# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着大型模型需要处理的序列长度不断增加,注意力运算(Attention)的时间开销逐渐成为主要开销。此前,清华大学陈键飞团队提出的即插即用的 SageAttention 和 SageAttention2 已经被业界及社区广泛的使用于各种开源及商业的大模型中,比如 Vidu,CogvideoX,Mochi,Wan,HunyuanVideo,Flux,Llama3,Qwen 等。
近日,清华大学陈键飞团队进一步提出了针对 BlackWell 架构的首个全 FP4 量化的即插即用注意力算子(SageAttention3)。实现了 5 倍相比于 FlashAttention 的即插即用的推理加速(此前的 SageAttention V1/V2/V2++ 分别达到了 2.1,3,3.9 倍的加速效果),比如在 RTX 5090 上,SageAttention3 达到了 1040 TOPS 的速度,甚至是比 RTX 5090 昂贵十几倍的 H100 上使用 Hopper 独有的 FlashAttention3 还要快 1.65 倍!SageAttention3 在多种视频和图像生成等大模型上(包括 HunyuanVideo,CogVideoX,Mochi 和各类图像生成模型)均保持了端到端的精度表现。同时还首次提出可训练的 8 比特注意力(SageBwd)用于大模型的训练加速(注:FlashAttention3 的 FP8 版本也只支持前向传播),在各项微调任务中均保持了与全精度注意力相同的结果。

效果预览

SageAttention3 实现了高效的 Attention 算子,可以实现即插即用的 5 倍于 FlashAttention 的推理加速。即输入任意 Q, K, V 矩阵,可以快速返回 Attention Output (O),真正做到了两行代码加速任意模型推理。(注:按照官方仓库中的开源计划,SageAttention2++ 的代码将于6月20日左右开源,SageAttention3 的代码将于7月15日左右开源。)
效果上,以 HunyuanVideo 为例,在 RTX5090 上 SageAttention3 可以 3 倍加速端到端的生成,且视频质量几乎无损:

视频 1(使用 FlashAttention2,490s)

