上文所述,人类通常能够主动构建视觉表征、进行多步骤的视觉想象与反思,并在这一过程中动态调整对世界的理解。近期的几篇代表性论文:「“Visual Planning”|“Pixel Reasoner”| “Thinking with Generated Images”|“DeepEyes”」,分别从生成式纯视觉到跨模态动态推理与规划的角度,提出了突破性的新范式,为视觉深度推理与多模态认知开辟了新的道路。
论文“Visual Planning: Let's Think Only with Images”率先挑战了语言作为推理媒介的主导地位。论文提出,在涉及空间与几何信息的任务中,纯视觉推理可能比语言推理更具优势。通过强化学习框架 Visual Planning via Reinforcement Learning(VPRL),模型能够基于纯视觉表示进行规划,生成一系列图像以编码视觉领域的逐步推理过程,直接在视觉特征空间中完成复杂推理任务,如迷宫导航与空间布局设计。
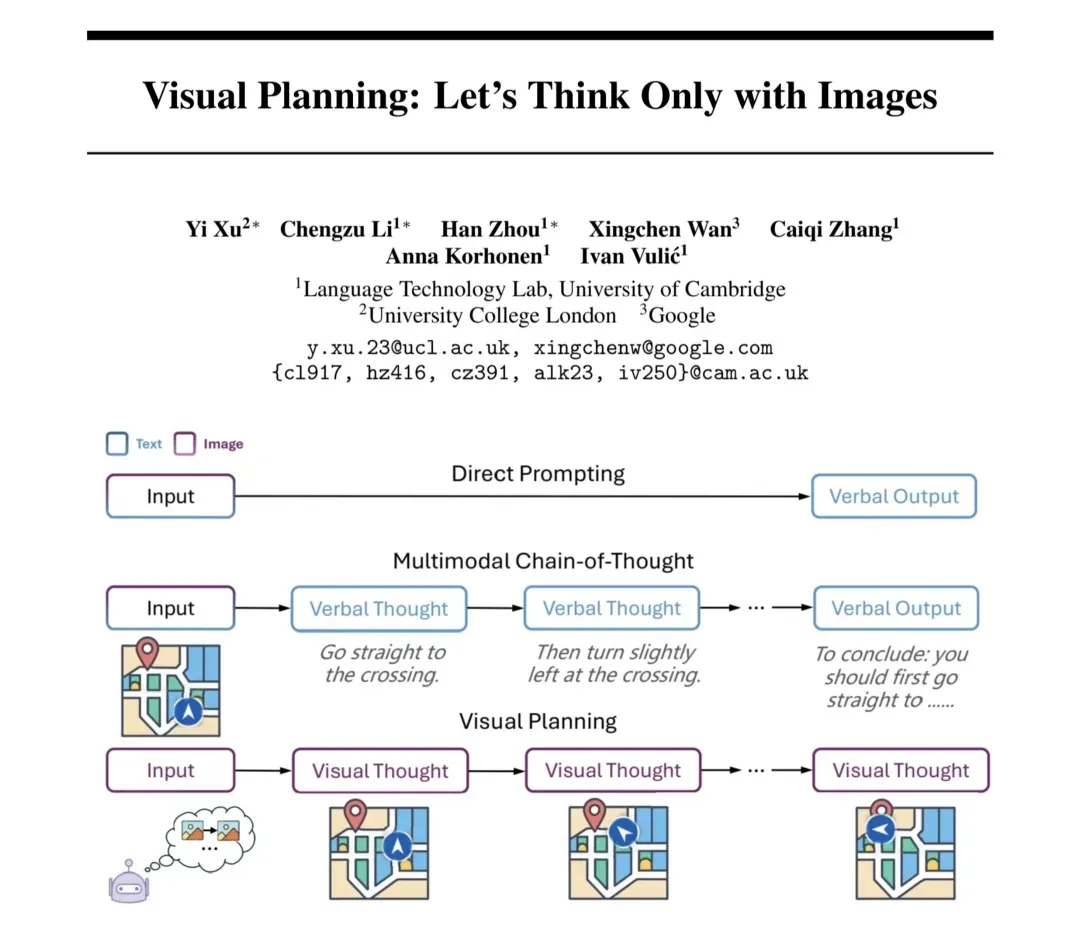
无独有偶,近期一篇来自滑铁卢大学、港科大、中科大的研究团队的另一篇论文:Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning中提到的「像素空间推理·Pixel Space Reasoning」,亦在突破“文本中介”,赋予模型直接在像素级视觉信息上进行操作并且推理的能力:

如建立视觉主动操作,模型可自主触发视觉变焦(放大关键区域)、时空标记(定位视频动态线索)等原生操作,在像素矩阵上直接完成「操作 - 分析 - 推断」的闭环推理,避免了文本转译导致的信息衰减。
在视觉操作成为推理演进的核心驱动力时,例如在论文图例中,回答「咖啡杯 logo 品牌」时,模型依据空间先验知识定位桌面区域,再通过视觉放大功能逐行细致扫描杯身,最终在像素级精度上精准提取 logo 特征。这种基于视觉线索引导的推理机制,使模型精准捕捉到传统方法难以处理的空间关系与动态细节信息。
在之前的大多数模型跨模态任务中,处理视觉部分的模块往往更多是基于通用视觉生成与判别或针对下游任务于图像内进行单次特征编码,后续推理则更多依赖于文本模态,这无疑丢失了视觉认知中的动态性。这种对于文本的过度依赖,致使在面对高清图像中的微小物体、视频里的动态细节等场景时,常因缺乏直接视觉操作能力,出现关键视觉信息缺失,导致模型无法精准感知并推理。
正如上述段落中所述曾经与那位临床病理科主任沟通中,病理图像的诊断需要反复阅读和视觉思考。人类在面对视觉问题时,视觉理解是动态的,伴随着注视点的移动和认知加工的持续交互。而 “Thinking with Generated Images” 、“Visual Planning”、“Pixel Reasoner”三篇论文中生成的中间视觉步骤 - 尽管它们中间的步骤推理机制不同,但实际上可以将跨模态信息建模并统一参照在〔Latent Space Reasoning〕空间中来看待(下有进一步论述),实际上亦为视觉推理注入了领域知识下的动态性,使模型能够像人类一样结合任务与领域知识逐步构建和调整对视觉信息的理解。
“Thinking with Generated Images”这篇论文首次提出了一种全新的范式:让模型能够跨越文本与视觉模态进行原生推理,通过自动生成中间视觉思考步骤,模拟人类在解决问题时的视觉想象与反思过程。这与传统的仅基于后文本转换对齐后的 CoT 形成鲜明对比——后者将视觉信息转化为文本描述后,仅在文本空间内进行推理,导致模态特异性信息损失或甚至带来基于后文本对齐视觉模态下针对模型latent space reasoning的long reasoning带来RL post training在exploration&exploitation及policy梯度上升的挑战。而新范式则通过原生多模态思维过程,使模型能够动态生成、检验与精化视觉假设,从而在复杂多目标场景下取得了显著性能提升。

同时,上述论文中强调的这种跨视觉与文本特征的关键组合对齐和潜在特征映射的重要性,亦让我联想到强化学习(RL)在视觉与多模态推理中的进一步应用潜力与挑战。在跨模态复杂推理迁移方面,如在之前的一篇文章《统一视角看待RL从LLM到MLLM再到Agentic AI空间探索中的演进与挑战》 中所提及的DeepEyes: Incentivizing “Thinking with Images” via Reinforcement Learning这篇论文中 “边看边思考” 模式,实现了将符号化推理能力逐步嵌入视觉领域。这与 “Thinking with Generated Images” 的理念亦不谋而合,都是试图让模型更深入地理解视觉信息。

这种「边看边思考·Thinking With Images」的模式,亦实现了将符号化推理能力step by step嵌入并增强到视觉领域,从而可实现以构建Agent的方式参照不同下游任务类型的CV分类、分型且以任务为导向的深度精细化特征挖掘「这里并没有沿着语言模型从强大基础模型LLM(V3)强化到推理语言模型RLM(R1)的pre-training VLM→RL RVLM的技术路线,毕竟pre-training一个类似V3的VLM在真实世界视觉领域在数据和技术上感觉还未成熟且挑战不小」。如定义agent框架,赋予模型一个图像工具,让模型能够通过输出grounding坐标的形式来调用tool,从而按照自己的意志来取观察图片中感兴趣的部分,也是computer use的一种。

而对于来自Google DeepMind AlphaGeometry系列模型来说,也许通过对数据与技术方法的进一步探索,未来可以基于此更好的构建领域下的pureVLM或跨代数与几何形式化互增强的推理证明Patterns,甚至将Reasoning从欧式空间延展至非欧空间,虽然这看似还有不少的工作要去做,不过好消息是我们现在的很多RLM已经明显具备了很强的数学形式化证明泛化与迁移能力。

相信未来,随着RL在奖励稀疏性、通用泛化能力等方面的进一步提升,有望像LLMs应用RL那样,为视觉推理带来更强大的推理和规划能力,实现更精细的特征挖掘。
从技术路线发展来看,上述几篇颇具代表性的论文为视觉推理技术带来了看似两个子方向突破:一是通过构建创新的多模态RL框架实现跨形式空间与模态空间的动态深度推理;二是探索强化学习方法激发纯视觉像素空间内推理与规划的Aha时刻;我想这些突破背后,亦能折射出多模态认知融合的深层逻辑。
因此,在本章节中,我将结合上述几篇代表性论文,分享一下我对“从语言到视觉再到多模态深度推理(Multimodality Reasoning)”的思考与观点:
思考〔1〕原生多模态的思考
“Thinking with Generated Images”和“DeepEyes”中提出的原生长多模态思维过程,可以说是某种真正意义上的多模态融合机制。该机制通过统一自回归生成式 LMMs,在单次推理过程中交织生成文本与视觉 token。这种原生多模态生成能力,使模型能够根据任务需求,动态切换推理模态,将语言形式化符号空间的抽象性与欧几里得二维视觉像素空间特征有机结合和对齐。
例如,在复杂图像生成任务中,模型会先将输入文本分解为多个子目标,为每个子目标生成初步图像,再通过迭代反思与修正,将这些子图像整合为最终结果。这种动态推理过程,不仅提升了生成图像的准确性与质量,还揭示了多模态推理的本质:不同模态之间的认知优势互补。当任务涉及精准空间布局时,视觉推理主导;而当需要抽象概念表达时,文本推理接管。这种模态间的动态协作,正是人类认知的特征之一。
这一机制还为多模态认知研究提供了新思路。在传统的多模态模型中,不同模态往往是并行处理后简单融合,而原生多模态思维过程则强调模态间基于任务目标的动态交互与迭代。这提示我们,未来的多模态模型应更加注重模态间的动态关系,而非简单的信息拼接。
思考〔2〕强化学习驱动下纯视觉复杂推理建模范式|在像素空间世界中寻找最优路径
“Visual Planning”和“Pixel Reasoner”通过VPRL和Pixel Space Reasoning框架,进一步的展示了强化学习仅在纯视觉规划中的强大潜力。在迷宫导航等像素空间推理任务中,模型仅基于视觉输入,通过试错学习最优路径规划。这一过程避免了语言描述的模糊性与局限性,直接在视觉特征空间中进行推理。
而强化学习·RL在这一场景中的关键作用在于,它为模型提供了一种基于环境反馈的学习机制。通过奖励函数设计,模型能够区分有效动作与无效动作,并逐步学会在复杂环境中做出合理决策。例如,在迷宫任务中,模型通过像素级状态变化识别有效移动方向,并根据距离目标的远近调整策略;在回答「咖啡杯 logo 品牌」时,模型依据空间先验知识定位桌面区域,再通过视觉放大功能逐行细致扫描杯身,最终在像素级精度上精准提取 logo 特征...
