# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近,我的AI交流群和别的一些AI群都炸锅了,话题的焦点是MiniMax-M1
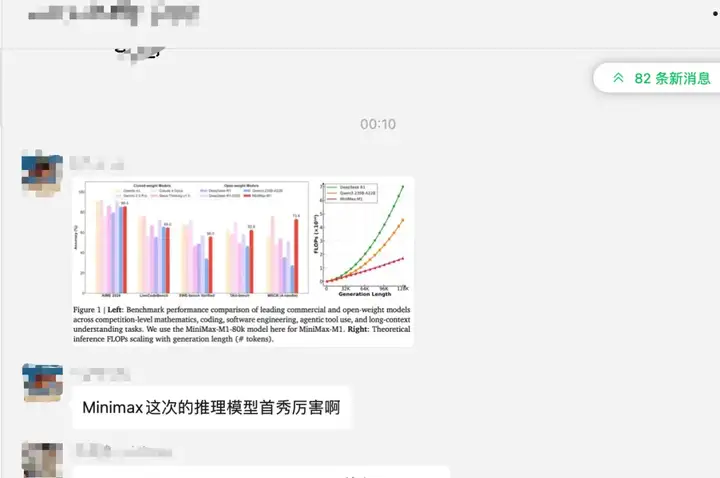
就在昨天,MiniMax把他们自家最新的旗舰推理模型MiniMax-M1开源了!
这个操作就好比某一天OpenAI突然把他家的推理模型O3开源一样(讲个笑话)
格局真滴大,不像对岸的"Close AI"
我愿称之为新一代源神!先来看看跑分
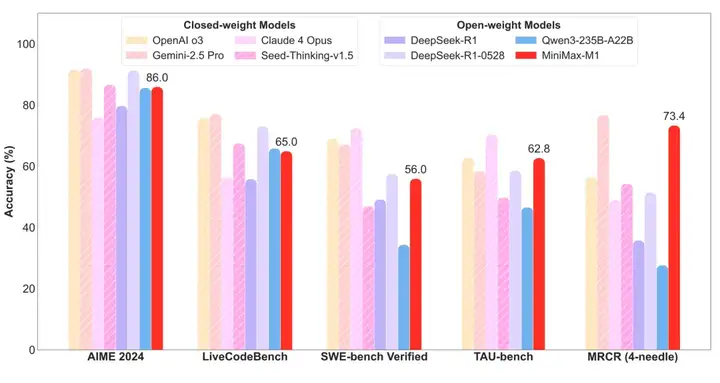
作为开源模型,MiniMax-M1的各项性能直逼国外的闭源模型:Claude 4 Opus、Gemini-2.5 Pro、OpenAI O3
这个跑分的解读可以看看卡子哥的文章,非常详细,而且通俗易懂
MiniMax-M1解读
数字生命卡兹克,公众号:数字生命卡兹克MiniMax深夜开源首个推理模型M1,这次是真的卷到DeepSeek了。
我们本次重点看这个跑分图里,最后一组数据:MRCR(4-needle),远超其他大模型,仅次于Gemini-2.5 Pro
MRCR(4-needle)代表的是多轮共指消解(Multi-Round Co-referenceResolution)任务里,在超长文本上下文环境中"埋设"4个关键信息片段(即 “针”)的测评场景,用于评估大语言模型在复杂长文本、多轮交互情境下的上下文理解与信息检索能力
MiniMax-M1也成为了世界最长上下文的推理大模型
支持100万tokens(1M)输入和8万tokens的输出。
要知道DeepSeek R1才仅仅支持128K上下文。
而且MiniMax-M1官方API的价格也是非常香,就白菜价,随便用。
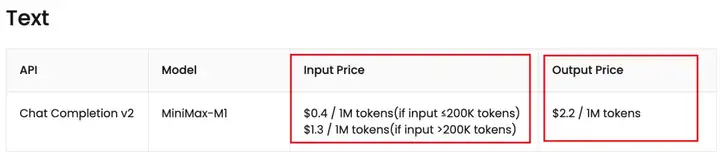
下面是国内的API价格
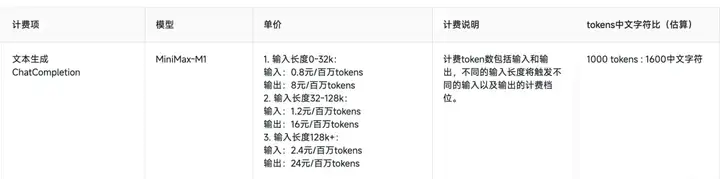
说实话,大模型支持的上下文长度,和上下文理解能力非常重要!
