# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
昨天深夜,月之暗面发布了开源代码模型Kimi-Dev-72B。这个模型在软件工程任务基准测试SWE-bench Verified上取得了60.4%的成绩,创下开源模型新纪录,超越了包括DeepSeek在内的多个竞争对手。
然而,当开发者们深入了解这个模型时,发现它明确标注了:Base model: Qwen/Qwen2.5-72B。这引发了一些人的疑问,Kimi-Dev的优异表现,究竟是创新还是“套壳”?

Kimi-Dev-72B并非从零开始训练的模型。根据月之暗面在Hugging Face上的说明,这个模型明确标注了Base model: Qwen/Qwen2.5-72B。在官方博客中也写到:以 Qwen 2.5-72B 基础模型为起点,我们收集了数百万个 GitHub 问题单和 PR 提交作为中期训练数据集。这意味着Kimi-Dev是基于阿里巴巴Qwen团队的72B参数模型进行二次开发的。
从技术角度看,Kimi-Dev的创新主要体现在训练方法上。月之暗面采用了大规模强化学习技术,让模型在Docker环境中自主修复真实代码仓库的问题,只有当完整测试套件通过时才能获得奖励。这种训练方式确保了模型生成的代码不仅正确,而且符合实际开发标准。
在软件工程任务基准测试上,Kimi-Dev-72B展现了出色的性能。它在SWE-bench Verified上取得了60.4%的成绩,这是一个专门评估模型解决真实GitHub issues能力的基准测试。相比之下,前一名开源模型的成绩仅为约50%左右,Kimi-Dev实现了显著的提升。
在许可证方面,Kimi-Dev-72B的LICENSE.md文件显示其采用MIT协议发布。

但同时,月之暗面也在文档中明确说明:“Kimi-Dev-72B is built with Qwen-2.5-72B. Qwen-2.5-72B is licensed under the Qwen LICENSE AGREEMENT, Copyright (c) Alibaba Cloud. All Rights Reserved.Subject to the Qwen LICENSE AGREEMENT, Kimi-Dev-72B is under MIT license”。
也就是说Kimi-Dev-72B需要遵守Qwen-2.5-72B的原始许可限制,同时将自己的创新工作(即通过强化学习获得的微调权重)以MIT协议开源。这种做法在开源社区中被称为“delta权重”发布,即只发布相对于基础模型的增量部分。
争议的起源是社区对“月之暗面是否获得了使用Qwen-2.5-72B的特殊许可”的质疑。根据Qwen的许可协议体系,虽然较小的模型采用Apache 2.0协议,但72B这个旗舰模型采用的是《通义千问许可协议》(Qwen LICENSE AGREEMENT)。
这份协议规定,当产品的月活跃用户(MAU)超过1亿时,需要向阿里申请商业授权。考虑到Kimi作为热门AI助手的用户规模,可能将Kimi-Dev-72B引入其产品,这个限制条款引起了关注。
面对社区询问,Qwen团队负责人林俊旸(Junyang Lin)在X平台上的第一个回复简短而直接:"no we did not give them the permission"(不,我们没有给他们授权)。
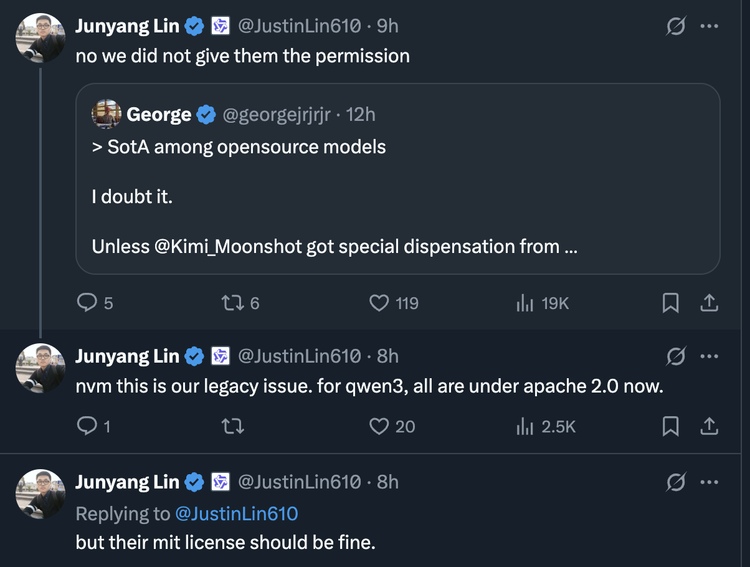