这一技术突破的意义在于,它为涉及空间推理的任务提供了一种全新的解决方案。在机器人导航、工业自动化等领域,纯视觉规划能够显著提升系统的适应性与鲁棒性。同时,它也引发了对视觉推理本质的深入思考:视觉信息是否真的需要语言中介才能完成复杂推理?或许,视觉推理拥有独立于语言的认知逻辑。
思考〔3〕模型底层架构的演变|从自回归到扩散模型
昨天在智源大会的远程直播中正好间断性的听了一下多模态分论坛中各AI Lab和机构的最新研究进展,发现今年大家都讲自己的研究方向着重放在了对底层模型架构的选择与研究评估上。
当然,技术范式的转变,离不开模型底层架构的创新。自回归·AR模型与扩散·Diffusion模型,作为当前两大主流生成模型架构,在视觉推理领域各有侧重,其发展路径与技术特点深刻影响了视觉推理的实现方式。
记得差不多在一年前,围绕AR与Diffusion的研究与探索已经开始有所苗头,记得当时自己也阅读了多篇文献并尝试持续探索...《世界模型融合与统一深度思考:自回归与扩散生成》这篇去年的笔记感兴趣的大伙也可以回顾并在这之前有多篇文章围绕AR与Diffusion的架构方法进行了探索与分析,记得当时在学术与产业界围绕AR与Diffusion还是有着不少的热度的。

但后来被OpenAI o1与DeepSeek R1这股long reasoning的热浪带动下将更多精力投入到RL中来,毕竟这是自己自创立开号写博客之初就重点关注的方向,本号的前几篇十万字文章中也针对RL×LLM做过一些探索与展望,感兴趣的大伙也可以再回顾回顾~哈哈:《回顾·总结·展望「融合RL与LLM思想,探寻世界模型以迈向AGI」》

下面在对自回归·AR与扩散·Diffusion做一下梳理:
1. 自回归·AR模型:逐步构建认知的“乐高积木”
自回归模型通过逐 token 生成的方式,模拟了人类逐步构建认知的过程。在“Thinking with Generated Images”中,自回归 LMMs 仍能够在推理过程中动态生成视觉与文本 token,这使其具备了处理长序列多模态思维链的能力。然而,自回归模型也面临挑战——其生成过程的顺序性可能导致早期错误累积,影响后续推理结果。
2. 扩散·Diffusion模型:从噪声中雕琢认知的“雕塑家”
扩散模型则通过逐步去噪的过程生成数据,这一特性使其在图像生成任务中表现出色。然而,将其应用于视觉推理时,需要解决如何在去噪过程中保留中间推理信息的问题。尽管如此,扩散模型的并行生成特性为其在多模态推理中的应用提供了新可能,尤其是在需要同时处理多个模态信息的场景中。
3. AR与Diffusion的回归与统一:Latent Space Reasoning
是啊,我又再一次提到了“Latent Space Reasoning”,就像上周末参加的一次线下社群技术交流会中后记录的简单笔记中观点所述有关Latent Space Reasoning的线下探讨:有关Latent Space Reasoning的线下探讨,对于AR还是Diffusion来说,还有一个更为关键的前置:即对于模型内Latent Space Reasoning的完备建模,而AR和Diffusion则是对其Latent Space的下游联合概率计算(AR)也好还是以时间步数为核心的的扩散或流匹配升降噪表征(Diffusion&Flow)也罢的流形分布计算所呈现的不同路径或方式。而transformer或其他诸如Titan或TTT等架构,亦对部分核心Latent Space的未来持续探索起着核心的作用。
不过,当前对于RL下的单模态(文本)或跨模态仍多采用统一的自回归AR作为主流模型主干网络,这一方面避免了多组件代理方法的复杂性,降低了系统集成和训练的难度,同时也便于与其他技术和方法进行结合,如各种相对成熟&主流的RL奖励建模与策略梯度优化算法等,也为统一框架下打通了有利于推动多模态模型向更强大、更通用的方向发展的路线。当然AR是否是最优解,仅凭当下判断还为时尚早,相信随着未来diffusion工作在多模态的进一步进展,其两种生成式建模方法背后的原理机制与RL的进一步结合的真相将会浮出水面,好在现在很多的研究探索正在发生与进展中。
思考〔4〕进一步延展到强化学习·RL对视觉及跨模态的Post Training的思考
我想,更进一步的,强化学习·RL在视觉推理中的应用,正从简单的策略优化工具,向深度跨模态空间探索与利用再到认知过程的转变。这种转变带来了新的机遇与挑战:
1. 强化学习·RL的机遇:解锁视觉复杂推理的“阿哈时刻”
强化学习的核心优势在于,它能够通过试错学习捕捉任务中的深层规律。在视觉推理领域,这使得模型能够发现人类专家也难以明确表达的隐性知识。例如,在化学分子结构预测中,强化学习可以帮助模型在欧几里得像素空间中探索新的复杂分子组合方式;在几何证明中(如之前撰写AlphaGeometry的这篇论文:《谷歌DeepMind发布AG2:开启AI4Math下一代范式?》),可以进一步在跨形式化符号体系中实现对空间的探索建模;在建筑设计中,它能够生成符合功能需求的创新布局。这些“阿哈时刻”的出现,预示着强化学习在推动模型认知能力跃迁方面的巨大潜力。
2. 强化学习的挑战:跨越模态的“巴别塔”
然而,强化学习在多模态场景下的应用仍面临诸多挑战。当模型需要在多个模态之间转换时,如何设计统一的奖励建模成为关键难题。例如,在涉及文本与图像的多模态任务中,语言的抽象性与图像的具体性可能导致奖励信号的不一致。此外,强化学习的计算成本较高,如何在大规模多模态数据上高效应用强化学习,也是未来需要解决的问题。
思考〔5〕迈向通用人工智能|多模态认知的统一框架
从更宏观的视角看,这些技术突破正推动我们向通用人工智能(AGI)迈进。多模态认知的统一框架,或许是 构建世界模型通往AGI的核心基石。
1. 多模态认知的统一:在差异中寻找共性
上述“「“Visual Planning”|“Pixel Reasoner”| “Thinking with Generated Images”|“DeepEyes”」几篇论文共同揭示了一个重要趋势:不同模态的认知过程虽有差异,但存在可统一的底层逻辑。无论是通过生成中间视觉步骤,还是通过强化学习优化视觉规划或者是基于视觉的Tools Use建模(可参考之前一篇《统一视角看待RL从LLM到MLLM再到Agentic AI空间探索中的演进与挑战》”文章中提到过的对DeepEyes: Incentivizing “Thinking with Images”via Reinforcement Learning论文中所述),模型都在尝试将不同模态的信息在不同的跨形式化符号与数据流形分布中映射到同一认知空间即→Latent Space Reasoning。这种统一性,为构建能够处理多种认知任务的通用AI提供了可能。
2. 从专用智能到通用智能:跨越任务边界的能力迁移
当前的 AI 模型仍大多局限于特定任务,而通用智能要求模型具备跨任务的知识迁移能力。“Thinking with Generated Images”中模型在图像生成任务中学会的视觉子目标分解能力,或许能够迁移到其他需要空间规划的任务中;“Visual Planning”中模型掌握的纯视觉规划技巧,也可能为涉及动态环境感知的任务提供启发。这种能力迁移,是迈向通用智能的关键一步。然而,talk is cheap...其中对数据以及建模方法的挑战我想将会异常的大。
本章节观点总结
“Multimodality Reasoning”或“Thinking with Multimodal”相关研究,不仅是技术上的创新,更是对人工智能认知本质的深刻探索。从“Thinking with Generated Images”跨越模态的动态推理,到“Visual Planning”纯视觉规划的强化学习实践,我们看到了人工智能在模仿人类对跨模态认知道路上的又一坚定步伐。然而,技术的进步也提醒我们,真正的认知智能,不仅需要强大的技术支撑,更需要对人类认知规律的深入理解。未来的研究,我想亦应更加注重技术与认知科学的深度融合,在技术浪潮中把握认知的本质,推动人工智能从专用智能迈向通用智能,为解决人类面临的复杂问题提供更强大的工具与思维框架。