群友今早也在研究,但是不清楚MiniMax-M1的优势可以有效的应用到哪些场景。
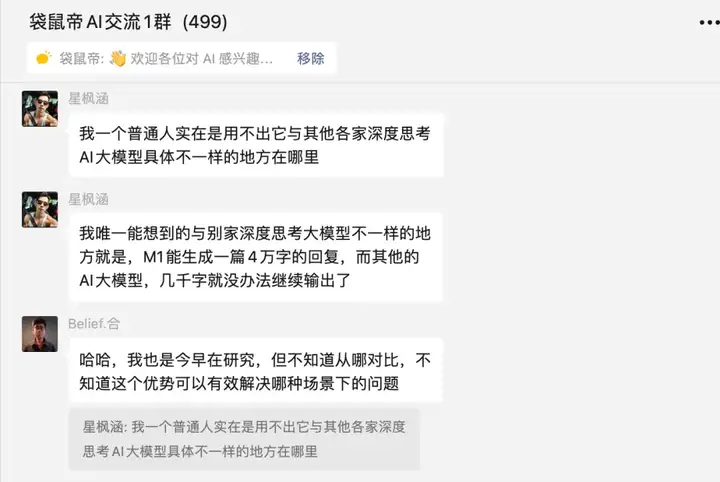
于是我整理了5种非常实用的场景(涵盖API),逐一测试,效果都不错,分享给大家。
在测试之前,我们先做好准备工作
目前MiniMax-M1在MiniMax官网就能使用
海外地址:
https://chat.minimax.io/
国内地址:
https://chat.minimaxi.com/
记得开启Think,否则使用的是MiniMax-Text-01

同时,为了方便后续API的测试,我们还需要获取MiniMax的apikey、API地址
本次测试我使用的是MiniMax海外版
原因无他,还剩很多余额
先访问如下地址创建apikey
https://www.minimax.io/platform/user-center/basic-information/i
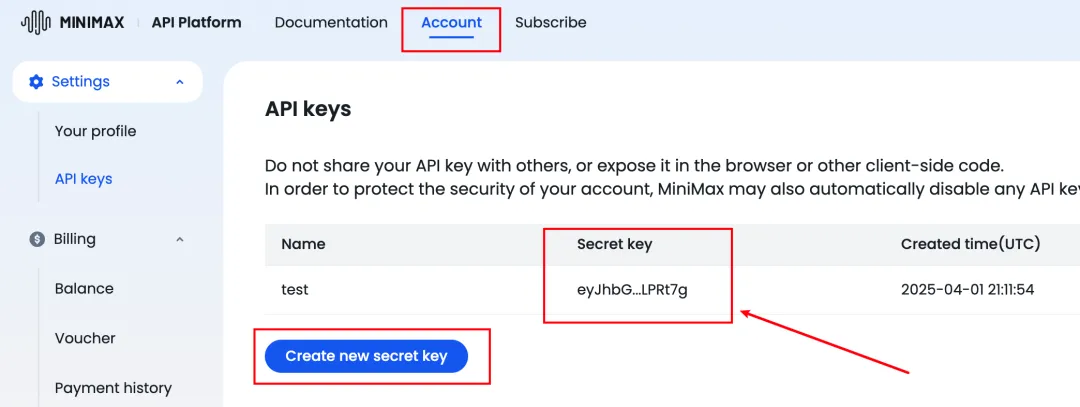
MiniMax的海外版聊天API地址:
https://api.minimax.io/v1/text/chatcompletion_v2