这个回复立即引发讨论,然而,仅仅一个多小时后,林俊旸发布了第二条推文,改变了事件走向:“nvm this is our legacy issue. for qwen3, all are under apache 2.0 now.”(没事了,这是我们的历史遗留问题。对于qwen3,现在所有模型都采用apache 2.0协议了。)
林俊旸的第二条推文揭示了问题的本质,这不是月之暗面的违规使用,而是Qwen团队自身许可策略演进中的“历史遗留问题”。
具体来说,Qwen2.5系列采用了复杂的分级许可体系:大部分模型(包括 0.5 B、1.5 B、7 B、14 B、32 B、VL、Omni 等)采用Apache 2.0协议,属于完全开源许可,而3B和72B模型采用的是《通义千问许可协议》,包含商业限制条款。
这种分级许可策略在开源社区中并不罕见,目的是在推动技术普及的同时保护核心商业利益。但随着时间推移,Qwen团队可能意识到这种策略可能会阻碍生态发展。
在2025年4月底发布的Qwen3系列中,所有模型都已经采用了更加开放的Apache 2.0协议。Apache 2.0是一种广受欢迎的开源协议,它具有以下特点:
通过全面转向Apache 2.0,Qwen试图正在构建一个更加开放和活跃的AI生态系统。
在这种背景下,将Kimi-Dev基于“旧协议”模型的使用定性为“历史遗留问题”,实际上是一种着眼未来,支持生态伙伴的创新的选择。
从技术角度看,这个案例反映了当前AI创业的现实。根据MosaicML的数据,训练一个达到GPT-3质量的30B参数模型需要约45万美元,而更大规模的模型如70B参数级别,成本会达到数百万美元。对于希望从零开始训练一个70B模型的机构来说,需要准备好数百万美元的基础预算,还需要配备顶尖的AI研究和工程团队,并且要考虑到随着技术发展,未来模型的训练成本可能会进一步攀升。
而月之暗面选择Qwen-2.5-72B作为基座并非偶然。根据多项评测,Qwen2.5系列在代码、数学、多语言等方面都达到了业界领先水平。站在这样的基座模型上,月之暗面可以在类似这样的研究项目中,将资源集中在自己的核心优势——强化学习训练方法上。
NebulaGraph GenAI负责人Wey Gu对硅星人表示:“我认为他们(Kimi)的开放权重、透明地分享paper的工作对社区是非常有益处的”,他还指出,Kimi-Dev分发MIT协议的delta权重文件没有问题,“不过模型的消费者是绕不过base model的Qwen license的”。
值得注意的是,尽管Kimi-Dev在SWE-bench上取得了优异成绩,但实际应用中仍有改进空间。有开发者测试发现,模型生成的代码有时需要调试才能运行,对复杂需求的理解也不够完整。这说明即使基于强大的基础模型,要做出真正优秀的垂直应用仍需要大量创新。
这场“套壳”争议最终成为了一个行业发展的缩影。开源策略正在从限制性许可向完全开放转变,这是赢得开发者生态的必然选择。同时,基于优秀基础模型的“二次创新”正在兴起,关键是找到自己的差异化价值。大厂与创业公司不再是简单的竞争关系,而是在开源生态中形成新的协作模式。
随着更多的开源模型采用Apache 2.0协议,类似的许可争议将越来越少。而像Kimi-Dev这样基于开源模型的专项优化案例,或许会越来越多,这正是开源AI生态繁荣发展的标志。
文章来自于微信公众号“硅星人Pro”,作者是“周一笑”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