2022年,以OpenAI ChatGPT为代表的大语言模型的涌现能力如同一次认知奇点的爆发,其突破性不仅在于对人类语言的生成,更在于语言模型能够以tokenize符号化表征概率空间的联合分布并形式化概念世界运行逻辑的潜能。当OpenAI的o1/o3、DeepSeek R1等模型在复杂长程推理、结构化思维层面持续突破系统①·快思考的边界时,一个更具颠覆性的命题正在浮现:基于大模型的智能体(AI Agent)是否有希望演变为人类在认知探索过程中的另一种数字孪生?这场以"token predict"为起点的技术革命,正在将LLM的认知边界从符号化序列生成,拓展至对物理世界、认知空间再到社会化结构的建模与协作。
在传统AI工程范式中,任务规划与执行往往被解构为离散的功能性事务处理或算子模块,在既定的场景下更多依赖于人工设计的规则与流程。而LLM或RLM的突破,通过对海量数据语料与概念知识进行多阶段训练并将其压缩进模型隐参数空间中所形成的认知中枢,使得机器首次具备对一定的通识知识体系的泛化与理解。这种能力的质变,使得"模型即智能体"(Model as Agent)的范式成为可能——模型不仅能理解指令,还能自主拆解目标、规划路径、验证结果并动态修正,我们面对的已不仅是工具效率的提升,而是以另一种智能数字孪生形态对各类任务决策与行动的重构。
未来,llm驱动下的超级应用或智能体也许并没有捷径或通过某1-2个创新就能产生突破或颠覆,因Agentic内涵中涉及了诸多复杂资源组织与形式化逻辑,而本质上其多种资源与形式逻辑亦是对真实世界各类事务的某种数字孪生、模拟或映射,同时它也涵盖了包罗万象的传统信息与数字化的方方面面,如传统的事务处理层面、长链推理规划层面,数据记忆与容错方面。
回到本篇文章的开头所述:强化学习·RL范式尝试为LLMs应用于广泛的Agentic AI甚至构建AGI打开了一扇“深度推理”的大门,而RL是否是唯一且work的一扇门,先按下不表(不作为今天跟大家唠的重点),至少目前看来,随着o1/o3/r1/qwq..等一众语言推理模型的快速发展,正推动着LLMs和Agentic AI在不同领域的价值与作用,包括对各种形式化框架下的复杂推理Patterns的尝试与构建:如在编程领域构建起动态且灵活的Vibe Coding、融合数学形式化证明框架下的llm→lean4、将复杂数学空间求解与计算演进内化到模型隐参数空间中的AlphaEvolve&AlphaGeometry、在通用领域下执行多步推理规划与自反思验证的Deep Rearch & Research、Manus等诸多场景...可以说均得益于RL进一步的Post Training所带来的于跨领域或模态深度推理(DR)泛化能力的增强。
然而当下RLMs毕竟是通过所构建的多种静态tokenize符号化体系对所属state→action空间step by step exploration&exploitation而来,对于复杂跨领域任务下通过post RL带来的进一步泛化提升来说存在着不小的算法和工程上的挑战甚至瓶颈,因此未来在更大规模和广泛Multimodality或Agentic AI任务场景下还有着更多进一步的可alignment和scaling空间,这种潜在的空间可能包括从头pre RL过程中所涉及的复杂多模数据统一强化联合表征、在Multi-Agent框架下更多tokenize符号化形式空间体系融合以及所映射联动的更广泛的state→action认知流形空间分布…我想这也是建立从统一视角(第一性原理)来看待RL从LLM到Multimodality再到Agentic AI的核心关键,即,RL对于不同模态数据、不同符号形式化体系、不同动态规划下的决策与行为框架等映射到不同认知推理流形分布所呈现形式各异的Deep Reasoning Pattern的统一,而其中的“Pattern”则是关键!在Pattern中存在并充斥着各种纷杂模态数据的概率分布,各种逻辑严密的形式化逻辑链条以及各种Agent框架下state→action可探索与利用决策空间,它们都可统一为某种形式的“Pattern”。这听起来似乎有点绕且抽象,也许需要更多的实例列举会更具象,好在于现在已经有了很多前人的研究与探索了。
本篇将从整体技术趋势与判断、模型算法、工程思想及各类Agent分析洞察等几个方面分别围绕本章节主题进行论述,因此为了保障文章的完整可读,按照不同主题分段落论述。
1、系统②思维:慢思考革命与认知架构进化

卡尼曼的"双系统理论"如果说将认知过程中的快·慢思考,为模型打开了从train-time→test-time的范式新方向,我想其也将会进一步对智能体的持续进化提供关键视角。传统LLM受限于系统①在训练(pre-train→post-train→sft/rlhf)与推理(AR token predict)范式的直觉式响应,而新一代推理模型(如OpenAI o1/o3的深度推理模式、DeepSeek-R1的长链思维)正在持续探寻并突破系统②的慢思考可泛化空间。
而实现这种突破的关键在于:通过强化学习·RL,对可泛化空间的持续探索·Exploration和利用·Exploitation的平衡、尽量保障低偏差下的orm与prm监督、Reflection反思机制等创新技巧或思想嵌入,在生成token序列时模拟人类的分阶段认知过程——将碎片化可泛化假设建立链接、形式化逻辑推理的各种拓扑结构(链式/树状/图结构…)、可回溯性修正与增益机制…当模型能够将单次前向推理拆解为多步的"思维链·CoT",甚至是某种形式化的结构性代码或语言,并在其模型内隐参数空间或模型外以某种内存存储形式持续动态、环境感知的维护状态空间时,其所面对的复杂推理与规划能力便从静态单次生成响应跃迁为动态演进的认知过程,甚至上述所提及的“形式化的结构性代码或语言”,在实现了跨形式化符号体系间的可泛化迁移与延展之外,也可以进一步打破受某种语言符号体系下的结构性“黑盒”,从而亦收获了对推理可解释性或有效避免模型幻觉并保持推理规划稳定性的保障。
这种能力跃迁亦直接重塑了Agentic AI的工程架构,甚至在传统软件编码与软件工程中规划器(Planner)与执行器(Executor)的严格分层设计,某种程度上正被大模型所驱动的端到端认知流形所解构。如在早期的AlphaCodium为代表的代码生成系统验证下,当模型具备动态规划能力时,其代码生成质量不再单纯依赖单次即时响应,而是通过"生成-验证-迭代"的循环实现对问题空间的渐进式探索。这种认知闭环的形成,标志着AI工程开始从"确定性问题求解"向"不确定性环境适应"的历史性跨越。
2、自主规划智能体·Agent与工作流引擎·WorkFlow的互补与融合
当前大模型应用的两大技术路线——自主规划智能体Agent与自动化工作流Workflow — 针对第一类自主规划Agent,业界存在着一两种思想观点或子路线分支:
① 主张通过思维链、树状推理等prompt架构创新,激发LLM原生决策潜能;
② 通过强化学习对大模型在Agent真实环境进行某项决策能力专项优化;
上述两大技术路线表象上代表着两种认知范式的分野。前者更依托于模型背后复杂推理涌现能力以实现动态目标拆解,后者依赖预定义流程确保确定性输出。在众多开放域复杂推理任务执行范畴下,业界各种形式上的自规划Agent对比传统各类专家系统,通过LLM驱动下的长链多步推理及反思机制实现了更高的任务成功率以及展现出通用领域更强的泛化能力与灵活适应性,远超传统流程引擎的静态规则驱动模式。但当任务存在严格约束时(如金融合规场景、医疗临床规范化场景),结构化工作流仍保持着99.99%的更高的可靠性优势。
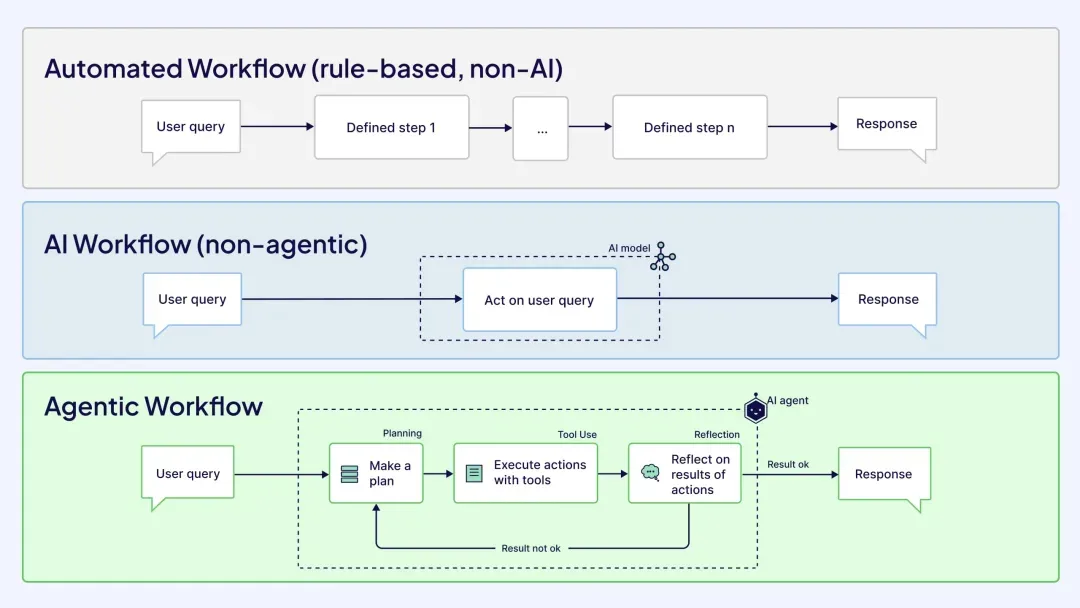
我想这种“分野”亦揭示了智能体在向传统数字孪生体系进化演进过程中的一些深层次矛盾与本质又或者促使我们以更高的另一种视角去审视这两者对现实世界中不同认知范畴下的对于不同任务与事务下的分而治之或融合可能:即如何在认知灵活性(Cognitive Flexibility)与执行确定性(Operational Certainty)之间对现实世界下的不同事务认知过程建立一种平衡?
