# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
国产推理大模型又有重磅选手。
MiniMax开源MiniMax-M1,迅速引起热议。
这个模型有多猛?直接上数据:
MiniMax团队透露,只用了3周时间、512块H800 GPU就完成强化学习训练阶段,算力租用成本仅53.47万美元(约383.9万元)。
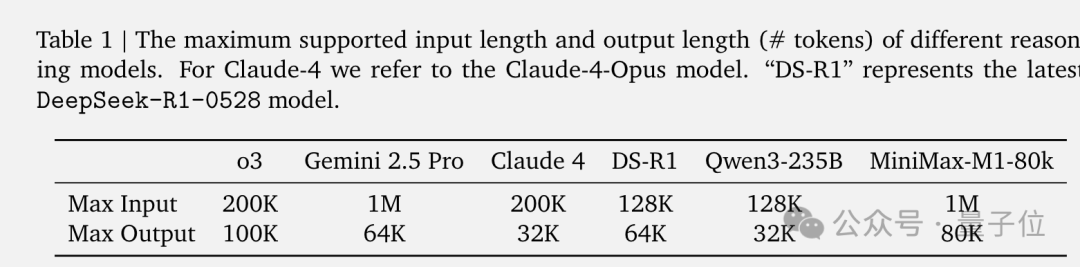
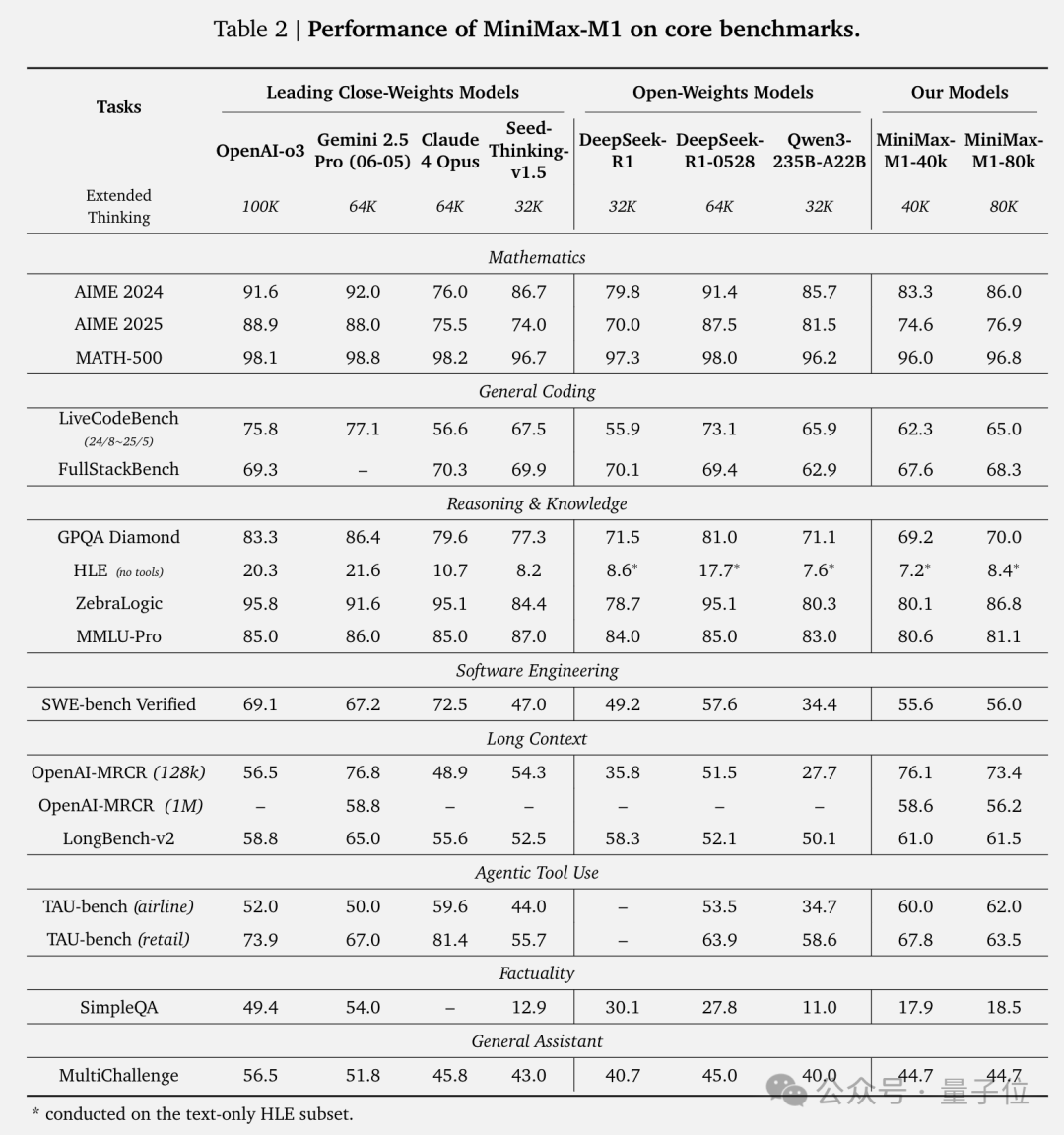
不仅如此,在多个基准测试上MiniMax-M1的表现可比或超越DeepSeek-R1、Qwen3等多个开源模型,在工具使用和部分软件工程等复杂任务上甚至超越了OpenAI o3和Claude 4 Opus。
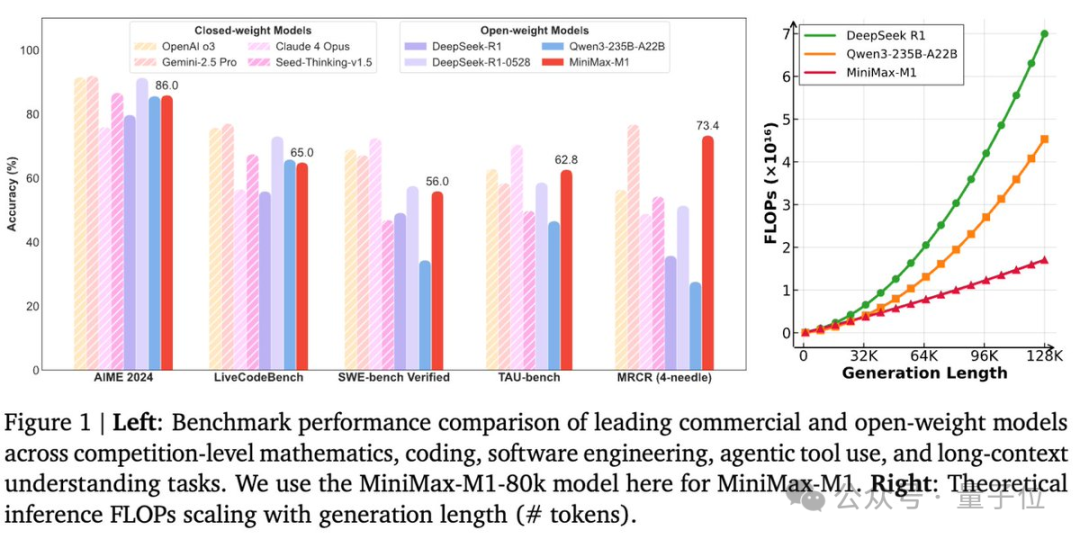
MiniMax-M1实战表现如何?官方给出了一句话生成迷宫小游戏的Demo。
创建一个迷宫生成器和寻路可视化工具。随机生成一个迷宫,并逐步可视化 A* 算法的求解过程。使用画布和动画,使其具有视觉吸引力。
目前模型权重已可在HuggingFace下载,技术报告同步公开。

同时已集成到MiniMax Chat网页版,可在线试玩。
MiniMax-M1一大技术亮点是采用了Lightning Attention机制的混合注意力架构。