MiniMax的国内版聊天API地址:
https://api.minimaxi.com/v1/text/chatcompletion_v2
模型名称就是:MiniMax-M1
好了,话不多说,直接开始
这个Case来自群友@星枫涵
他要求MiniMax-M1输出3万字的S500防空导弹的详细介绍



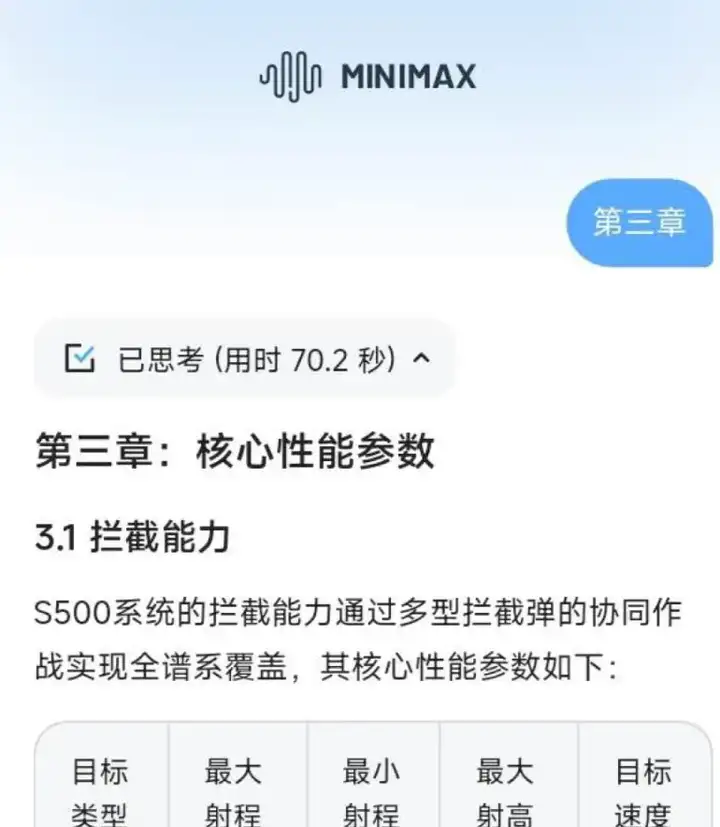


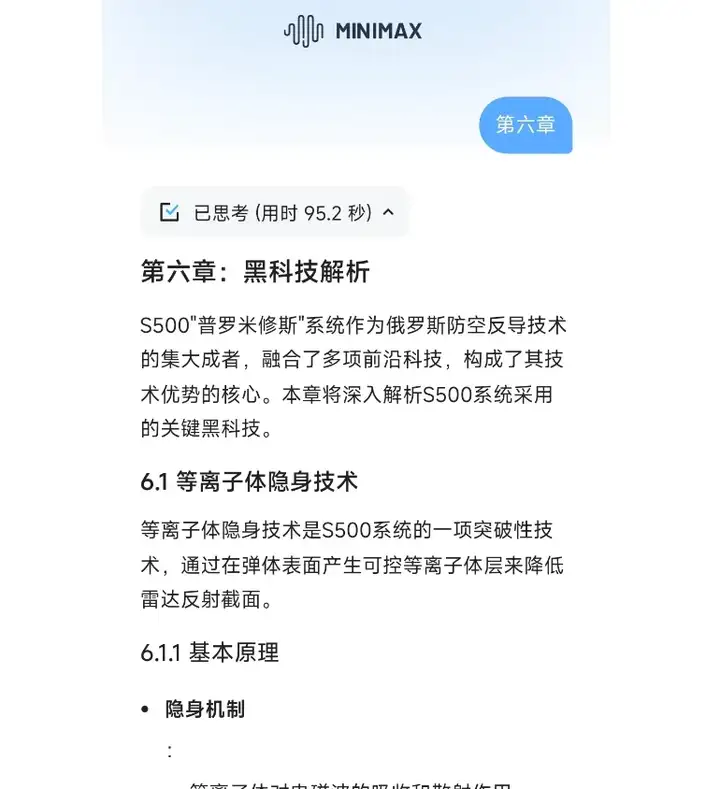
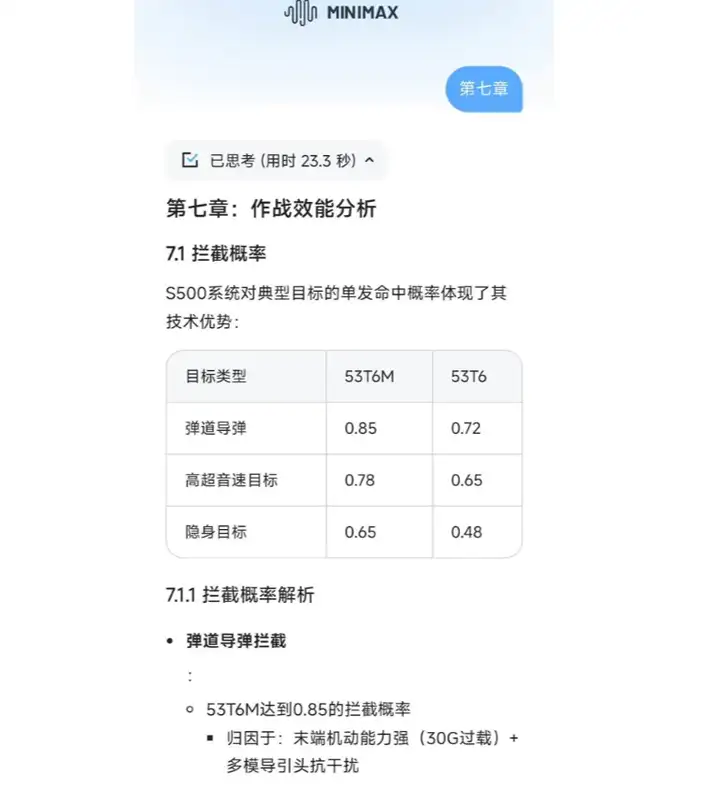

但是大模型还是没有办法一次性输出太多内容
所以第一次只是给了内容大纲
通过后续让MiniMax-M1生成了8次,最终得到了自己想要的内容,关键是内容非常连贯,得益于MiniMax-M1的超长上下文记忆能力。
MiniMax-M1非常适合用来生成论文,或者长篇小说等。
毕竟这些领域都是需要模型记住的上下文越多越好,这样生成的内容越来越多时才不至于跟开头脱节。
还可以用于小说续写:
我在3月份这篇文章里面就用MiniMax当时开源的MiniMax-Text-01模型(同样是具有超长上下文理解能力)进行了小说续写
