# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
扩散模型在视频合成任务中取得了显著成果,但其依赖迭代去噪过程,带来了巨大的计算开销。尽管一致性模型(Consistency Models)在加速扩散模型方面取得了重要进展,直接将其应用于视频扩散模型却常常导致时序一致性和外观细节的明显退化。
本文通过分析一致性模型的训练动态,发现蒸馏过程中存在一个关键的冲突性学习机制:在不同噪声水平的样本上,优化梯度和损失贡献存在显著差异。这种差异使得蒸馏得到的学生模型难以达到最优状态,最终导致时序一致性受损、画面细节下降。
为解决这一问题,本文提出了一种参数高效的双专家一致性模型(Dual-Expert Consistency Model, DCM):其中 Semantic Expert 负责学习语义布局和运动信息,Detail Expert 则专注于细节的合成。此外,引入了 Temporal Coherence Loss 以增强语义专家的运动一致性,并引入 GAN Loss 与 Feature Matching Loss 以提升细节专家的合成质量。
DCM 在显著减少采样步数的同时,仍能达到当前相当的视觉质量,验证了双专家机制在视频扩散模型蒸馏中的有效性。

扩散模型在图像和视频生成中表现出令人印象深刻的性能。然而,扩散模型迭代采样的性质和规模逐渐增长的去噪 transformer 网络,给推理过程带来了繁重的计算代价。
为了缓解这个问题,一致性蒸馏通过减少采样步数,降低推理时延。它通过训练一个 student 模型学习直接映射采样轨迹上任意一个点到相同的解点,以满足 self-consistency 性质,进而提升少步推理结果的视觉质量。尽管支持少步采样,它在复杂的视频合成中往往难以保证视觉质量,容易出现布局错乱、运动不自然以及细节降质等问题。
通过对推理过程的分析可以发现,相邻时间步的去噪结果在推理早期差异显著,而在后期变得更加缓慢和平滑。这是因为推理早期主要关注于合成语义,布局和运动这些相对低频的特征成分,而在推理后期更加强调细节的合成。
这表明,在蒸馏过程中,student 模型在高噪声和低噪声训练样本中学习不同的模式,可能表现出不同的 learning dynamics。通过可视化蒸馏过程中一致性损失和损失梯度在高噪声样本和低噪声样本上的趋势变化,可以看到,它们表现出显著的差异,这表明联合蒸馏一个 student 模型可能会引入优化的干扰,从而导致次优的视觉质量。
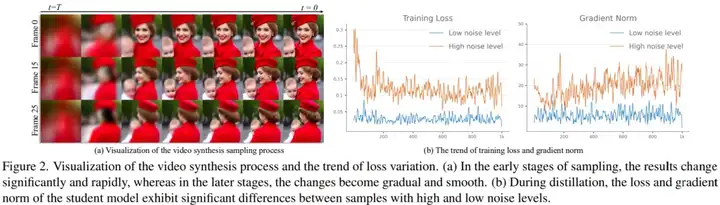
为了解耦蒸馏过程,本文首先根据推理过程中的去噪结果的变化趋势将 ODE 解轨迹分为两段:语义合成阶段和细节合成阶段。然后分别为两个阶段训练两个 Expert Denoiser,SemE 和 DetE,以满足对应阶段的 self-consistency 性质。在推理时,基于样本的噪声水平动态地选择 SemE 或者 DetE 作为去噪网络。这种方式虽然获得了更好的视觉质量,但是也带来了双倍的参数代价,更大的内存消耗。