传统的Transformer架构有个致命缺陷:计算复杂度是平方级,这意味着当模型进行更长的推理时,计算成本会急剧上升。
虽然之前有各种优化方案,比如稀疏注意力、线性注意力等,但在大规模推理模型上都没有得到充分验证。
Lightning Attention最早由上海AI Lab团队提出,此前已应用到MiniMax-01模型中。

具体来说,Lightning Attention把注意力计算分成块内和块间两部分,块内用传统注意力计算,块间用线性注意力的核技巧,避免了累积求和操作(cumsum)拖慢速度。
Lightning Attention还采用了分块技术(tiling)充分利用GPU硬件,让内存使用更高效,训练速度不随序列长度增加而变慢。
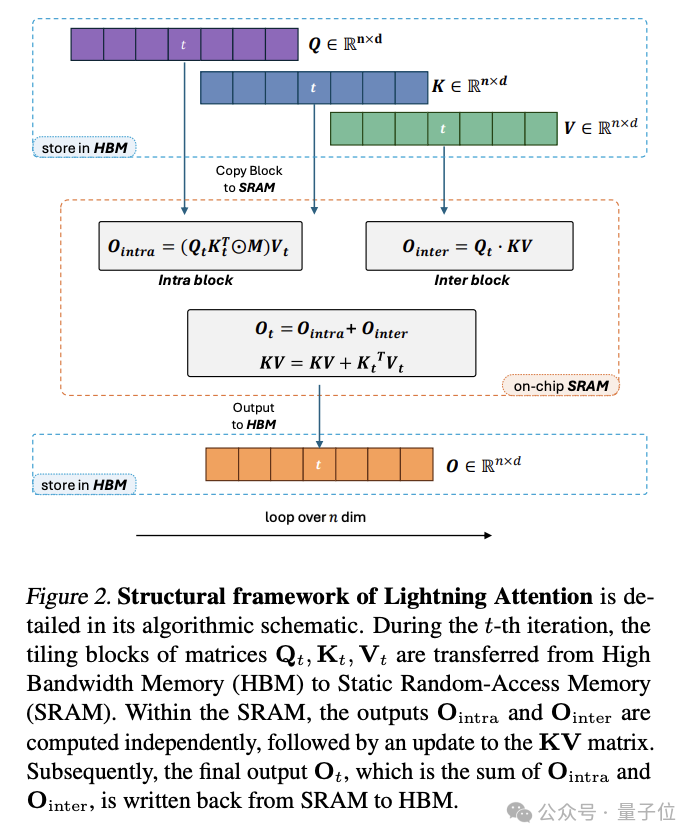
MiniMax-M1这次是在每7个Lightning Attention的Transnormer块后接1个传统Softmax Attention的Transformer块。
这种设计理论上可以让推理长度高效扩展到数十万个token。
更多Lightning Attention的介绍,可以看量子位与MiniMax高级研究总监钟怡然的对话:
MiniMax押注线性注意力,让百万级长文本只用1/2700算力|对话MiniMax-01架构负责人钟怡然