MiniMax-Text-01
袋鼠帝、kiki,公众号:袋鼠帝AI客栈AI视频新王诞生!中国开源模型如何颠覆RAG/Agent?【含喂饭级使用教程】
续写的小说内容真有那味,感觉就是作者本人写的,完全没有违和感,故事情节也很合理。
续写辰东在24年9月份新上线的小说--《夜无疆》,目前还在持续更新中

插播一下:群友对MiniMax-M1的评价是真滴高呀
大伙应该都知道,打造AI知识库的第一步就是要做数据预处理,在之前的知识库相关文章中我也讲过很多次了。
然后我通常都是用我自己公众号的文章来作为我的知识库数据源
但是有一个小问题:公众号文章里面每篇的开头和结尾都会有一些重复的信息。
这块信息如果一起上传到知识库,那么问答的时候就会被频繁提取出来传给大模型,这样不仅浪费tokens还会一定程度上会干扰大模型的回答。
所以我进行了下面这样一个测试:
我把我去年写的kimi接入微信一、二、三丢过去,让MiniMax-M1合并文章的同时也"掐头去尾"。
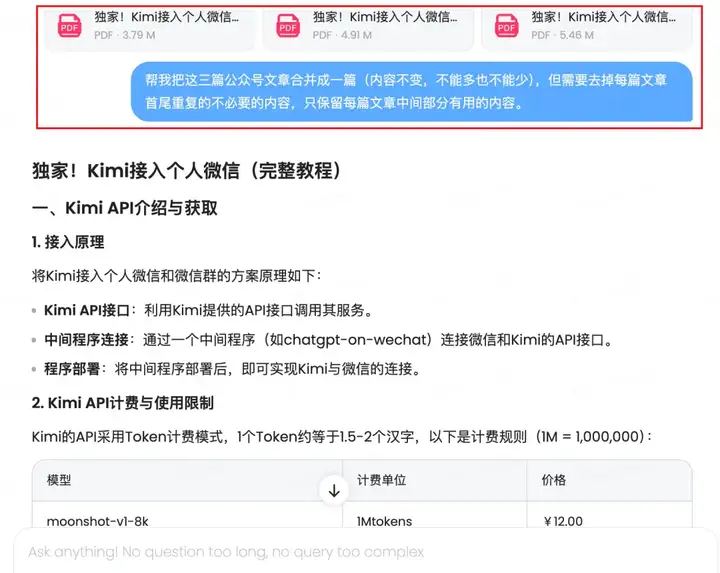
最终得到的效果很不错,它保留了关键信息,去除了冗余的其他内容。