视频 2(使用 SageAttention3,164s)
(注:FlashAttention2 已经是在 RTX5090 上最优的 FlashAttention 实现。)
接下来,将从前言,挑战,方法,以及实验效果四个方面介绍 SageAttention3。
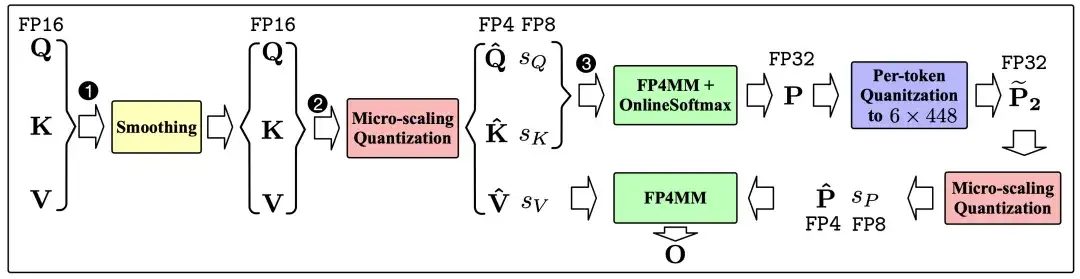
SageAttention3 总体流程图
前言
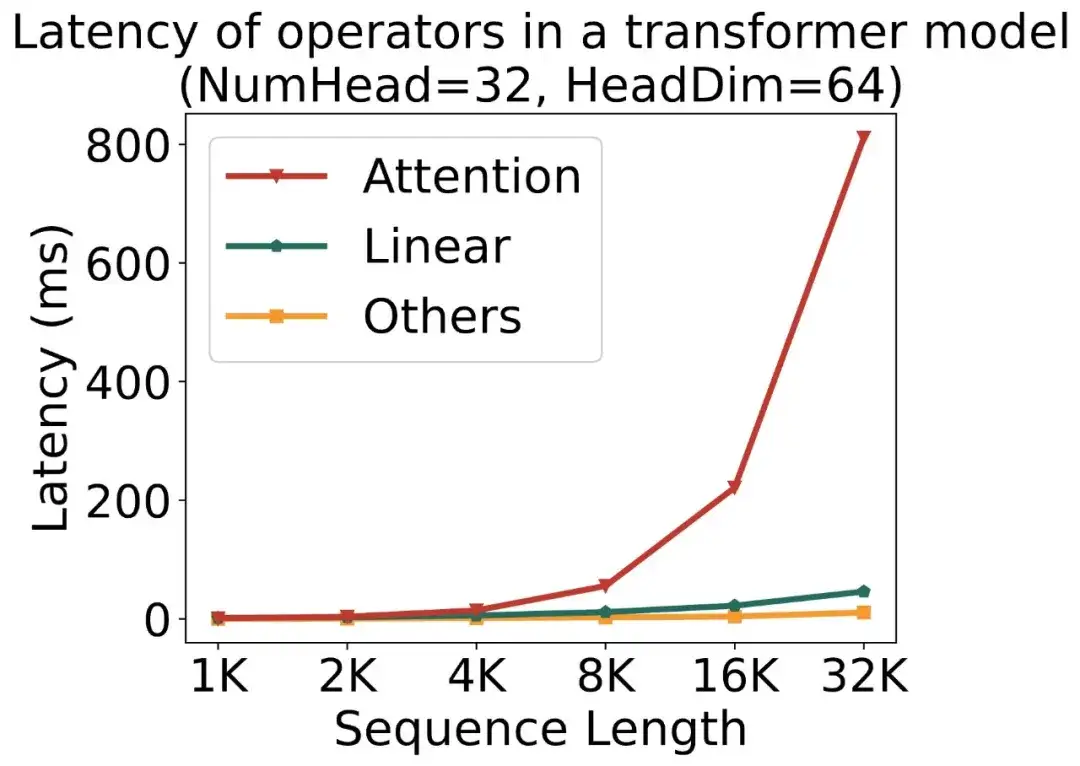
随着大模型需要处理的序列长度越来越长,Attention 的速度优化变得越来越重要。下图展示了一个标准的 Transformer 模型中各运算的时间占比随序列长度的变化:
为了方便指代注意力运算中的矩阵,我们先回顾一下注意力的计算公式:
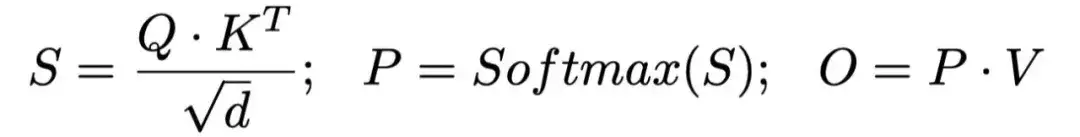
研究动机:(1)Blackwell 架构有着速度极快的 FP4 Tensor Core,以 RTX5090 为例,其速度是 FP16 Tensor Core 的 8 倍。(2)训练阶段的注意力运算开销也同样重要,在此之前并没有工作尝试过低比特注意力加速模型训练,包括 FlashAttention3 的 FP8 版本也只有 Forward 过程。我们还希望同时量化注意力的前向 + 反向过程来加速训练。
FP4 注意力量化有什么问题?
(1)FP4 数值类型仅有 15 个有效数值,这使得以 Tensor(Per-tensor)或以 Token(Per-token)粒度的量化都难以有效保证量化的准确度。