除了架构创新,MiniMax团队在提升训练效率上也有新招。
他们发现,传统的PPO/GRPO算法在处理混合架构时会出现严重问题。具体来说,那些对推理至关重要的“反思”token(如However、Wait、Aha等)通常概率很低,在策略更新时很容易被裁剪掉,导致模型无法学会长链推理。
为此,团队提出了全新的CISPO(Clipped IS-weight Policy Optimization)算法。
与传统方法裁剪token更新不同,CISPO选择裁剪重要性采样权重,这样可以保留所有token的梯度贡献,特别是在长响应中至关重要。
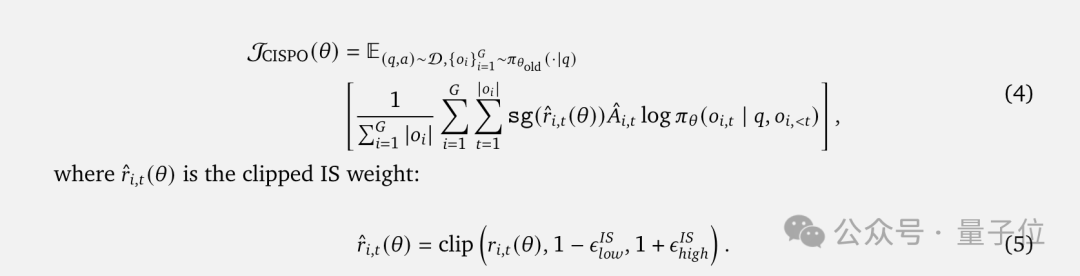
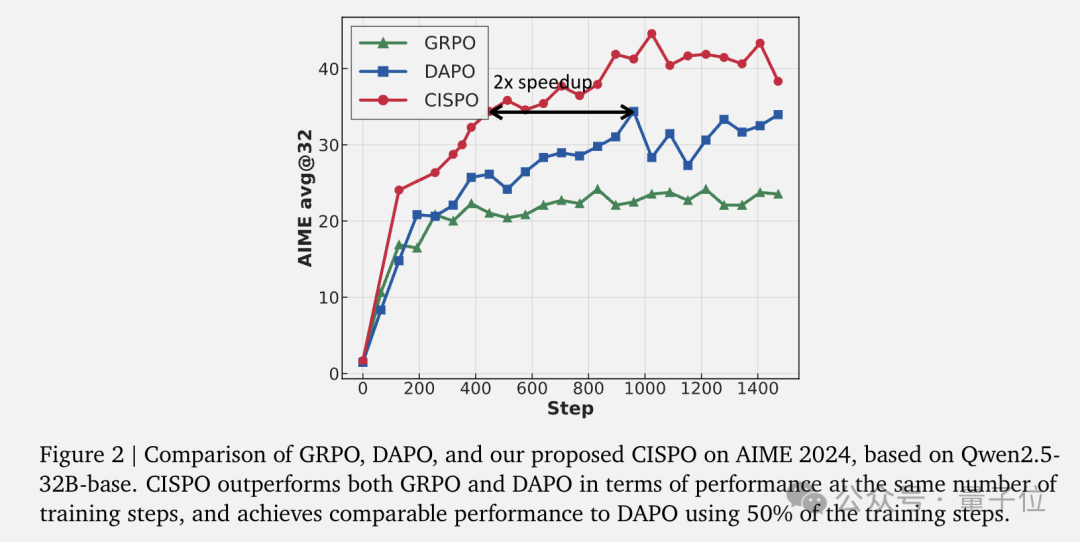
在基于Qwen2.5-32B模型的对照实验中,CISPO不仅显著超越了GRPO和DAPO,还实现了2倍的训练加速,也就是用一半的训练步数就能达到DAPO的性能。
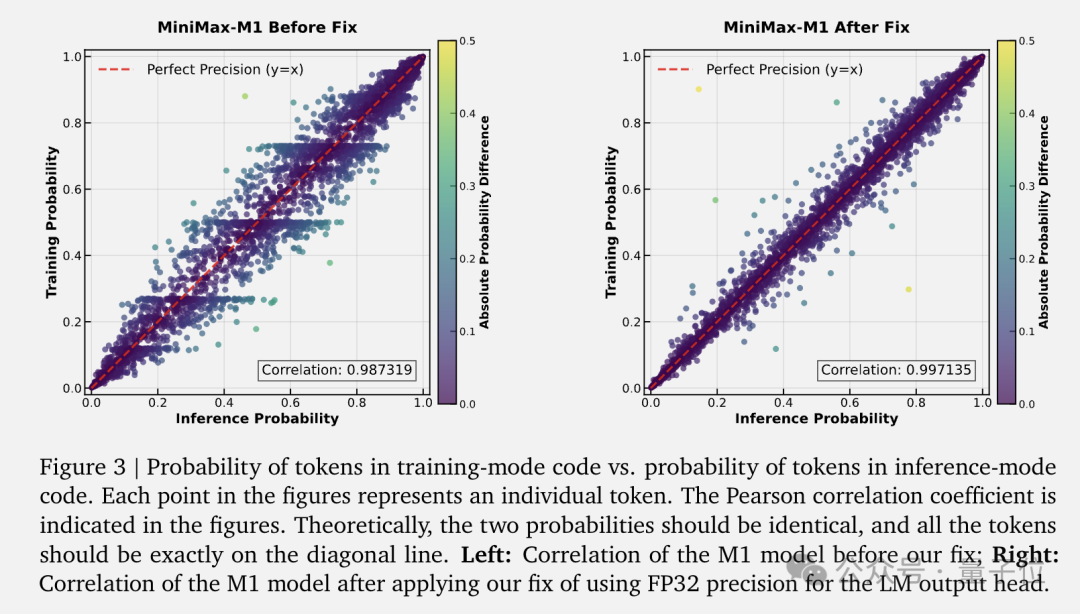
当然,将强化学习扩展到这种混合架构并非一帆风顺。团队遇到了一系列独特挑战,比如训练和推理内核之间的精度不匹配问题。他们发现LM Head的高幅度激活是误差的主要来源,通过将输出头的精度提升到FP32,成功将训练和推理概率的相关性从0.9x提升到0.99x。