除了这种处理场景外,还可以批量把数据源文件转英文,或者把英文文献转中文,MiniMax-M1能够最大程度的还原信息。
在实际的预处理场景中,肯定不止几个文件。
这时我们就可以使用MiniMax-M1的API接口来批量处理~
我把我去年和今年的部分文章(30篇)合并成了一个95M的PDF(一共267页)
丢给MiniMax-M1,让它帮我提取其中提到kimi和n8n的文章的标题
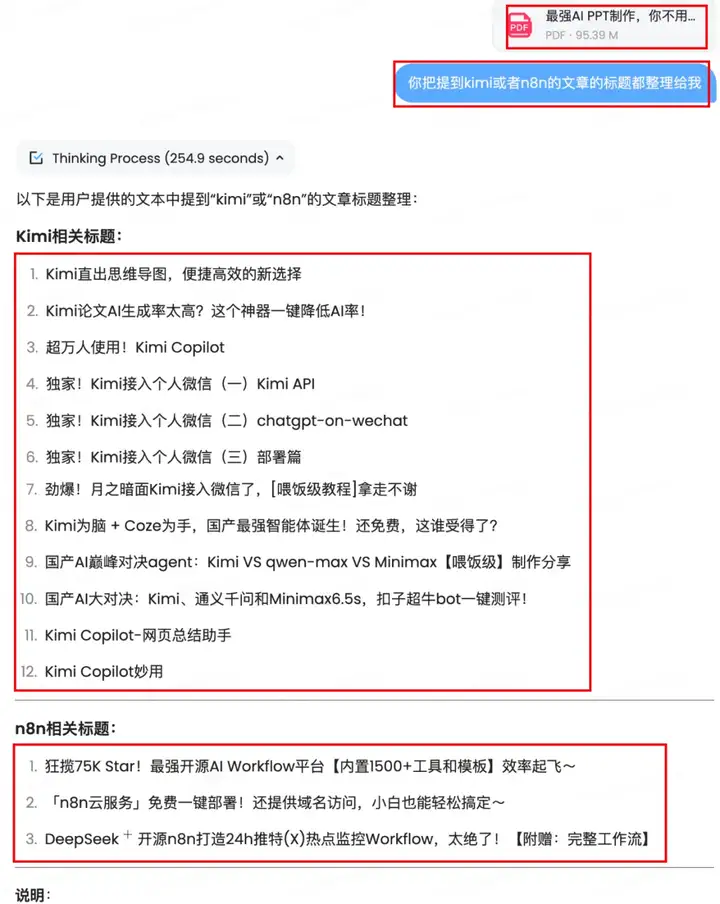
提取的完全正确,除了11和12那两个是多余的以外...
说实话,已经很强了,毕竟是一整个合并的PDF,能从267页PDF里面找出正确的内容,并识别标题已经不错了。
最近被知乎推送了不少关于长文本 VS RAG的问答

我的观点是RAG作为大模型的外脑肯定不会在短时间淘汰。
小孩才做选择,成年人全都要
长上下文的大模型+RAG才是强强联手,我称之为"大力出奇迹"。
因为MiniMax-M1能理解的上下文非常大(100万tokens)
所以在RAG的索引流程-分块(chunk)可以直接把语义连贯的内容分到一个chunk(比如一整篇文章一个chunk),不用担心chunk太大。