(2)P 矩阵的值分布在 [0, 1] 之间,直接的 FP4 量化会使量化缩放因子被限制在一个狭窄的范围内。然而,硬件要求这些量化因子必须采用 FP8 数据类型表示。此时,将缩放因子转为 FP8 时会导致显著的精度损失。
8-Bit 注意力用于训练有什么问题?
(1)P 矩阵的梯度对量化误差过于敏感,并且在反向过程中还会沿着序列长度对 Q 和 K 的梯度造成误差累积。
技术方案
为了解决上述的挑战,研究团队提出了对应的解决办法。
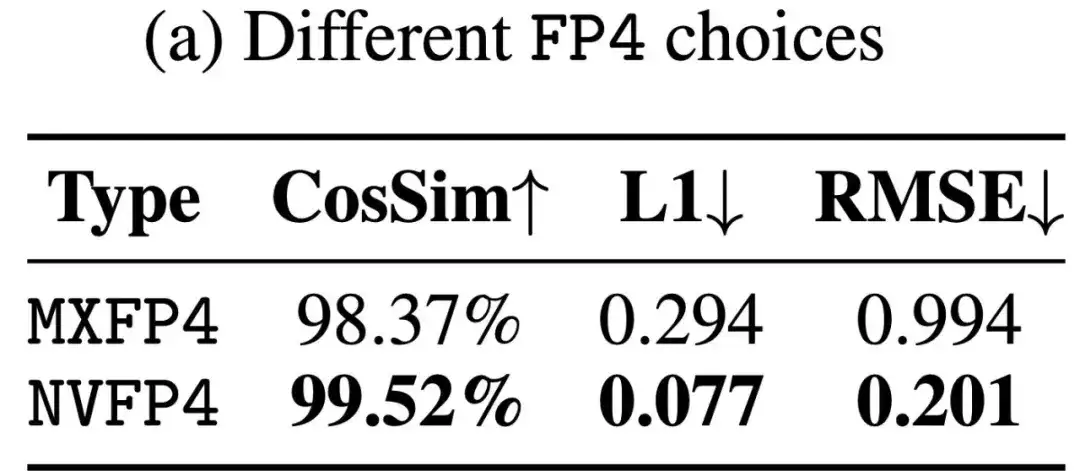
(1)为了提高 FP4 的量化精度。研究团队采用了 Microscaling FP4 量化,这是 BlackWell 硬件层面支持的一种量化方式。即可以采用 或 的量化粒度进行矩阵量化,NIVIDA 在硬件层面自动支持了反量化过程。此外,Microscaling FP4 有两种数据表示的形式,一种是 MXFP4, 另外一种是 NVFP4。两种格式都采用了 E2M1 的 FP4 数据类型。不同的是,NVFP4 的量化的块大小为,缩放因子的数据类型为 E4M3。MXFP4 的量化的块大小为,缩放因子的数据格式为 E8M0。研究团队采用了 NVFP4 数据格式,因为其量化准确率远高于 MXFP4:
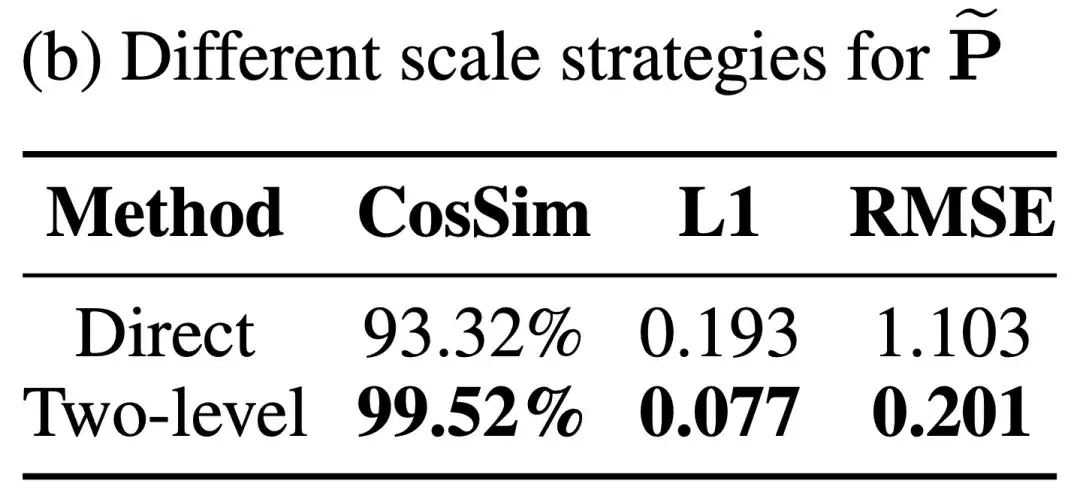
(2)针对 P 的缩放因子范围狭窄的问题,研究团队提出了两阶段量化(Two-level Quantization)的办法。FlashAttention 中的 P 矩阵的值在 [0, 1] 的范围内,导致 P 的缩放因子的范围也只在 0~0.167 之间。把缩放因子直接转换为 FP8 格式会带来极大的精度损失。