此外,他们还开发了基于token概率的早停机制,当连续3000个token的概率都超过0.99时就终止生成,有效防止了模型陷入重复循环。
MiniMax-M1的成功还离不开精心设计的训练流程。
首先,团队在MiniMax-Text-01的基础上继续预训练了7.5万亿token,重点强化了STEM、代码和推理相关内容,占比提升到70%。接着进行监督微调,注入链式思考(CoT)模式,为强化学习打下基础。
在强化学习阶段构建了丰富的训练环境。
对于可验证的任务,不仅包含了数学推理和竞赛编程,还利用SynLogic框架合成了41种逻辑推理任务的5.3万个样本。以及构建了基于SWE-bench的真实软件工程环境,让模型在沙箱中实际执行代码,通过测试用例的通过率作为奖励信号。
对于无法用规则验证的通用任务,使用生成式奖励模型来提供反馈,特别关注了奖励模型的长度偏见问题,也就是模型可能会为了获得高分而生成冗长但无实质内容的回答。通过在线监控和动态调整,成功避免了这种”奖励黑客”行为。
上下文窗口的扩展则使用阶段性扩展策略,从4万逐步增加到4.8万、5.6万、6.4万、7.2万,最终达到8万,每个阶段都要等到困惑度收敛且99分位输出长度接近当前限制时才进入下一阶段。
最终,MimiMax-M1在数学推理、长上下文理解、工具使用和软件工程等多个领域表现出色,完整评估结果如下:
在MiniMax官方发布公告中透露,这只是为期5天的“MiniMaxWeek”活动的第一天。