而且在设置最低相关度的时候也可以把score值调低,这样即便在回答流程中检索出大量无关内容,也可以依靠模型的超长上下文理解能力提取出准确答案。
这个方案可以减少在RAG上的调优工作,更依靠模型本身的长上下文理解能力,也能显著提高知识库问答效果。
而且MiniMax-M1的API是白菜价,不用担心会烧钱,随便用~
3月份分享了一篇用MiniMax-01拯救Dify知识库的文章,里面有详细的落地步骤(换成MiniMax-M1也是一样),接入AI知识库的朋友可以看看。
长上下文结合RAG拯救知识库问答效果
袋鼠帝,公众号:袋鼠帝AI客栈dify v1.1.0接入这个开源LLM,知识库效果直接起飞,真可以封神了!【喂饭级教程】
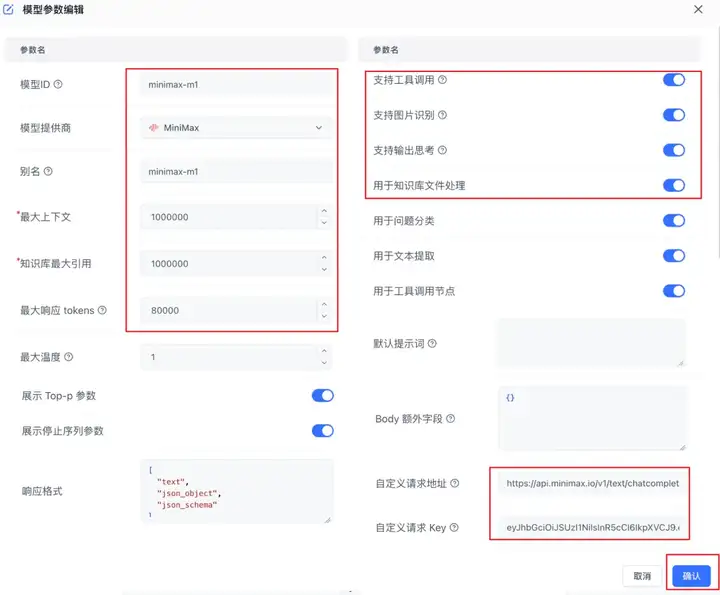
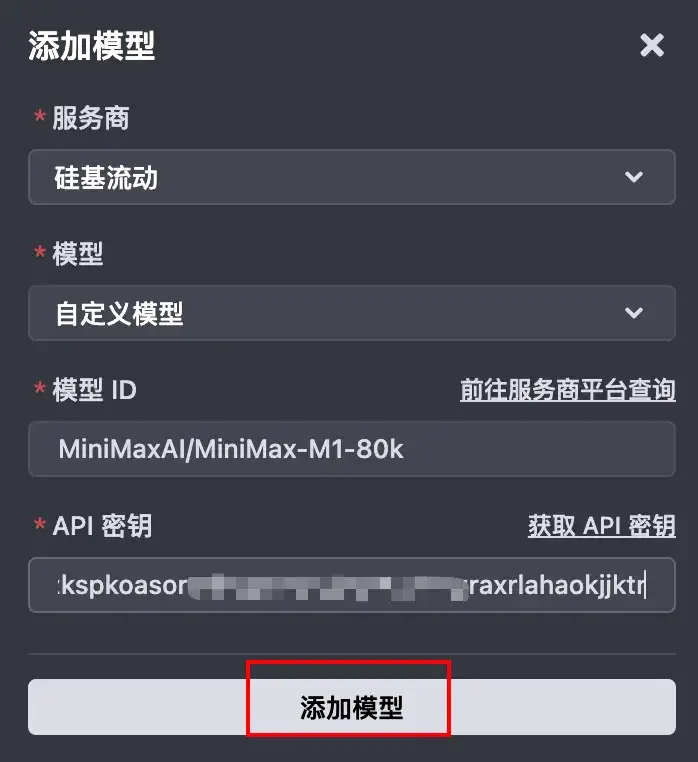
如果是使用fastgpt搭建的知识库,也可以参考下面的配置接入MiniMax-M1模型。
注意:API地址要填写完整
这么长的上下文理解能力,不用来解读开源项目简直太浪费了
在Trae里面配置上MiniMax-M1模型
Trae居然还没支持minimax渠道,硅基流动倒是很快,就已经支持了昨天才开源的minimax-m1模型