如以近期比较火的Manus为代表的通用任务智能体,试图通过"结构化提示工程"实现两者的融合——将领域知识编码为思维模版,同时保留模型的动态调整能力。其在GAIA基准测试中展现了跨模态任务规划能力。其典型案例包括:接收含10份简历的压缩包后,自主完成解压、信息提取、候选人评估标准制定及排名建议生成,整个过程无需预设规则模板,完全依赖大模型对任务目标的动态解析。这种能力源于其多模型协同架构——底层由专用模型处理文件解析、数据清洗等结构化操作,上层通用模型负责意图理解与策略规划,形成"感知-决策-执行"的认知闭环。但其在金融会医疗等高度规范性、严谨性风险场景下表现也说明:纯文本驱动的反思机制仍难以突破事实性幻觉的桎梏,这暗示着符号系统与神经网络的融合也许将是下一代智能体的必由之路。
而以OpenAI Deep Research和Google AI Co-Scientist为代表的自主科研探索类任务Agent,则更充分展现了模型驱动下对于复杂动态推理泛化和探索验证类任务的规划与拆解能力。如Deep Research基于o3推理模型,通过"多步骤互联网探索与深度思考下的推理利用→信息整合反馈→报告生成"的闭环,实现了对复杂研究任务的端到端处理。其核心创新在于:将人类数小时的研究流程压缩为5-30分钟的自动化过程,通过对具备复杂推理与泛化能力的模型采用领域轻量化强化学习微调·RFT的模型版本(猜测),使其能够依据模型自身强大的可泛化能力实现自主规划搜索路径、交叉验证信息可信度,并生成结构化分析报告。例如在金融分析场景中,用户仅需输入"特斯拉2025Q1财报深度分析"指令,系统即可自动完成数据采集、财务比率计算、行业对比及风险评估全流程,输出达分析师专业水平的综合报告。
在自主规划智能体Agent与自动化工作流Workflow上,我想也许存在着某种假设或比喻:「自然结构定义 vs 社会结构定义· Agent vs WorkFlow」,即Agentic所处理的是类人类所擅长的自主性事务,依赖于更偏自然演化行动目标过程(依赖某种自然科学泛化性规律,如属加种差),高级一点的如认知泛化能力包括推理、分析、洞察等的泛化,低级一些的诸如感知能力的图像分类、识别等;WorkFlow则是倾向于程式化流程更偏社会性结构下的后天约束与规范性事务过程(依赖某种人类社会活动结构下的后天标准定义与规范遵循,当然这种后天的定义与遵循也许亦是约束于长期以来更高层级的合理性,但我想短期模型很难把握或学习其中的泛化内涵)。
其实这并不是大模型或Agent的出现带给我们的启示,在大模型与深度学习之前即存在。比如IBM深蓝所采用的专家系统或流行过一段时间的小模型驱动下的RPA即是尝试用规则程序类去进行推理决策,而对比金融系统中的高频交易即是一种非常适合于程式化去运行处理。
基于上述假设和比喻,再看Manus的局限性,因为其更多是基于上述“自然结构定义(或自然规律驱动下)的”自主规划、思考、行动,因为其所以依赖的是大语言模型所习得的泛化推理模式—— 大语言模型具备的泛化能力本身即是依赖人类在自然规律上进行自主思考、决策、行动而形成的自然文本符号所训练出来的Pattern。而Manus在面对上述程式化社会性结构驱动下预定义的workflow,则很难短期在大语言模型训练范式下进行训练并泛化(当然提示词工程是一种方法,但在面对更复杂的任务时,对模型指令遵循能力或提示词复杂度也是一种更高的挑战与成本),我猜想这里可能并不存在真正的自然结构下的模式泛化空间或者这种泛化的基础是建立在非常底层碎片化和多噪声干扰下的常识之上而对于模型来说很难掌握。比如工业半自动化生产线(需要综合依赖于考虑各种底层物理规律对各商品或零部件的不同流水线设计的影响,同时还要考虑安全、责任、规范的方方面面)、政务服务长流程(更多是社会化结构下所映射出的很难进行泛化的人性化与规范化要求)、以及在医疗规范化管理层面针对疾病诊疗与患者就医服务上的临床或管理路径(注意这里并不是指医学科学可泛化决策空间)。
这里插一下,其实Manus或类Deep Research去调用搜索引擎也是对搜索引擎本身自带的可泛化能力的一种依赖,因其“搜索”的关键核心是能够一定的将模型在预训练&后训练阶段很难习得的碎片化知识或经验进行纳入,不得不说这也是我对上一代技术的一种敬畏,就像我们人类一样,在寻求某种领域化或很难以通用常识去了解、判断某些知识时,通常万事不决搜索引擎,我想这也是上一代技术为我们留下的重要宝贵资产。试想一下,对于上一代技术创新为我们留下的宝贵资产在llm浪潮下进一步演进迭代优化,以补齐未来更多的Manus、DeepResearch或其它Agents对上述碎片化需求的短板(而这种短板也许是关键的最后一公里,也许是复杂规划过程中关键的环节),我个人还是非常期待的,下图举一个关于“搜索”的例子,虽然与我们通常使用的我厂的传统搜索引擎看起来不太一样,但AI Agent下的“搜索”我想亦应该被重新定义:

而且,Agent与Workflow两种运行时我想也并不是完全割裂而独立运行的,它们可能是简单的串行关系,也很可能是基于某种形式拓扑下深度依赖后所融合组成,比如对于更广泛的通用领域或者更有深度的专属领域在交互层上,GUI也好,LUI也罢或者其他形式的xUI,他们在错综复杂的不同人机交互界面之间进行切换或通信链接,更在任务执行或运行时进行着更复杂的基于模型原生泛化能力或后天人机提示工程下的自主调度、编排或规划。
同时,亦可通过跨形式化符号体系间对泛化能力的迁移,也可以在某些场景下进一步将两种任务执行模式有机的整合起来,并实现具备领域泛化与既定标准化+规范化流程的平衡,如近期一篇关于“大语言模型到决策树任务泛化能力迁移与转换思想”的论文,即能进一步印证两者之间未来的可探索潜力:

这篇文章的核心内容是介绍一种名为SMAC-R1的新型方法,用于解决多智能体强化学习(MARL)中的决策任务。SMAC-R1基于大型语言模型Qwen2.5-7B-Base(该模型是从DeepSeekCoder-v2.5-236B蒸馏而来的)。文章详细描述了这种方法如何通过生成决策树代码来提高策略的可解释性、转移性和探索效率,同时减少了对环境交互的依赖。
技术框架分为三个主要模块:Planner(策略规划)、Coder(代码生成)和 Critic(批评分析)。Planner模块根据任务描述和历史数据生成策略骨架,Coder模块将策略转化为Python脚本,Critic模块分析脚本性能并提供改进建议。生成的脚本通过监督微调(SFT)和直接偏好优化(DPO)进行初步训练,随后利用组相对策略优化(GRPO)算法进一步提升代码生成能力。
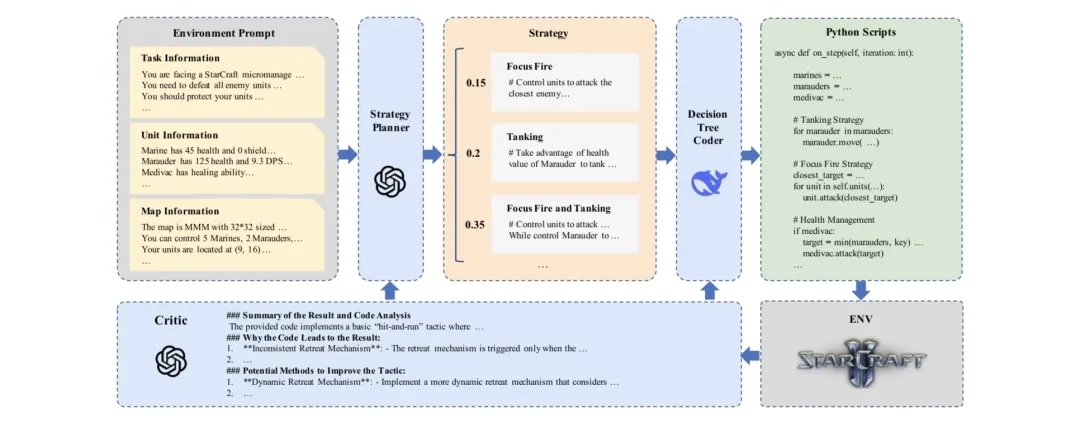
实验表明,SMAC-R1能够在最少的环境探索下生成高质量、可解释的决策树,并展现出强大的策略迁移能力,成功应用于同质SMAC环境而无需修改。这种方法不仅提升了MARL的效率和可解释性,还为未来决策任务和领域特定LLM训练提供了新的方向。同时,通过这种在跨形式化体系中对泛化能力与智能策略的迁移,可以实现对复杂任务进行分步拆解下进行多种Agent运行驱动模式的组合,并形实现对涉及各类Agent资源的高效组织。
回到Manus的局限性,我想正是由于对这种语言符号化空间泛化的依赖,使得其更难去适应在更复杂或抽象的可泛化空间中找寻可自主搜索或决策行动的模式,即便当前test-timescaling law下推理模型的长链多跳泛化能力涌现,但如前文所说,在更多非自然规律所主导下的结构性定义过程空间中,也许我们还未曾发现类似像llm这种生成式自回归tokenize训练与推理范式,又或者这种结构性过程空间中也许本身可泛化性非常稀疏,必须通过实现跨领域或跨模态空间知识泛化迁移才能习得并掌握对齐有效的流形分布或借助外部强大的工具(搜索引擎),又或者甚至这种可泛化的意义本身并不存在。
另一方面,在更加机械化、固定的、高频次的事务性任务执行模式下,这种类条件反射的肌肉记忆式的处理与执行,如果在计算成本以及工程优化未取得明显突破的情况下也采用llm驱动下的agentic来去重新推理、规划、设计、反思…也是一种对资源消耗的额外浪费且是完全不必要的。
我想对于未来更通用智能体或更专业领域化智能体的构建上会随着这些复杂要素间实现动态的演进或迁移,当然这也依赖于模型能否进一步在任务tokenize世界中得到持续强化反馈训练所建立的通用或领域泛化边界息息相关。
站在第一性原理的视角下,在最终的自主规划Agent或预定义WorkFlow两者间如何更好的互补与融合方面,其根本可能需要对广泛的通用/领域内多样化场景在整体任务和嵌套各子任务层级间针对其任务/子任务自身在不确定性、可探索性、可泛化性、可归纳性、灵活性、稳定性等方面进行综合判断与鉴别,其中上述各属性要素内涵的洞察分别体现于:
① 不确定性:指整体任务与各分解子任务在执行路径的不确定性,不太适用于先验指导遵循下的既定流程,如科学探索类任务对研究方法和研究工具使用的不确定性会更高,会对llm自主规划与执行依赖程度更高,而既定领域规范化事务性流程则确定性更高,则采用预定义的WorkFlow效率会更高。
② 可探索性:指整体任务与各分解子任务在不确定性基础上,其规划与执行路径的可探索空间广度与深度,同时在此属性要素维度上,我认为对于最终的探索结果成功与否和中间的探索历程轨迹优劣将同等重要且需额外关注并判断,在面向更高可探索性任务(如科学探索或数学定理证明)上,最终结果的成功与否与探索过程一方面可为背后所驱动的llm带来持续的学习反馈,一方面在此类任务上,也可为更多样化、动态丰富的人&机协作模式预留出可扩展、灵活的可操作设计、停顿反思等checkpoint空间。
③ 可泛化性:在明确洞察前两个任务属性要素下,对于llm驱动下的自主规划模式的选择可能需要跨领域交叉算法研究员判别其复杂的规划与执行是否具备在通用泛化的基础上在领域内进一步泛化(模型优化)的可能,以便通过fewshot或RFT等方法进一步对模型进行优化。而当经鉴别后,在明确领域任务或子任务不具备或很难具备自然可泛化性后,则需要考虑任务中建立稳定高效的WorkFlow机制组件。
④ 可归纳性:与上面的“可泛化性”对称,上述可泛化性是站在llm驱动下的自主规划Agent视角来考虑背后llm在领域内是否具备可优化泛化空间,而这里的“可归纳性”则站在WorkFlow视角下,尝试去人为先验的归纳总结模式和规律。
⑤ 灵活性与稳定性:这两个待审视评判属性要素放在一起来看,是相对的,Agent代表了灵活性而WorkFlow则代表稳定性,我们的工程、产品或算法研究人员则亦需要从上层业务视角本身来综合看待和评判所采用的不同技术路线—— Agent&WorkFlow。
⑥ 整体任务&分解子任务:通常情况下,不论是自主规划Agent还是预定义WorkFlow,都会或多或少面对整体任务规划下的子任务分解,如整体Agent下会嵌套隐含多个子Agent或子WorkFlow甚至是工具调用,整体WorkFlow下会包含多个子WorkFlow或自主Agent(听着有点绕),因此,在尝试以大模型原生重构一个新应用或开发一个智能化任务且面对的应用或任务比较复杂时,在选择自主规划Agent和WorkFlow之前,也许亦需要从整体宏观全局和微观局部进行更加系统性的分析,在了解全局任务要属性的基础上,更需对潜在的过程中的各分解子任务以上述视角进行判别和审视,甚至需要将上述Agents和WorkFlows进一步抽象为可灵活微调的组件或工具(形成肌肉记忆),供主任务结合不同任务模式和场景进行自主调用。我想这也是本章节自主规划Agent与预定义WorkFlow的其中一种融合的可能吧。
我想,对于上述几个属性维度的评判与审视技能,是未来大模型或智能体时代下每一位AI工程人员、AI产品经理甚至是以AIAgentic复杂规划、推理为核心进行算法开发的研究人员均需具备的洞察能力。
3.从实验室到产业再到实验室:智能体不同阶段、场景下的价值重构
当OpenAI的Deep Research能自主完成科研文献综述,Google的AI Co-Scientist可设计实验方案时,我们看到的不仅是工具效率的量变,更是科研范式的质变。这类智能体的核心创新在于将领域知识增强与模型推理能力深度耦合,并通过进一步构建的Training-time Post-RL范式与Test-time compute框架 — 以实现通过蛋白质结构数据库强化生化推理,借助数学形式化证明器提升多步逻辑推理与验证严谨性,通过多工具联合多次调用step by step解决复杂问题规划到拆解,这种"领域增强与强化型智能体"的出现,标志着AI正在从通用能力平台向领域专家系统进化。
而在企业级市场,各大小厂的大模型应用开发平台的快速崛起,则揭示了另一个技术趋势:大模型正在成为数字化转型的新操作系统。当业务逻辑可以通过自然语言编排,当API调用被抽象为语义接口,传统软件开发模式与成本结构将被彻底重构。而“Claude code”、“Cursor”等vibe coding也进一步掀起了在跨形式化语言体系下进行自主规划执行结构化任务上的信心,不过现有模型在处理跨形式化体系下的复杂任务规划设计与训练推理范式(如大型分布式事务处理、形式化数学定理证明、复杂策略代码逻辑编写、形式化奖励反馈与自验证体系的外围工具链配套建设)层面仍存在更多可探索空间,这也为为未来"AI+软件工程"的进一步融合进化留下了更多可能。
有趣的是,就在不久前,来自 Epoch AI(专注于预测 AI 未来发展的非营利研究机构)的研究员Ege Erdil 和 Matthew Barnett 在一篇长文中针对包括 Sam Altman(OpenAI)、Dario Amodei(Anthropic)和 Demis Hassabis(GoogleDeepMind)等在内的头部大模型公司首席执行官们所认为的“AI 的经济价值主要体现在实现研发(R&D)自动化方面” 的主流观点进行了反驳。他们认为,AI的经济价值主要源于广泛自动化而非 R&D,并从多个方面进行了论证,主要观点如下:
对于上述科学研究与探索·R&D方面,研究者从R&D所带来的经济价值与所面临的挑战两个方面进行了论证说明,不过我对于这种从站在常规经济效益和传统科学研究范式上去考虑AI4S的评判视角持保留意见:「即科学的突破与技术的变革也许并不能采用传统经济学视角和指标来进行可量化评估,科学的人发展与突破甚至会为未来经济结构带来变革;而站在当前传统科学研究范式的角度来看待未来AI4S或S4AI所带来的更多不确定突破与挑战,甚至是风险,也是难以立足的」。
当然,研究者同时给出了一个在“医学科学”领域的例证,并表示大多数 R&D 工作需要的远不止抽象推理技能。他们通过一份与医学科学家相关的工作任务列表-摘自 O*NET 职业调查,按对该职业的重要性进行了排序并根据“是否普遍认为只需抽象推理技能就能完成每项任务”,对其进行了标注——在这里,这意味着它需要纯粹的语言、逻辑或数学能力,包括撰写报告、编码或证明定理。
但我想研究者们也许对于其中llm或ai agentic在全局R&D任务中忽视了其中某些关键环节过程中探索与洞察到的重要科学意义,即便这些环节并非完全依赖于抽象推理,其科学价值与意义可能也不太适用于上述的简单统计分析来进行阐释。简单一点的例子如类似在AIDD领域在大规模分子空间借助AI加速虚拟药物筛选后的进一步的能力迁移与延展,复杂一点的如细微的研究范式变革带来的重大科学发现与技术突破。
为了更好的向大伙阐明AI Agentic为R&D或未来的AI4S所带来的技术价值与科学意义,我想举一个Google的例子:AI Co-Scientist,即定位于一个基于 Gemini 2.0 大语言模型构建的多智能体系统,它不是一个简单的工具,而是一位能够与科学家并肩合作的“虚拟科研伙伴”。AI Co-Scientist 旨在模拟科学研究的推理过程,帮助科学家产生新的研究假设、创建全面的研究概述、设计实验方案、分析复杂数据集、提出创新解决方案、模拟实验并预测结果和根据反馈和新数据调整方案等,协助科学家们加速科研发现。

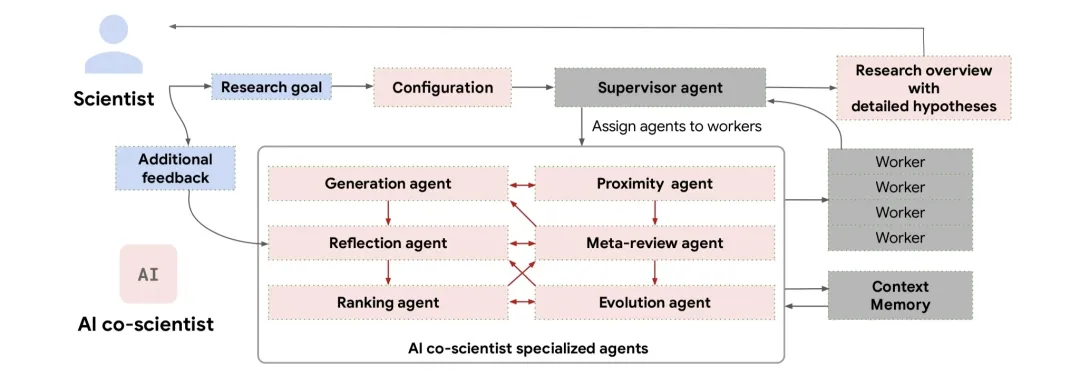
AI Co-Scientist 的核心在于模拟人类的科学研究方法。它通过多个AI智能体的协同运作,完整模拟从研究假设的产生到实验方案的设计整个过程。这些AI智能体使用自动反馈来迭代生成、评估和完善假设,从而形成一个自我改进的循环,即越来越高质量和新颖的输出。
这些智能体包括:
1)主管 (Supervisor) 智能体:负责统筹管理研究计划,合理分配研究任务,并对计算资源进行有效配置。
2)生成智能体 (Generation Agent):负责探索和分析大量科学文献以确定研究中的模式和差距,进行科学辩论,并根据现有知识生成初步的假设和方案。
3)反思智能体 (Reflection Agent):扮演科学同行评审员,评估假设和负责评估假设的正确性、创新性、质量和可行性。