随后海螺AI账号也确认即将推出更多内容。
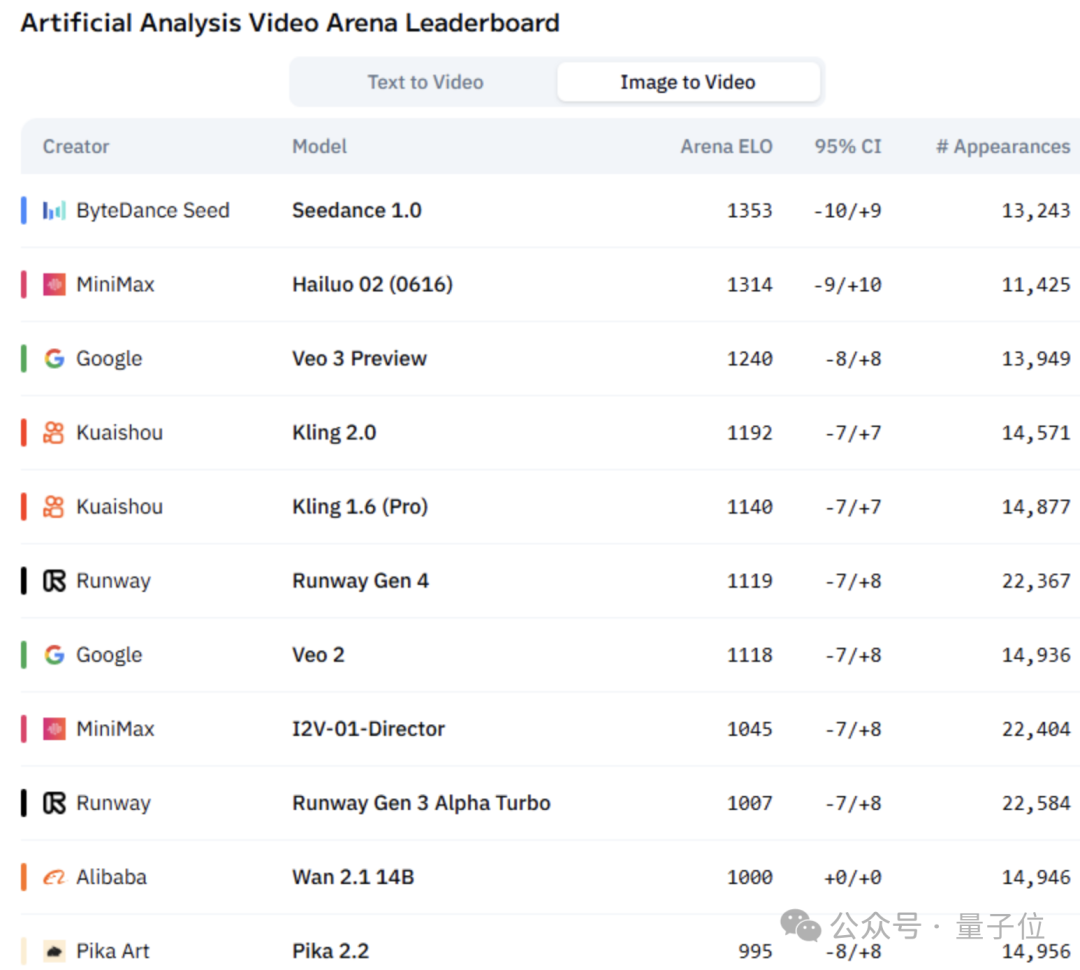
顺着这个线索,我们发现Hailuo 02视频模型出现在AI视频竞技场中,已迅速来到图生视频排行榜第二。
关于Hailuo 02和MiniMax将在一周内发布的其他内容,量子位也会持续关注。
在线试玩:
https://chat.minimax.io
GitHub:
https://github.com/MiniMax-AI/MiniMax-M1
HuggingFace:
https://huggingface.co/collections/MiniMaxAI/minimax-m1-68502ad9634ec0eeac8cf094
论文:
https://github.com/MiniMax-AI/MiniMax-M1/blob/main/MiniMax_M1_tech_report.pdf
参考链接:
[1]https://x.com/MiniMax__AI/status/1934637031193514237
[2]https://artificialanalysis.ai/text-to-video/arena?tab=leaderboard&input=image
文章来自于微信公众号“量子位”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