以开源项目fastgpt为例
fastgpt有一些商业版才能用的功能,比如把bot一键发布到公众号,飞书机器人。
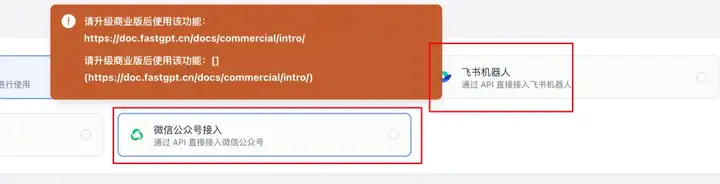
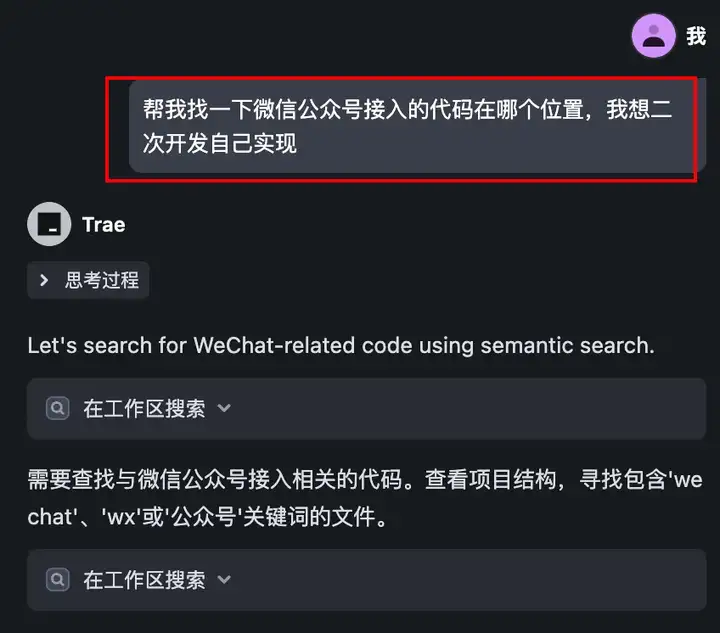
如果现在想基于fastgpt开源代码来自己二次开发实现,首先肯定得找对位置。
让MiniMax-M1查找微信公众号接入的代码位置,简直就是信手拈来。
找到实现位置之后,我们就可以进一步让AI辅助二次开发了
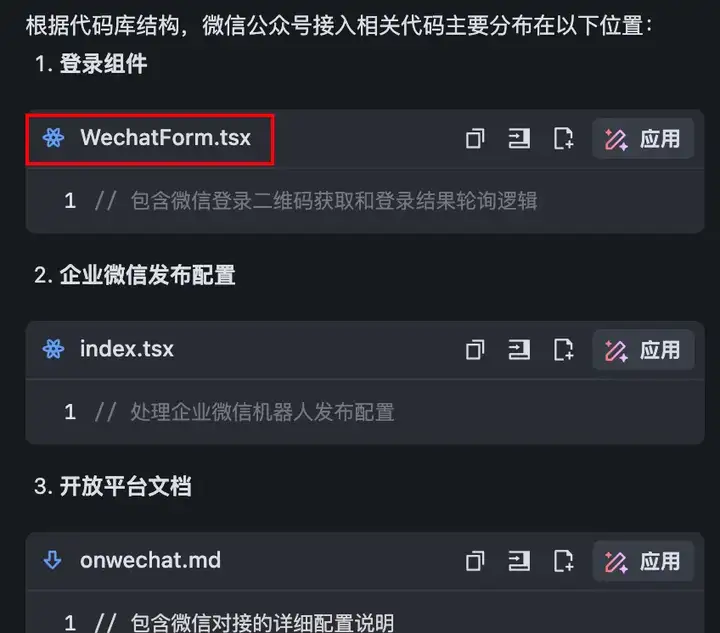
再上点强度(如下图)
让MiniMax-M1总结:
在FastGPT整个项目代码及文件中,关键词"minimax"出现在哪些具体文件里,以及出现的总次数。

左边是用Trae全局搜索minimax关键词的标准答案(4个文件,出现12次)
右边是MiniMax-M1给出的结果:4个文件,出现11次...
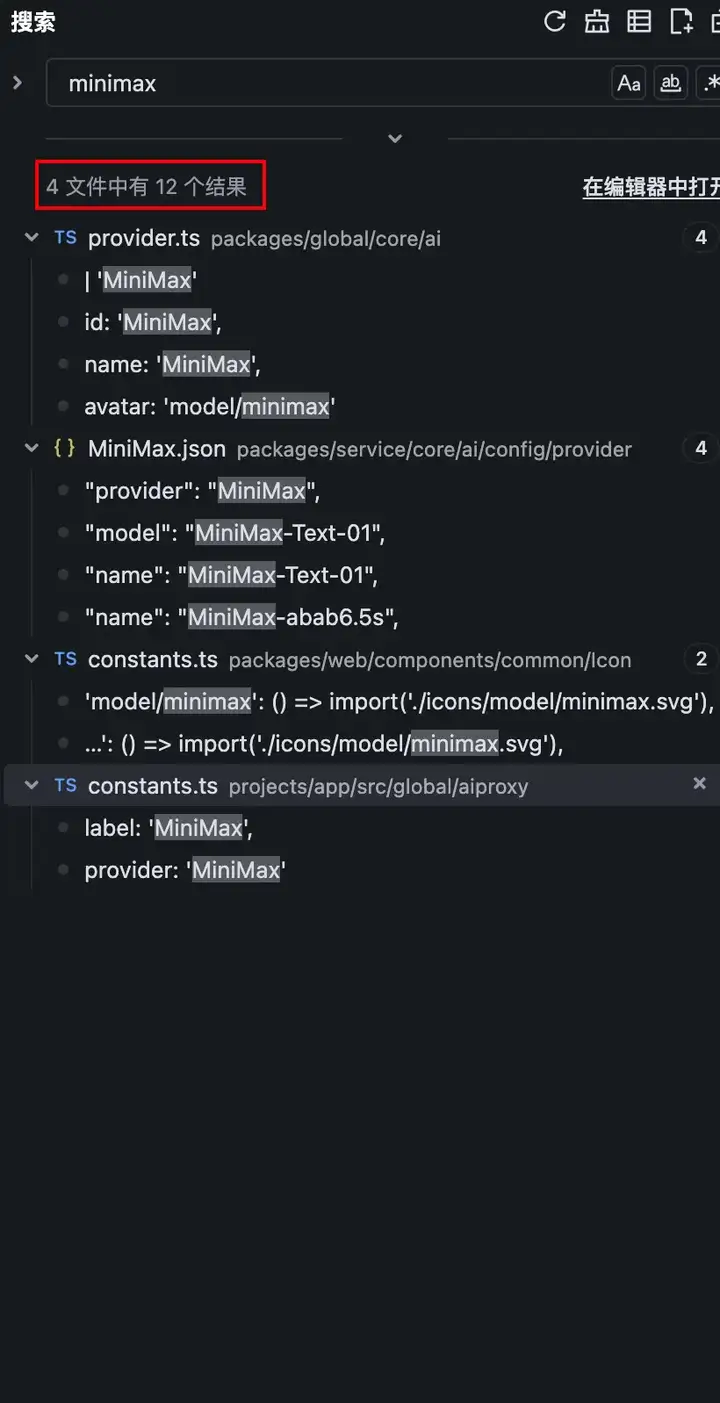
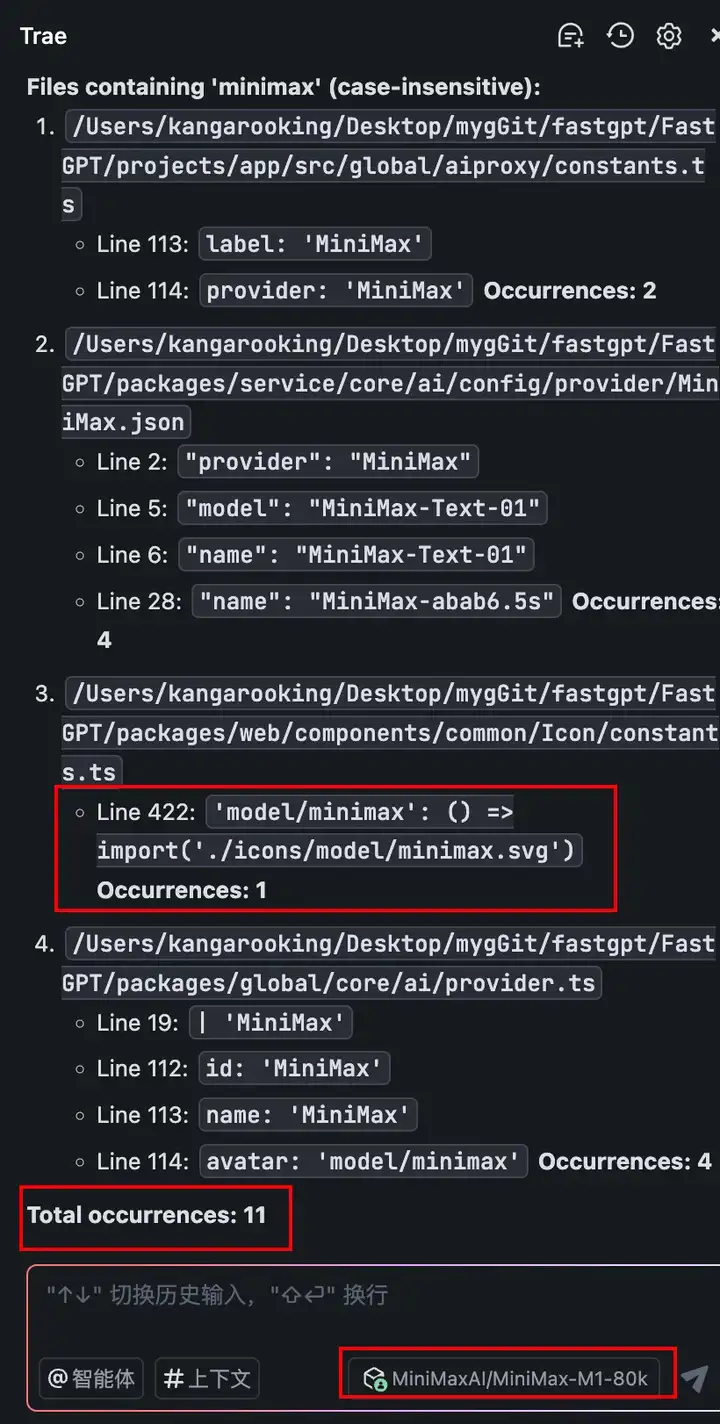
稍微有点可惜,本来第三条它列出的那一行代码中就出现了两个minimax关键词,但是可能是在一行,它就只统计了一次,所以最后的答案就少统计了1次。
好了,以上就是我整理的MiniMax-M1的五个经典使用场景,希望对大家有帮助~
MiniMax-M1 Github地址:
https://github.com/MiniMax-AI/MiniMax-M1
HuggingFace地址:
https://huggingface.co/MiniMaxAI/MiniMax-M1-80k
体验下来,我感觉MiniMax的基座模型真的是被严重低估了,属于被埋没的黑马型选手。
这种超长上下文理解能力在很多场景下都非常实用。
真的就像他们官网那句话
Ask anything! No question too long, no query too complex
有问题,尽管问,内容再长也不在话下
希望MiniMax在长上下文这块继续发扬光大,以支持更长的上下文和更强的"大海捞针"能力。
如果你的使用场景正好受限于模型的上下文长度,不妨试试MiniMax-M1
文章来自于“袋鼠帝AI客栈”,作者“袋鼠帝”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