4)排序智能体 (Ranking Agent):组织基于Elo的排名锦标赛,通过成对比较和科学辩论评估研究提案并进行优先级排序,优选最佳研究方向。
5)邻近性智能体 (Proximity Agent):构建邻近性图,对相似的想法进行聚类,计算假设之间的相似性,实现去重后并有效探索假设。
6)进化智能体 (Evolution Agent):迭代提炼并改进排名靠前的假设,融合现有观点,利用类比和文献,提高清晰度,以获得更深入的见解。
7)元审查智能体 (Meta-review Agent):综合所有评审意见,找出重复出现的模式,优化智能体的性能以及将假设提炼成供科学家评估的综合研究概述来促进持续改进。
在AI Co-Scientist具体运作流程上通过:
1)科学家设定研究目标:科学家使用自然语言设定研究目标,例如“寻找治疗肝纤维化的新靶点”。
2)系统解析目标: AI Co-Scientist 将研究目标解析为具体的研究计划配置。
3)智能体协同工作:主管智能体 (Supervisor Agent) 将任务分配给不同的工作智能体 (Worker Agent),并跟踪研究进展。
4)假设生成与评估:各个智能体协同工作,生成、评估、排序和改进研究假设。
5)结果呈现与反馈:系统向科学家呈现最佳的研究假设和实验方案,科学家可以提供反馈意见,进一步优化研究方向。
6)测试时间计算扩展:该系统利用测试时间计算扩展来迭代地推理、演化和改进输出。关键的推理步骤包括基于自我博弈的科学辩论,以产生新的假设;用于假设比较的排名锦标赛;以及用于质量改进的演化过程等。
在AI Co-Scientist进行复杂科学探索与推理过程中,研究者也通过真实实例发现并验证了先前llm或大多数Agent在AI驱动下面对复杂推理场景下这种自我博弈(self-play)下的test-time scaling law所带来科学意义与价值,如:
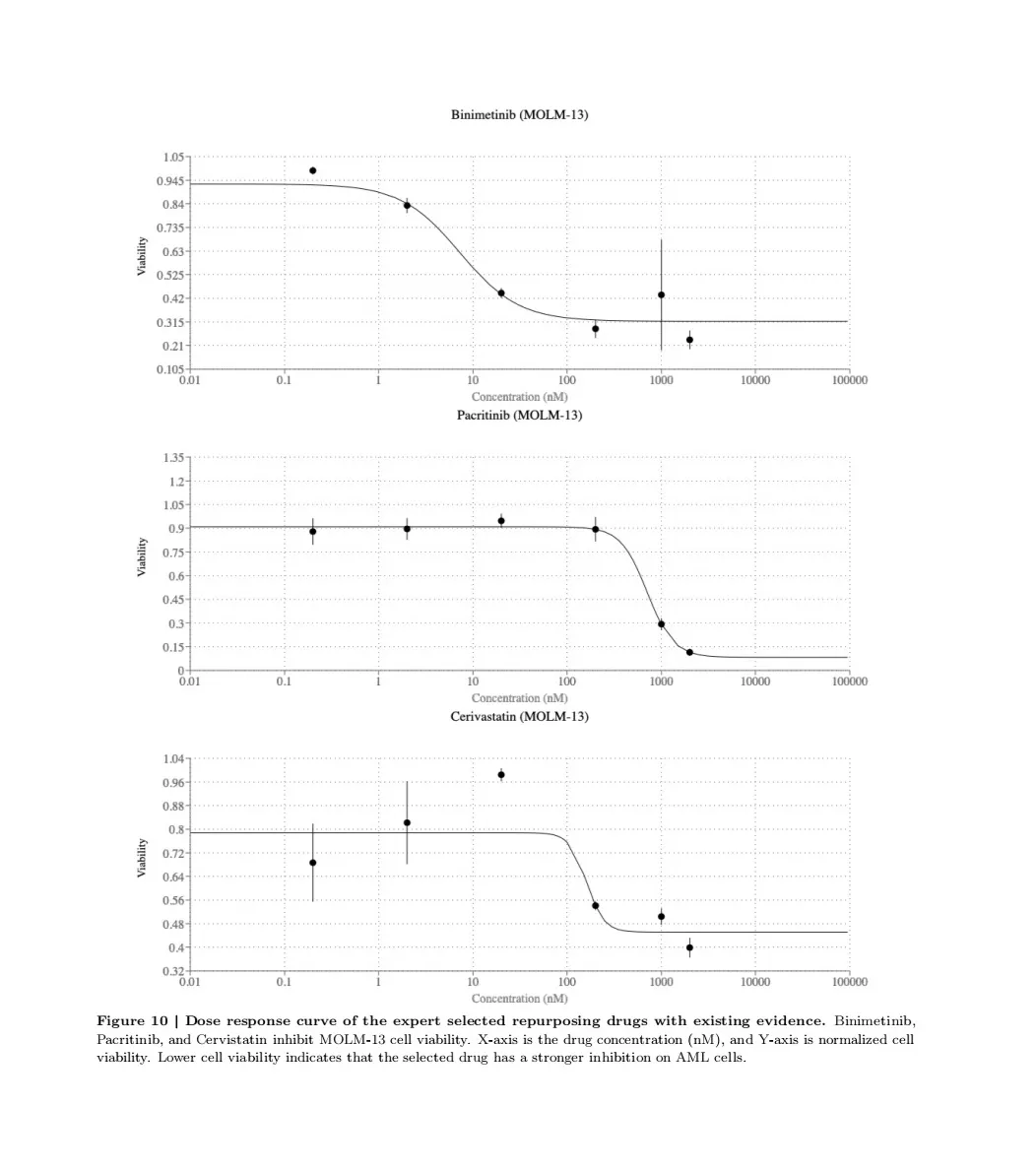
1)药物再利用 (Drug Repurposing):针对急性髓系白血病 (AML),AI Co-Scientist 提出了全新的药物再利用候选药物方案,随后的实验验证了这些提议,证实了建议的药物在临床相关浓度下抑制多种 AML 细胞系中的肿瘤活力。
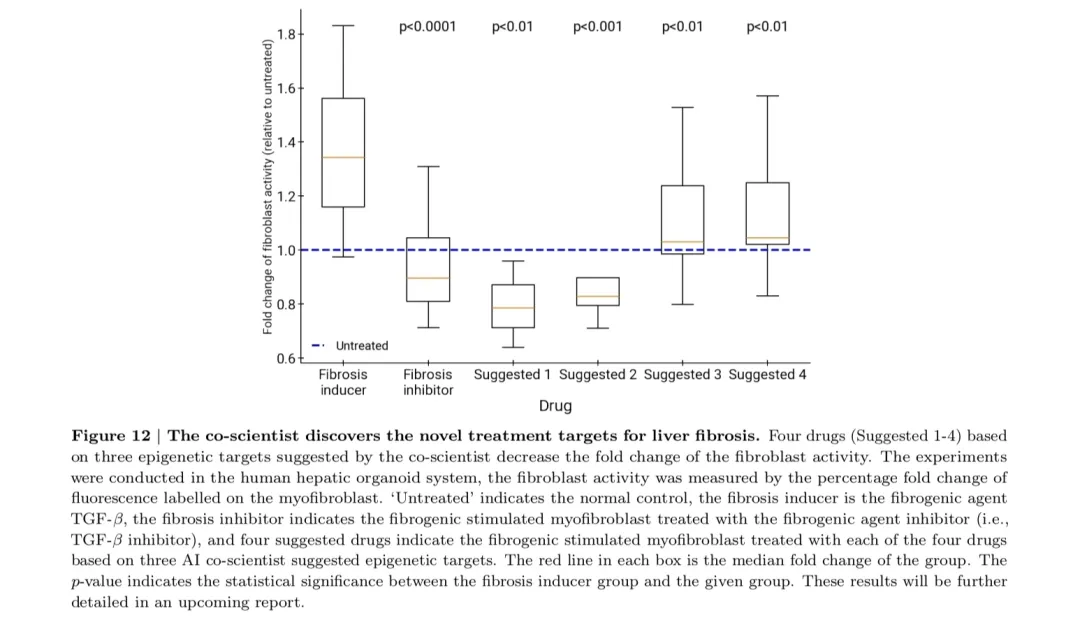
2)靶点发现 (Novel Target Discovery):在斯坦福大学推进的肝纤维化的治疗研究中,AI Co-Scientist发现了新的表观遗传靶点,并验证了其在人类肝脏类器官中的抗纤维化活性。
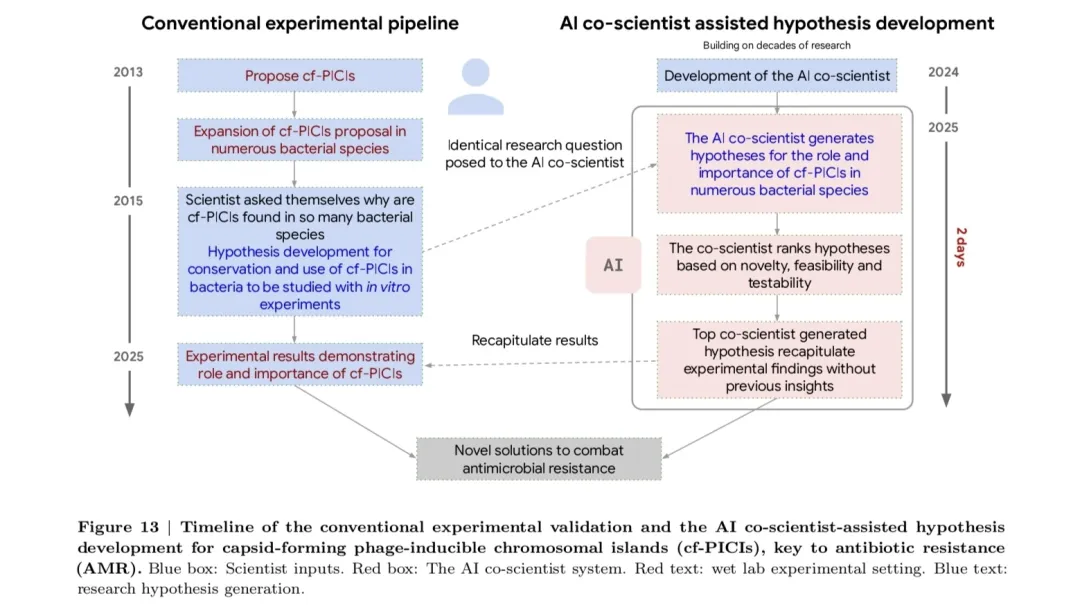
3)抗菌素耐药性 (AMR) 机制解释:AI Co-Scientist 仅用两天时间,便重现了伦敦帝国理工学院科学家们耗时十年才发现的细菌基因转移机制,为对抗抗生素耐药性提供了新的思路。
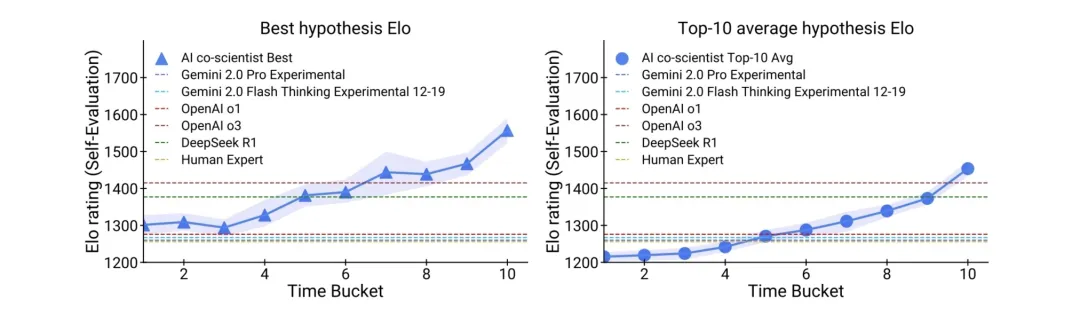
虽然,AI Co-Scientist在某些科学研究R&D领域还与人类在创造力和直觉方面存在一些差距,当前的主要定位还是辅助科学家,而不是取代科学家,协助处理数据密集型任务,例如文献回顾和数据分析,以解放科学家的时间使其能够专注于更具创造性的工作,但从上面的R&D实例来看,随着AI Co-Scientist随着底层模型与Agent协作机制在train&test-time scaling law上的进一步演化,相信在未来亦能够为科学家带来在创造性发现与探索的更多可能。
而在更广泛的产业级自主规划或自动化方面,如构建并定位在如下几个Agentic AI:
①实现更广泛通用Agent搭建(如Manus/Operator);
②为下沉到各领域产业实现灵活深度自定义工作流;
③为实现跨形式化语言符号体系深度融合而布局下的各领域强化自主框架(如Deep Research/Co-Scientist/各种Vibe coding);
我想对于上述多形式Agentic AI来说,未来在沿着基础模型在通用指令、深度推理、跨形式化语言体系间迁移转换的进一步进化,我相信也必将为AI Agentic带来更多期待与惊喜。试想一下,当未来随着基础模型的持续优化,基于上述多形式Agentic AI在工程融合上的进一步进化,并在领域知识、数据、工具组件及泛化能力的进一步增强,对于延展出各复杂R&D领域下AI4S Agentic增强版也就水到渠成了。
4.最后再盘点下Agentic AI应用RL的一些前沿进展与展望
在DeepSeek R1带火基于GRPO的强化学习技术后,我们看到Agentic Tool Use Learning也开始用上了GRPO、Reinforce++、PPO、policy gradient等各式各样算法。Agentic AI作为人工智能发展的下一前沿,正在从根本上改变我们构建和部署智能系统的方式。与传统的生成式AI(AIGC)不同,Agentic AI具备自主决策和行动能力,能够通过设计工作流和使用工具,代表用户或其他系统自主执行任务。这一特性使其在复杂任务处理中展现出巨大潜力,而强化学习技术正是实现这一自主性的核心驱动力。
Agentic AI的核心特性包括自主性(Autonomy)、环境感知(Context Awareness)、决策规划(Decision-making & Planning)以及学习与适应(Learning & Adaptability)。我们发现,这些特性与强化学习的目标在某些优化场景及环境的互动中高度一致,后者通过在环境中试错、接收奖励信号来优化决策策略。最近的研究表明,要让大模型学会使用code interpreter、web search等工具来增强现有模型的数学和推理能力,强化学习已成为不可或缺的训练范式。
在这一范式下,工具调用(Tool Use)被建模为强化学习中的动作选择问题:单轮调用对应单步决策,多轮调用则对应多步序列决策。然而,多轮工具调用面临两大核心挑战:一是高质量交互数据难以获取,二是建模方式不明确 — 传统MDP框架仅考虑当前状态,而复杂任务需基于完整历史状态建模。这些挑战催生了一系列创新性研究,涵盖奖励设计、多步优化、训练框架等多个方向。
在奖励设计的创新与突破方面:
在Agentic Tool Use Learning中,奖励函数的设计直接决定了模型的学习效率和最终性能。传统方法依赖粗粒度的答案匹配奖励,无法有效解决多工具调用中的信用分配问题(Credit Assignment Problem)。ToolRL(2025)首次系统性地探索了工具使用任务中的奖励设计策略,提出了一套原则性奖励方案,显著提升了工具学习的稳定性和泛化能力。
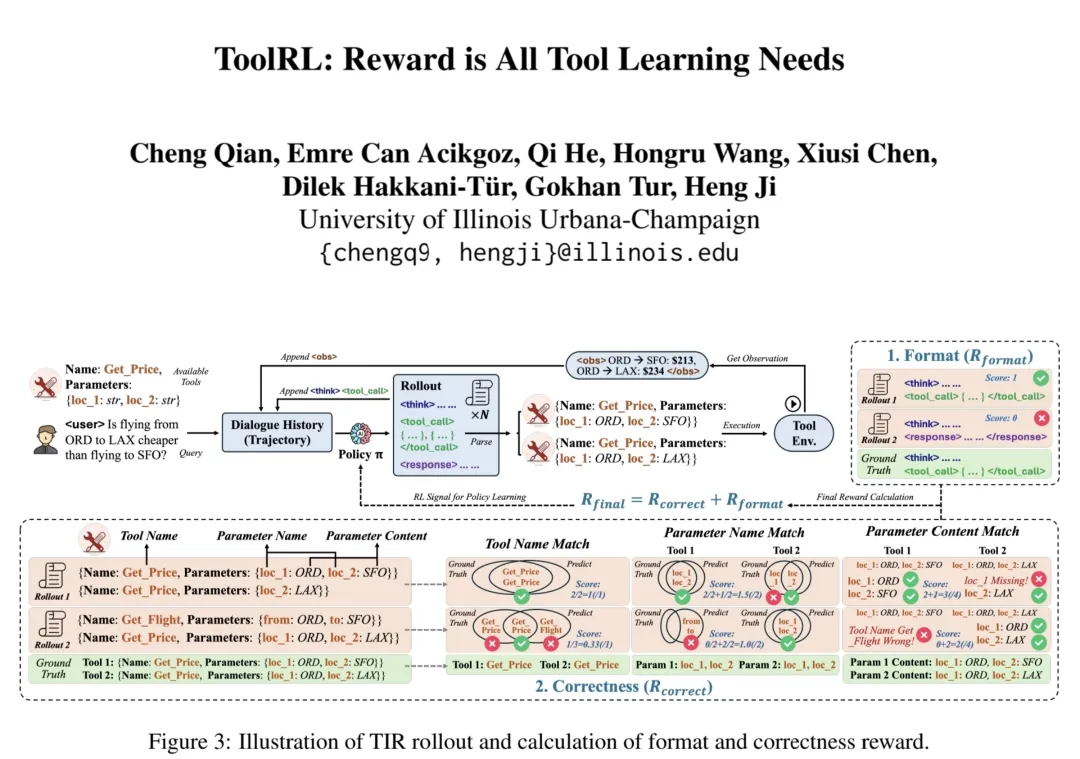
ToolRL框架的核心贡献在于其多层次奖励分解策略:
格式奖励(Format Reward):确保工具调用的参数符合JSON Schema规范(不过这一奖励正在被MCP所标准化)
执行奖励(Execution Reward):评估工具调用的成功率和效率
正确性奖励(Correctness Reward):验证最终答案的准确性
路径效率奖励(Path Efficiency Reward):鼓励以最少的工具调用解决问题
通过将奖励分解为多个细粒度组件,ToolRL在多样化的基准测试中相比基础模型提升了17%,相比监督微调(SFT)模型提升了15%。这一结果表明,精心设计的奖励方案在提升LLMs工具使用能力和泛化性能中具有关键作用。
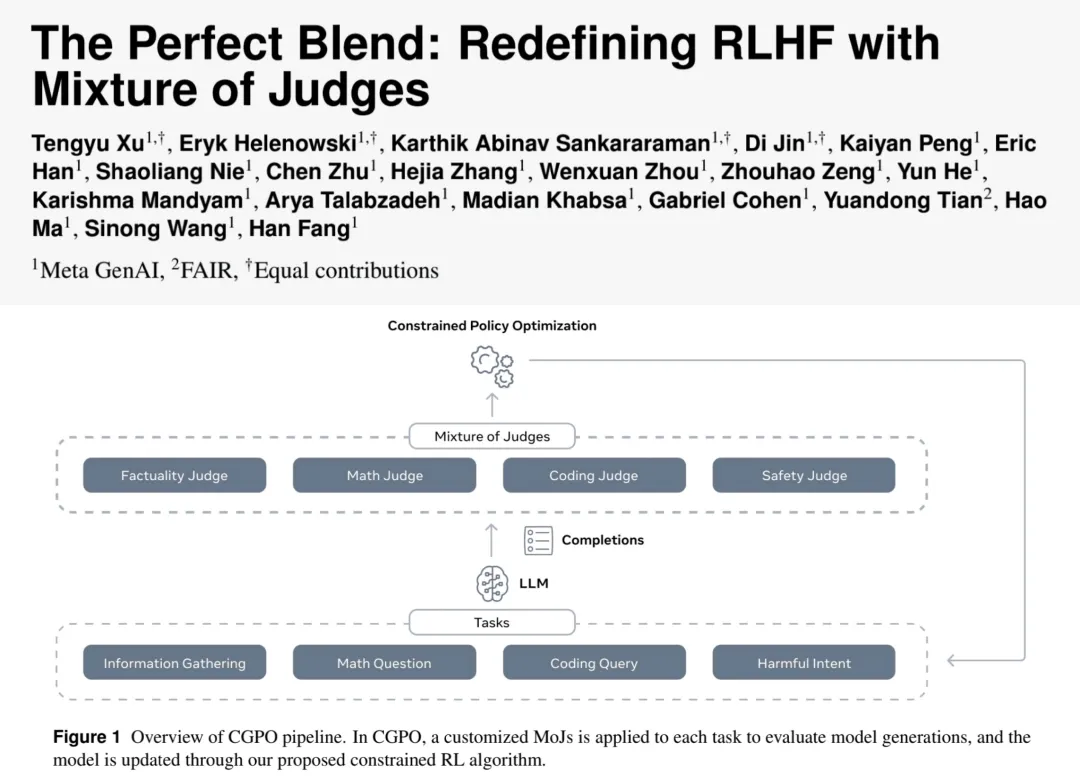
与此同时,Meta提出的CGPO框架(Constrained Generative Policy Optimization)创新性地采用混合评审机制(Mixture of Judges, MoJ)来解决多任务学习中的奖励欺骗问题。该机制结合了规则评审(检测代码生成、数学解题的正确性)和Model based评审(评估事实性、安全性),有效防止了模型过度优化单一任务奖励而忽视其他任务指标的问题。在HumanEval编程任务中,CGPO相比PPO提升5%,且避免了PPO训练中常见的后期性能崩溃问题。