于是研究团队决定先把 P 通过 Per-token 量化到 [0, ] 的范围内,再进行 FP4 的量化:
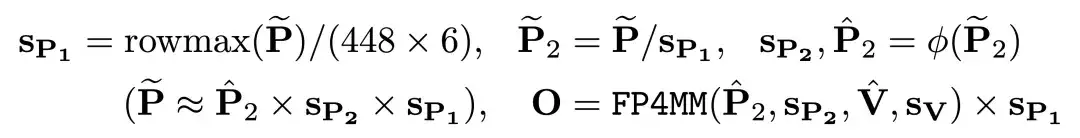
下表展示了 Two-Level Scaling 对精度的提升:
下图展示了 SageAttention3 的算法流程:

(3)在 8-Bit 训练 Attention 当中,研究团队对 Q,K,V 采用了 Per-block INT8 量化,对 P 巧妙地采用了无量化 Overhead 的 Per-token 量化。前向过程的算法如下:

在反向传播的过程中总共涉及到 5 个矩阵乘法:
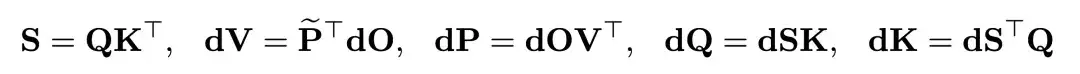
研究团队发现是否量化 dOVT 对精度有着较大的影响:
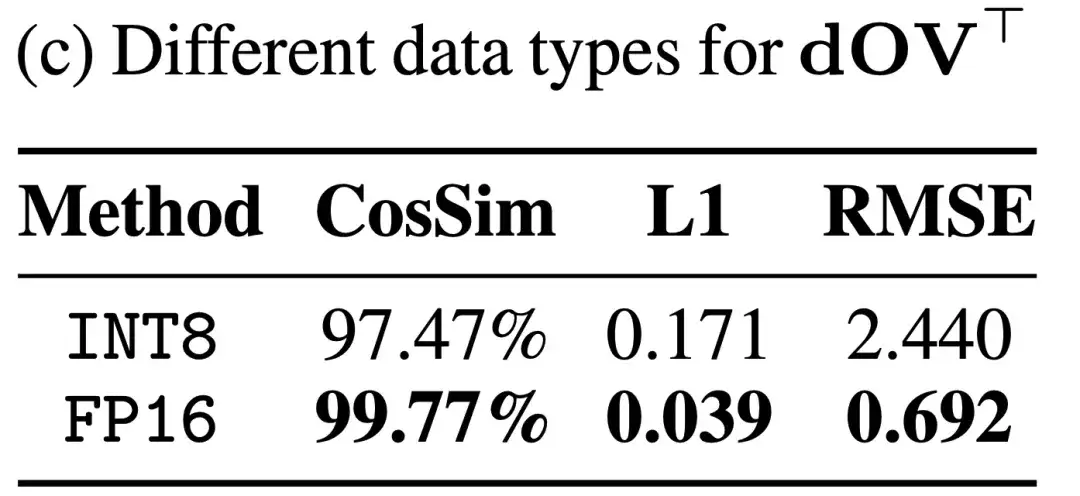
于是研究团队将 dOVT 保留为 FP16 精度,而对其它四个矩阵乘法进行了量化。以下是反向传播的算法:

实验效果
SageAttention3 实现了 GPU 底层的 CUDA Kernel,在算子速度以及各个模型端到端准确度上都有十分不错的表现。
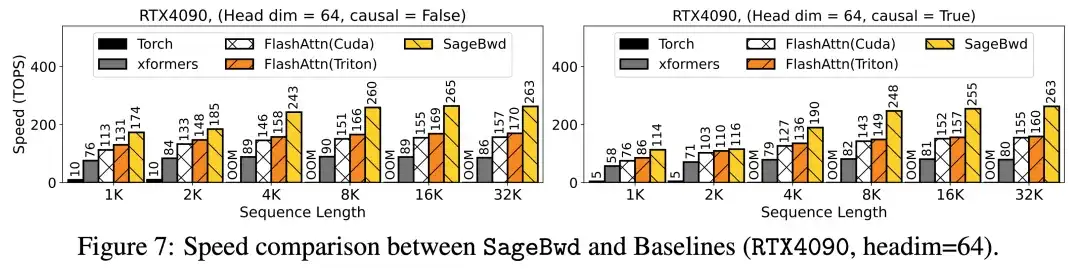
具体来说,算子速度相比于 FlashAttention2(5090 上最快的 FlashAttention) 和 xformers 有大约 5 倍以及 10 倍的加速:
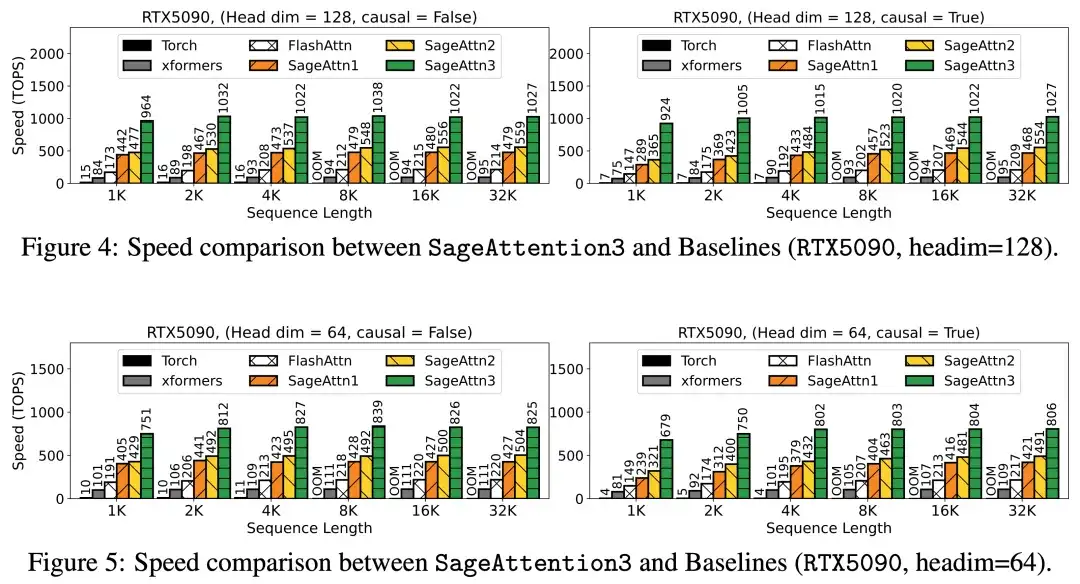
各模型在真实场景的端到端精度表现中,在视频、图像生成等大模型上均保持了端到端的精度表现:

下图是在 HunyuanVideo 当中的可视化实例:

下图是在 Flux 上的可视化实例:

下图是在 Cogvideo 中的可视化实例:

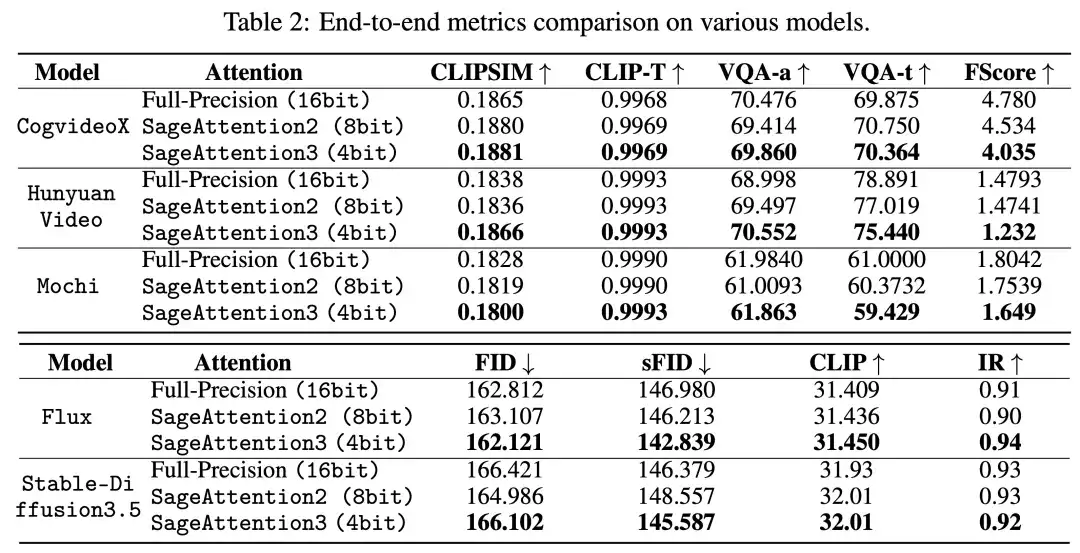
下表展示了各个视频、图像生成模型中 SageAttention3 的端到端精度表现:
端到端的速度表现上,SageAttention3 的实现均可以有效地对长序列的模型进行加速,比如可以端到端 3 倍加速 HunyuanVideo:

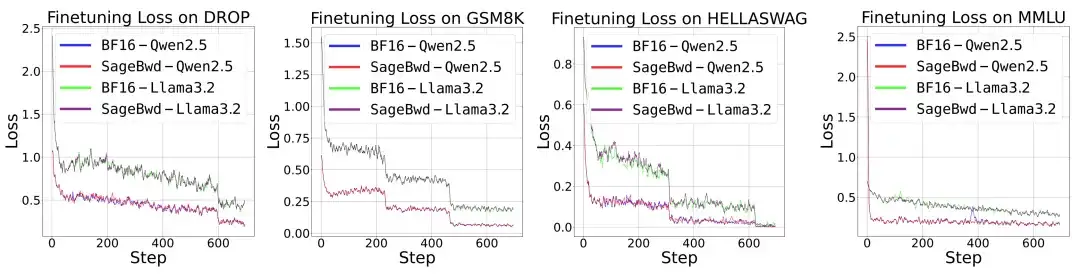
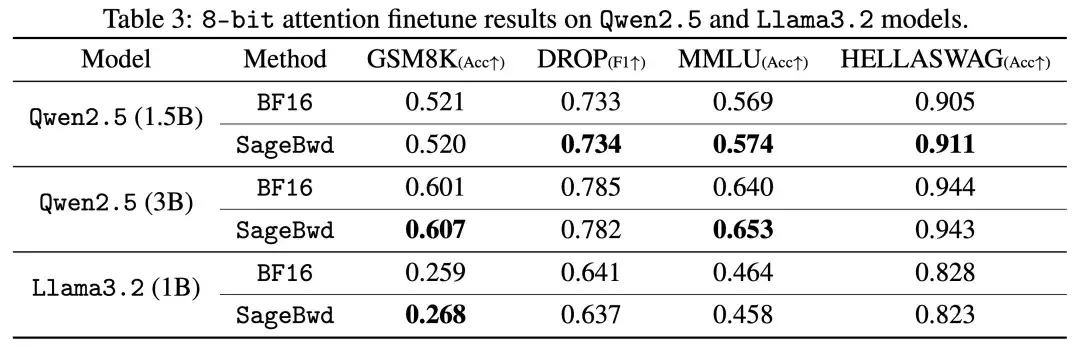
8-Bit 训练 Attention 在 Base Model 微调到 Instruct Model 的任务上展现出与 BF16 的注意力完全一致的精度表现,下表是在多个不同的任务以及模型上微调的结果:
并且在训练速度上也能起到较好的加速效果:

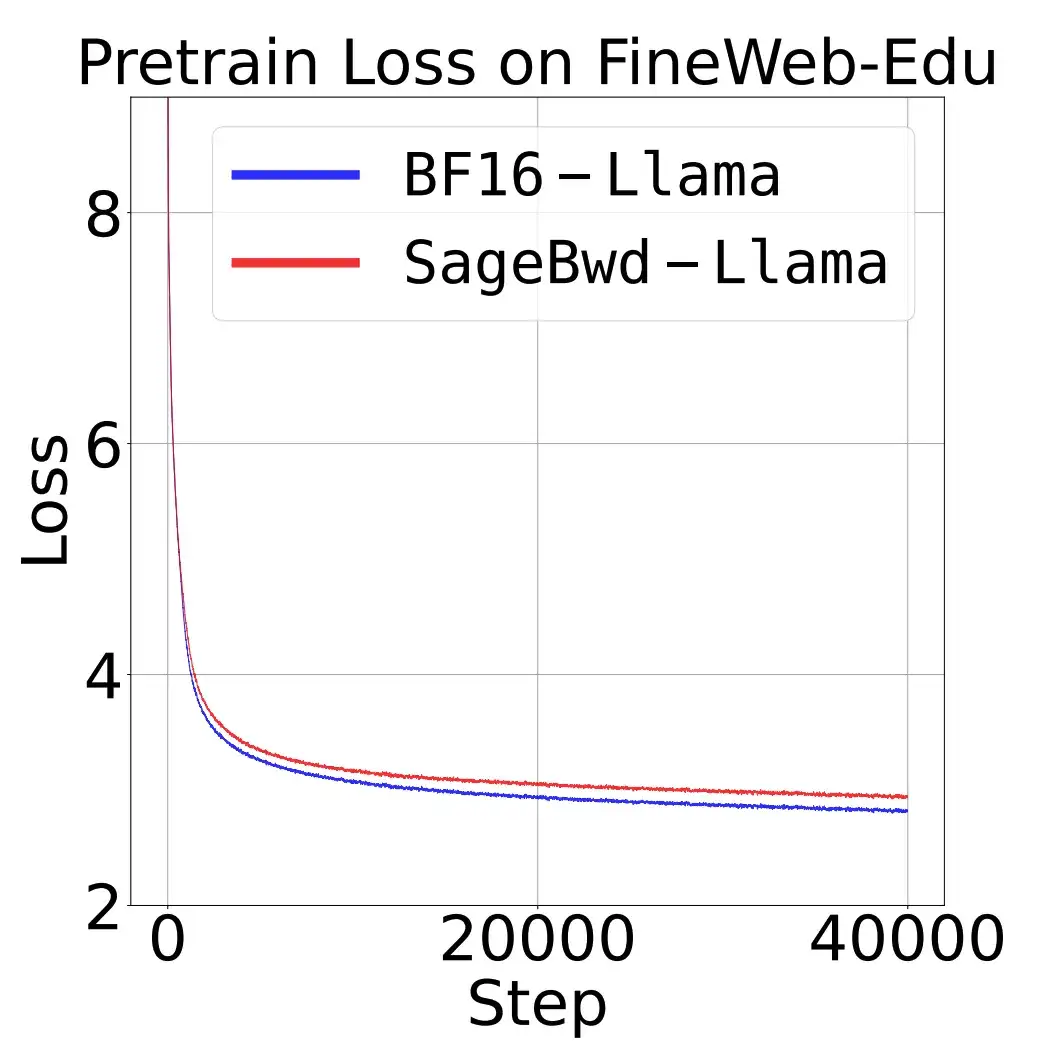
研究团队还发现,目前的 8 比特用于训练的 Attention 虽然在微调任务上完全无损,但是在预训练任务上与全精度的 Attention 在 Loss 上还有一定差距,需要未来进一步的研究:
文章来自公众号“机器之心 ”



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【部分开源免费】FLUX是由Black Forest Labs开发的一个文生图和图生图的AI绘图项目,该团队为前SD成员构成。该项目是目前效果最好的文生图开源项目,效果堪比midjourney。
项目地址:https://github.com/black-forest-labs/flux
在线使用:https://fluximg.com/zh
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