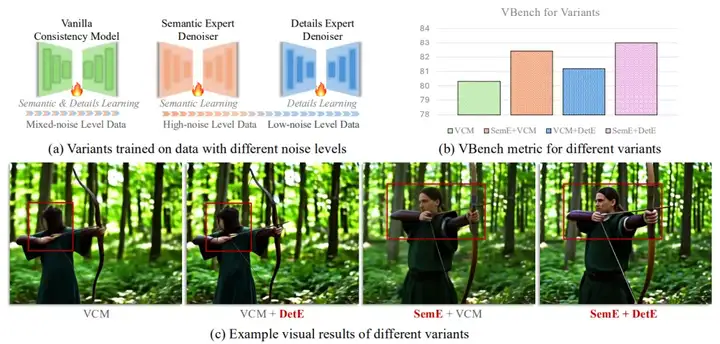
为了提升参数效率,进一步分析了两个 Expert Denoisers 之间的参数差异,发现它们主要存在于 embedding layers 和 attention layers 中。基于此,本文设计了一种参数高效的 Dual-Expert 一致性模型,具体来说,首先在语义合成轨迹上训练语义合成专家 SemE,然后冻结它,并引入一套新的 embedding layers 和一个 LoRA。在细节合成轨迹上微调和更新这些新添加的参数。通过这种方式,解耦了两个 Expert Denoisers 的优化过程,并且仅仅引入了少量的额外参数,实现了相当的视觉质量。
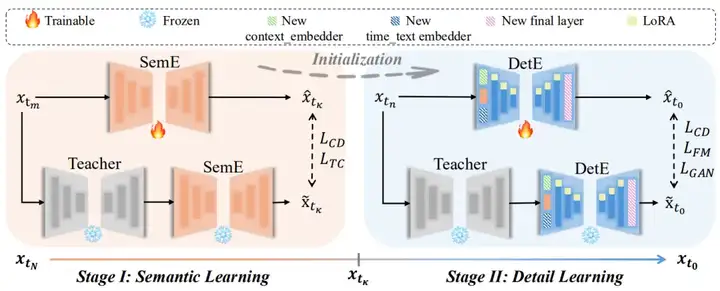
此外,考虑到两个 Expert Denoisers 不同的 training dynamics,在一致性损失的基础上,为语义合成专家 SemE 额外引入了 Temporal Coherence 损失,以捕获帧间运动变化。为了增强 DetE 的细节合成质量,为 DetE 引入了生成对抗损失和 Feature Matching 损失。
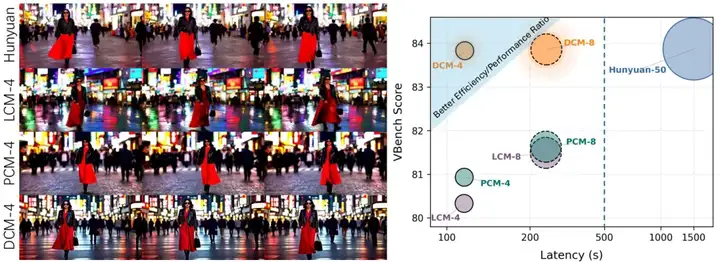
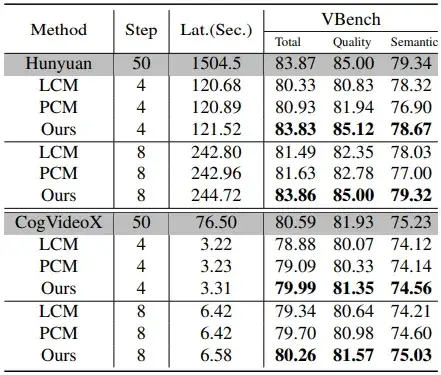
为了验证 DCM 的有效性,本文在 HunyuanVideo,CogVideoX 和 WAN2.1 上进行了实验。如下表所示,在 4 步生成下,DCM 在实现了超过 10x 加速 (1504.5→121.52) 的同时,获得了与原始 50 步采样相当的 Vbench 得分(83.83%→83.86%),显著超过 LCM 和 PCM 的表现。
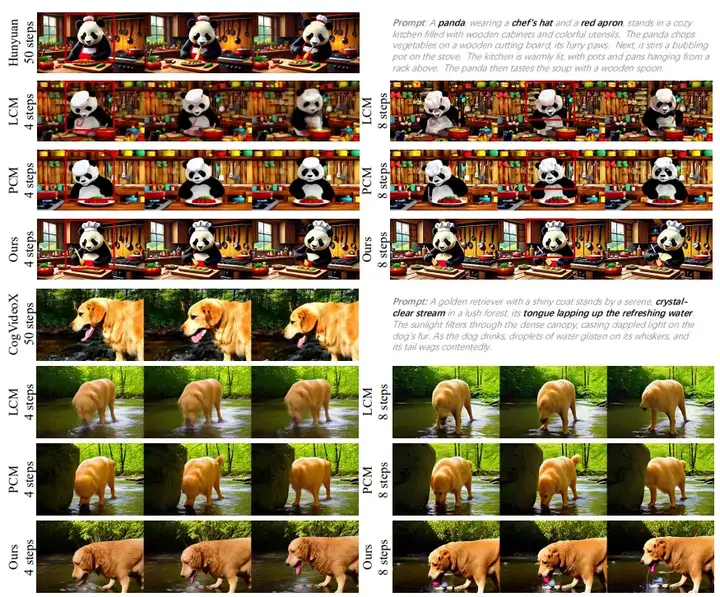
下图展示了 DCM 与原始模型、LCM 和 PCM 生成视频的对比。可以看到,在减少推理步数的同时,DCM 依然能够保持较高的语义质量和细节质量。
本文指出,当前视频合成中的一致性蒸馏存在一个关键的优化冲突:在不同噪声水平的训练样本上,优化梯度和损失贡献存在显著差异。将整个 ODE 轨迹压缩到一个单一的学生模型中,会导致这些因素难以平衡,从而造成生成结果的降质。为了解决这一问题,本文提出了一种参数高效的双专家蒸馏框架(Dual-Expert Distillation Framework),通过将语义学习与细节精修解耦,实现更合理的建模。此外,引入了 Temporal Coherence Loss 来增强语义专家的运动一致性,并为细节专家引入 GAN Loss 和 Feature Matching Loss,以提升细节合成质量。DCM 在显著减少采样步数的同时,仍能达到当前相当的视觉效果,展现了专家分工机制在视频扩散模型蒸馏中的有效性。
文章来自于“机器之心”,作者“机器之心”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