另外,OTC-POs: Optimal Tool Calls with Policy Optimization论文中的方法以实现最优工具调用为目标,采用策略优化方法,通过构建特定的奖励函数和策略网络,使智能体能够在复杂环境中更有效地选择和调用工具。

GiGPO: Two-Level Hierarchical Advantage Estimation Strategy :亦提出了一种两级分层优势估计策略 GiGPO,通过在不同层次上对优势函数进行估计和优化,提高了强化学习算法在 Agentic Tool Use Learning 中的效率和性能。

在多轮调用与多步优化方面:
多轮工具调用(Multi-turn Tool Use)的复杂性在于需要模型进行多步推理和状态维护,这超越了传统单步决策的强化学习范式。SWiRL(Step-Wise Reinforcement Learning)方法通过分步轨迹分解创新性地解决了这一挑战。其核心思想是将每个多步轨迹拆分为多个子轨迹,每个子轨迹对应原始模型执行的一个动作,然后对这些子轨迹应用合成数据过滤和强化学习优化。
SWiRL的工作流程包含三个关键阶段:
1. 轨迹分解:将复杂任务分解为可管理的子任务序列
2. 合成数据过滤:生成高质量的子轨迹训练数据
3. 分步强化学习:对每个子任务进行独立优化
这种方法在多项多步任务上取得了突破性进展:
- 在GSM8K数学推理数据集上相对准确率提升21.5%
- 在HotPotQA多跳问答数据集上提升12.3%
- 在CofCA、MuSiQue和BeerQA等复杂推理数据集上分别提升14.8%、11.1%和15.3%
更引人注目的是,SWiRL展现出卓越的跨任务泛化能力:仅在HotPotQA(文本问答数据集)上训练,即可使模型在GSM8K(数学数据集)上的零样本性能提升16.9%的相对准确率。这一结果表明,分步优化策略有效捕捉了跨领域的通用推理模式。
多轮工具调用的另一创新方向是动态认知重组,如DCCA-RL(Dynamic Cognitive Contextual Agent with Reinforcement Learning)框架所示。该框架通过RL-GAN联合优化机制,根据任务复杂度动态调整推理策略。这种动态调整机制使智能体在面对简单任务时保持高效,在处理复杂问题时自动增强推理能力,大大提升了多轮工具调用的适应性。
在训练范式的进一步革新上:
当前Agentic Tool Use Learning的训练范式主要分为两大流派:“专家轨迹微调派”和“端到端强化学习派”。前者采用先SFT后RL的两阶段训练(如ReTool框架),后者则直接应用RL从头训练(如TORL,ToolRL,OTC等)。然而,这些方法均面临训练效率低下和系统支持不足的挑战。
在训练效率方面,国内某大厂大模型团队开源的HybridFlow(veRL)框架实现了重大突破。该框架采用混合编程模型,创新性地解耦了控制流与计算流:
单控制器(Single-Controller):管理全局控制流,保持算法灵活性
多控制器(Multi-Controller):负责分布式计算流,保证执行效率
这一架构革新为Agentic AI带来了显著的性能提升:
- 支持灵活的模型部署和多种RL算法实现
- 通过3D-HybridEngine技术优化训练与生成阶段的参数切换
- 实现零冗余模型参数重组,减少通信开销
- 训练吞吐量相比现有框架提升1.5-20倍
HybridFlow的核心创新之一是通用数据传输协议(Transfer Protocol),解决了大模型RL训练中跨模型数据交换的难题。
另外,在训练与推理的协同优化方面:
上述提到的CGPO框架在多任务优化方面取得突破。其创新性的多专家对齐(Multi-Expert Alignment)架构包括:
1. 任务分类器:将提示集按性质分类为不重叠的子集(如"有害意图"、"普通对话"、"推理任务")
2. 任务专属判定器:为每类任务定制评审标准(如推理任务关注正确性,普通对话关注真实性和拒答)
3. 梯度累积更新:各任务独立计算梯度后加权平均更新模型
这种设计使CGPO在AlpacaEval-2聊天任务上提升7.4%,在Arena-Hard STEM任务上提升12.5%,在HumanEval编程任务上提升5%,实现了真正的多任务优化。
对Agent整体框架规划与设计在强化学习训练的挑战与展望:
尽管目前的研究主要集中在 Tool Use Learning 上,但要实现更复杂的智能体整体框架的规划与设计的强化学习训练仍面临巨大挑战。
当前所面临技术瓶颈:
长序列决策效率低下:现有RL框架主要针对10步左右的任务设计,而真实复杂任务往往需要30-100步才能解决。受限于LLM的长上下文处理能力下降和计算效率问题,长序列决策仍难以高效实现。GRPO等基于规则的方法虽简化了流程,但仍需精心设计奖励函数和大量调参,开发成本高昂。
工具组合泛化不足:当前方法在已知工具组合上表现良好,但对未见工具组合的泛化能力弱。这源于训练数据的工具组合分布有限,以及模型缺乏组合推理的归纳偏置。
多模态工具协同困难:随着多模态大模型兴起,Agent需协调文本、图像、代码等多种工具。然而,现有框架多为单模态设计,缺乏跨模态状态表示和奖励设计。
安全与伦理风险:自主Agent可能出现错误操作,如产生垃圾邮件、传播假新闻甚至参与网络诈骗。现有防护机制(如RLHF)在复杂工具调用场景下效果有限。
同时,在未来Agentic AI整体框架强化学习的可行技术路径的更前沿探索上:
建议未来研究将全局Agent框架下的整体联合概率分布纳入到整体强化学习优化范式体系中来,而不仅是工具调用组件。
DCCA-RL(Dynamic Cognitive Contextual Agent with Reinforcement Learning)框架提供了前瞻性的设计思路。该框架通过“RL-GAN联合优化”实现Agent认知架构的动态重组:
生成器:提出模型结构优化方案(如层数、参数配置)
判别器:评估结构调整后的性能效果
RL代理:根据奖励信号调整推理深度和决策策略
这种"设计-评估-优化"的闭环使Agent能根据任务复杂度实时调整自身架构,例如在复杂数学建模中自动增加推理层并优化参数。
另一创新方向是分层强化学习(Hierarchical RL)在整体Agent设计中的应用:
1. 顶层Meta-Controller:学习Agent架构设计策略(何时增加记忆模块、何时启用工具等)
2. 中层Planner:制定任务执行计划
3. 底层Executor:执行具体工具调用
这种分层架构有望解决长序列决策问题,通过时间抽象(Temporal Abstraction)将30-100步任务分解为多个子任务。
同时,元学习(Meta-Learning)与强化学习的结合将为Agent设计带来新突破:
MAML-RL框架:学习模型架构的初始化参数,使其快速适应新任务
架构搜索(NAS)+ RL:使用强化学习自动探索最优Agent架构
跨任务知识蒸馏:将专家Agent的设计经验迁移到新任务
上述这些方法在当前更多处于探索阶段,且所采用的策略或方法不一定能够最终匹配或逼近更自主的广泛Agentic AI自身的行动轨迹空间,甚至上述方法也许对于通用或领域Agentic AI本身所采用的RL在State→Action空间的先验规划与设计仍存在更多不足或瓶颈,不过上述方法在在未来Agentic AI整体框架强化学习的可行技术路径探索上也为我们指出了一些可尝试探索的思路或方向。
对于超复杂Test-Time compute任务,多Agent协作系统将成为必然选择。我想除了上述在整体训练框架的进一步探索与演进的基础上,是否可以借鉴老早之前的分布式群体强化学习(Swarm RL)以优化多Agent协作中的分工,各专家Agent通过共享记忆池交换经验或不共享,Master Agent负责任务分解和结果集成。群体奖励机制鼓励专家间的有效协作并形成分布式状态与行动空间的持续奖励反馈。
巧了,结合上述“全局考虑下的Agentic AI架构强化学习优化”及“多Agent协作系统联合强化”思想,本周新出炉的一篇来自新加坡国立大学、南洋理工大学等高校的团队的预印版论文MaAS:《Multi-agent Architecture Search》正好可引用作为本章节最后部分的说明和阐释:
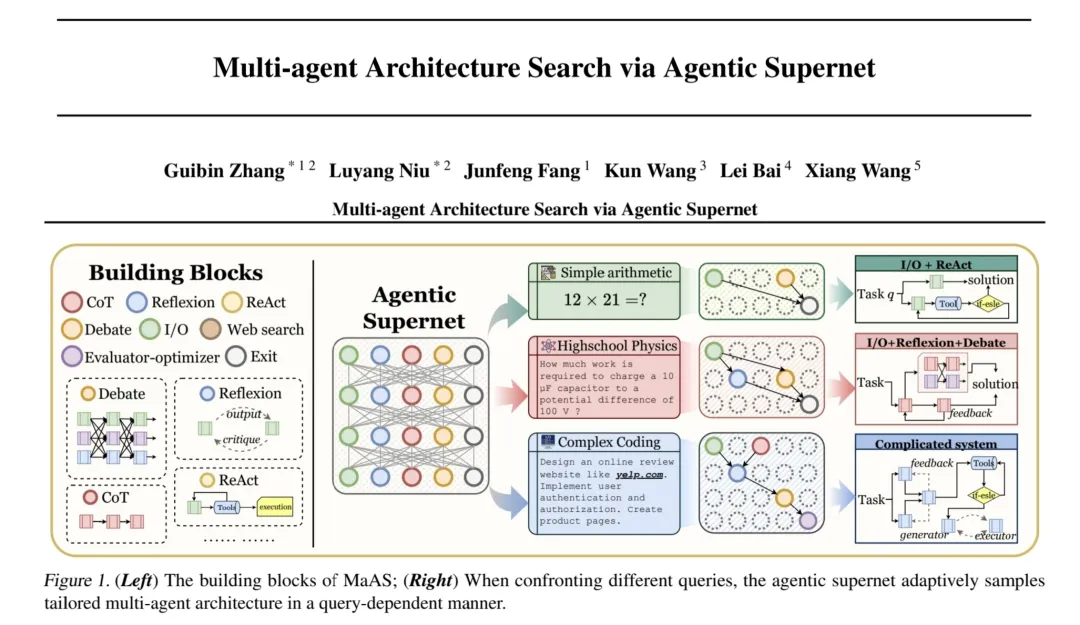
在这篇工作中,研究者们不再追求寻找一个“万能”的智能体系统,而是转变思路:构建并优化一个 “智能体超网”(Agentic Supernet)。可以把这个“超网”想象成一个经验丰富的“项目总监”。其包优势在于包含多种工作流,这些工作流由多种基础智能体算子(如 CoT、ReAct、Debate 等)构成,摒弃了固定团队模式,能够依据任务特性灵活组合。
当新任务抵达,智能体超网启动三步流程。首先,迅速评估任务类型、难度及特点;接着,从超网中即时采样并组合定制化的智能体团队;最终,以精简团队与合理流程达成高效执行。此流程标志着从 “静态重团队” 到 “动态轻组合” 的转变,赋予智能体协作智能、高效与经济性。
下面简单为大伙针对MaAS的工作原理与核心优势做一些剖析与介绍:
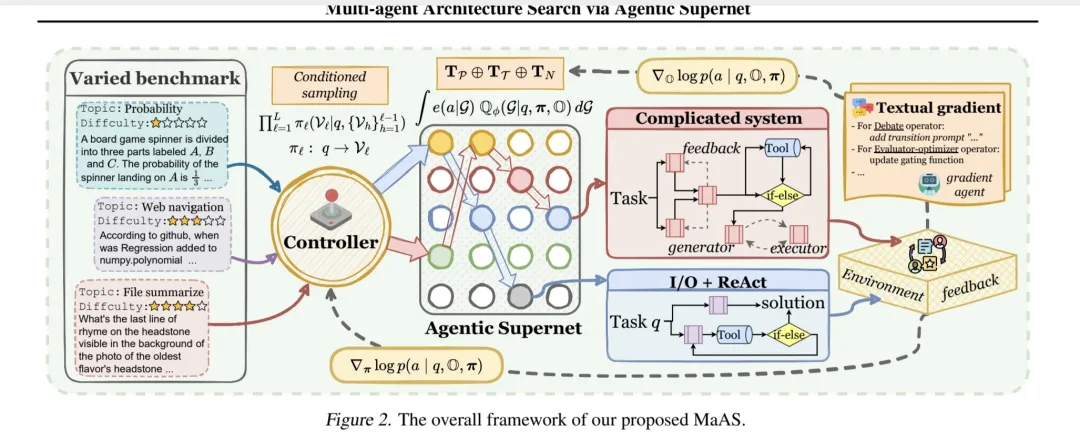
〔一〕智能体超网的构建基础
1. 模块化设计与通用接口规范
智能体超网采用模块化设计,预留标准化接口以兼容不同大语言模型(LLM)、工具及智能体算子。各算子作为独立模块,具备明确功能与输入输出规范,便于组合。例如,ReAct 算子可集成代码解释器或网络搜索工具,其接口确保与超网无缝对接。
2. 构建多层概率图结构与潜在路径探索
超网构建了多层概率图,各层代表任务解决的不同阶段,节点为智能体算子,边为算子间转移概率。面对任务,超网依据输入特性激活部分节点与路径,生成定制化工作流。以数学问题求解为例,第一层可能激活算子 A(用于初步问题分析),第二层根据第一层输出,选择算子 B 或 C(分别对应数值计算或符号推导),实现对不同解题路径的探索。
〔二〕查询依赖动态采样以精准匹配任务需求的智能调度
1. 任务特征深度剖析与多维度评估
控制器网络对任务进行多维度分析,提取关键词、语义信息、数据类型及用户意图等特征。例如,处理图像描述生成任务时,识别图像内容、风格、物体数量等关键信息,构建全面的任务特征向量,为后续算子选择提供精准依据。
2. 基于深度强化学习的采样策略优化
控制器网络基于深度强化学习不断优化采样策略。在与环境交互中,将不同任务特征模式与最优算子组合映射关系存储于策略网络。面对新任务,策略网络依任务特征快速输出初始算子组合建议,经采样执行、评估反馈后,更新强化学习模型参数,使采样策略持续改进,逐步精准匹配任务需求。
〔三〕联合优化与文本梯度,实现系统性能的持续进阶
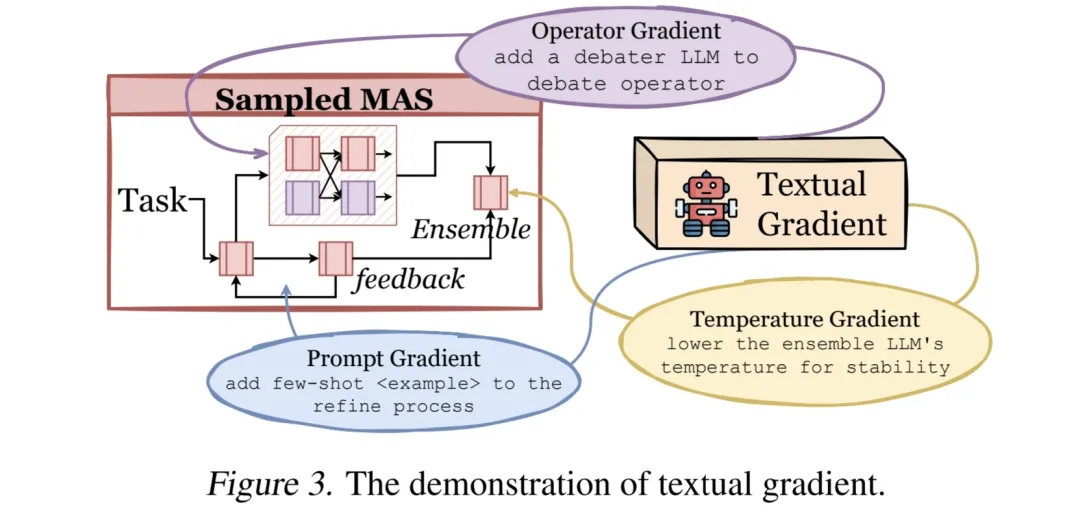
1. 控制器网络的强化学习优化机制
控制器网络的优化聚焦于强化学习中的奖励信号设计与策略迭代。奖励信号融合了任务执行的准确率、资源消耗(如 LLM 调用次数、token 使用量等)及时长等指标等多种奖励形式。在迭代过程中,采用Advantage Actor-Critic算法优化网络参数。智能体依当前策略选择动作,网络评估动作优势值,据此更新Actor网络参数,促使策略向高性能方向进化,提升采样效率与质量。
2. 智能体算子的文本梯度驱动的自我进化
文本梯度是本论文智能体算子优化的关键创新,以 CoT 算子的提示词为例,若某任务执行中 CoT 提示词导致模型推理错误,文本梯度机制分析错误原因,生成优化指令,如 “在提示词中增加对边缘情况的引导”。该指令融入原始提示词,形成新版本,经测试验证后替换旧版本,实现算子的持续优化。同时,文本梯度分析算子间紧密协作,识别信息传递不畅、职责不清等问题,生成优化指令调整算子连接关系与协作逻辑,提升系统整体性能。
〔四〕资源管理与成本控制以高效执行任务保障
1. 资源预估模型与任务调度的融合
MaAS 建立资源预估模型,训练时依据算子资源消耗数据(如执行时长、内存占用等),构建算子资源消耗特征库。任务调度时,结合任务特征与算子预估资源消耗,制定资源分配策略。复杂任务分配较多计算单元与内存,简单任务则精简资源配置,确保任务高效执行,提升系统整体资源利用效率。
2. 动态资源调整策略与实时反馈
任务执行中,MaAS 动态跟踪资源消耗与任务进度。若资源消耗异常,立即分析原因并调整策略。如网络搜索算子因搜索关键词不准确导致大量无关结果,增加计算负担,系统实时调整关键词或切换搜索算法,控制资源消耗,保障任务按时完成,增强系统对资源的掌控能力。
论文中也给出了MaAS在不同任务中动态而灵活的表现:
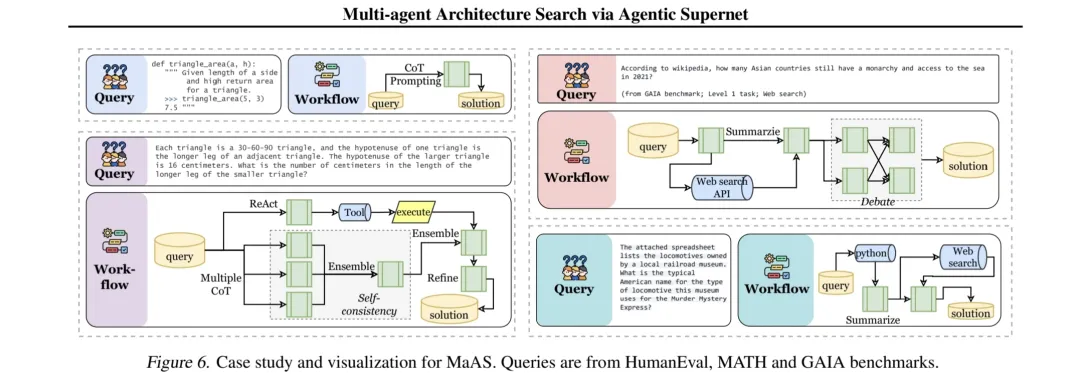
1. 简单计算任务案例 :输入查询为计算 42! 末尾零的个数。控制器网络识别任务特征后,在第一层倾向选择 ReAct 算子配备代码解释器工具,第二层则大概率选择 Early - Exit 算子,形成高效路径解决问题,避免资源浪费。
2. 复杂研究任务案例 :面对亚洲君主制海岸线国家查询,控制器网络在各层依据任务复杂性与信息处理需求,依次激活 ReAct(网络搜索)、Debate(论证反驳)、Refine(精炼整理)、Summarize(总结)等算子,构建复杂路径,确保答案准确性与全面性。
通过对上述MaAS的工作原理与核心优势介绍,相信大家对MaAS所带来的技术创新与潜在价值潜力上有着更深的认识:
在范式创新上,其从传统的寻找单一最优多代理系统转变为优化多个代理架构的分布,这种转变能够更好地适应不同查询的难度和领域差异,实现任务定制化的集体智能。
在自适应资源分配上,其通过代理超网络和控制器网络的协同工作,能够根据查询的复杂性动态分配资源,对于简单查询可以快速退出,减少不必要的计算开销;对于复杂查询则采样更多的算子和层进行处理,以获得更准确的解决方案。
在高效的优化方法上,创新性的结合了蒙特卡洛采样和基于文本的梯度估计两者差异,有效地更新代理超网络的参数,使模型能够在大规模的搜索空间中高效地寻找高质量的代理架构。
最后,针对MaAS,我想,作为一种自我学习的项目管理大脑,不仅动态组建合适团队,还在实践中持续优化团队成员与工作流程,实现了在效率与效果之间达成完美平衡,这种“端到端”的多智能体系统设计的范式从“寻找最优的单个系统”,转变为“优化一个系统的动态分布”的全新设计想法,为将来构建更通用、更经济、更智能的自动化AI系统的可能性打开了其中一扇门。
最后在本章节的结尾,做一下针对Agentic AI简单的总结与展望:
1. 统一的规划与决策框架 :建议设计一个能够将工具使用、环境感知、任务目标等多种因素统一考虑的规划与决策框架。该框架应能够根据智能体所处的环境状态和任务要求,动态地调整其行为策略,包括工具的选择、调用顺序以及与其他智能体的协作方式等。
2. 高效的奖励建模 :设计合理的奖励函数是强化学习的关键。对于复杂的智能体整体框架,奖励建模需要更加精细和全面,不仅要考虑工具使用的正确性和效率,还要考虑智能体在长期任务中的累积奖励、任务完成的时效性、资源消耗等多个因素。同时,还需要解决奖励的稀疏性和延迟性问题,以确保强化学习算法能够有效地引导智能体的学习过程。
3. 可扩展性和适应性 :随着智能体所面临的环境和任务的复杂性不断增加,强化学习训练方法需要具备良好的可扩展性和适应性。一方面,算法应能够在大规模的环境中高效运行,并能够处理大量的状态和动作空间;另一方面,智能体应能够快速适应环境的变化和新任务的要求,通过在线学习或元学习等方法实现知识的迁移和更新。
4. 多智能体协作与竞争 :在许多实际应用场景中,智能体往往需要与其他智能体进行协作或竞争。因此,研究多智能体强化学习方法,以实现智能体之间的有效沟通、协作策略的优化以及在竞争环境中的决策优化,对于复杂智能体整体框架的规划与设计具有重要意义。
BY 吕明
2025.6.12 凌晨
以上本文章最后完结,文章全文约4万字,从“对强化学习技术内涵进行本质思考与深度剖析”,到“从语言到视觉再到多模态深度推理”,再到“智能体(Agentic AI)与世界模型(World Models)在更广阔认知&行动空间下的动态探索与强化利用”,期待大家在经过粗度或分章节段落下的精度后,能或多或少为大家接下的研究工作带来一些观点的指引与帮助!同时也非常欢迎大家共同讨论、批评与指正。
文章来自微信公众号 “ 塔罗烩 ”,作者 吕明


【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
