# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在 AI 领域,英伟达开发的 CUDA 是驱动大语言模型(LLM)训练和推理的核心计算引擎。
不过,CUDA 驱动的 LLM 推理面临着手动优化成本高、端到端延迟高等不足,需要进一步优化或者寻找更高效的替代方案。
近日,CMU 助理教授贾志豪(Zhihao Jia)团队创新玩法,推出了一个名为「Mirage Persistent Kernel(MPK)」的编译器,可以自动将 LLM 转化为优化的巨型内核(megakernel),从而将 LLM 推理延迟降低 1.2 到 6.7 倍。
MPK 将 LLM 推理延迟推近硬件极限。在单个 A100-40GB GPU 上,MPK 将 Qwen3-8B 每个 token 的延迟从 14.5 毫秒 (vLLM/SGLang) 降低到 12.5 毫秒,逼近基于内存带宽计算得出的 10 毫秒理论下限。

MPK 的易用性很强,你只需要几十行 Python 代码就能将 LLM 编译成一个高性能巨型内核,实现快速推理,整个过程无需 CUDA 编程。

评论区对 MPK 的看法也很正向,并提出了一些未来的延展方向。
降低 LLM 推理延迟最有效的方法之一,是将所有计算和通信融合进一个单一的巨型内核,也称为持续内核。
在这种设计中,系统仅启动一个 GPU 内核来执行整个模型 —— 从逐层计算到 GPU 间通信 —— 整个过程无需中断。这种方法提供了以下几个关键的性能优势:
尽管有这些优势,将 LLM 编译成巨型内核仍然极具挑战性。
现有的高级 ML 框架 —— 如 PyTorch、Triton 和 TVM,它们本身并不支持端到端巨型内核生成。此外,现代 LLM 系统由各种不同的专用内核库构建而成:用于通信的 NCCL 或 NVSHMEM,用于高效注意力计算的 FlashInfer 或 FlashAttention,以及用于自定义计算的 CUDA 或 Triton。
这种碎片化使得将整个推理 pipeline 整合进一个单一的、统一的内核变得非常困难。
那么能否通过编译自动化这个过程呢?受到这个问题的启发,来自 CMU、华盛顿大学、加州大学伯克利分校、英伟达和清华大学的团队开发出了 MPK—— 一个编译器和运行时系统,它能自动将多 GPU 的 LLM 推理转换为高性能的巨型内核。MPK 释放了端到端 GPU 融合的效能优势,同时只需要开发者付出极小的手动努力。
MPK 的一个关键优势在于:通过消除内核启动开销,并最大程度地重叠跨层的计算、数据加载和 GPU 间通信,实现了极低的 LLM 推理延迟。
下图 1 展示了 MPK 与现有 LLM 推理系统在单 GPU 和多 GPU 配置下的性能对比(具体可见上文)。
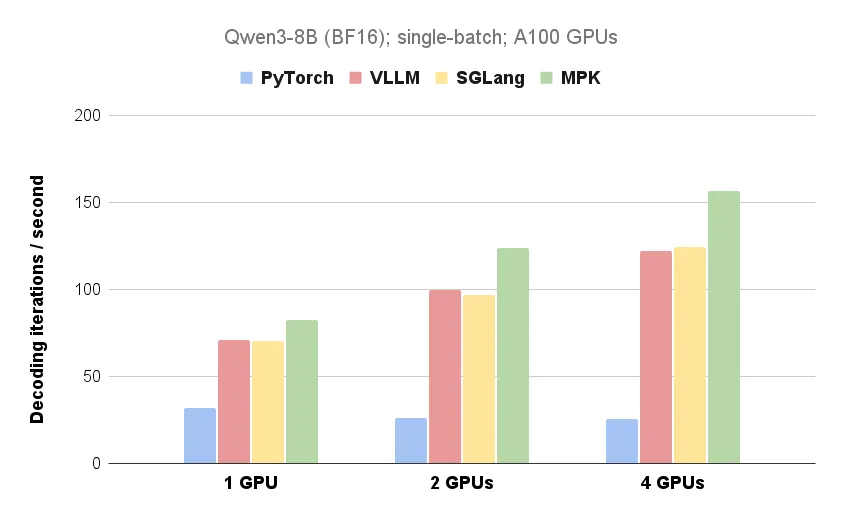
除了单 GPU 优化,MPK 还将计算与 GPU 间通信融合进一个单一的巨型内核。 这种设计使得 MPK 能够最大程度地重叠计算与通信。因此,MPK 相对于当前系统的性能提升随着 GPU 数量的增加而增大,使其在多 GPU 部署场景下尤为高效。
MPK 的工作原理包括以下两大部分
编译器 —— 将 LLM 转化为细粒度任务图
LLM 的计算过程通常表示为计算图,其中每个节点对应一个计算算子(如矩阵乘法、注意力机制)或集合通信原语(如 all-reduce),边表示算子间的数据依赖关系。现有系统通常为每个算子启动独立的 GPU 内核。
然而,这种「单算子单内核」的执行模型难以实现 pipeline 优化,因为依赖关系是在整个内核的粗粒度层面强制执行的,而非实际数据单元层面。
典型案例如矩阵乘法(matmul)后接 all-reduce 操作:现有系统中,all-reduce 内核必须等待整个 matmul 内核完成。而实际上,all-reduce 的每个数据分块仅依赖 matmul 输出的局部结果。这种逻辑依赖与实际依赖的错配,严重限制了计算与通信的重叠潜力。
下图 2 展示了 MPK 编译器将 PyTorch 定义的 LLM 计算图转化为优化细粒度任务图,最大化暴露并行性。右侧展示次优方案 —— 其引入不必要的数据依赖与全局屏障,导致跨层流水线优化机会受限。
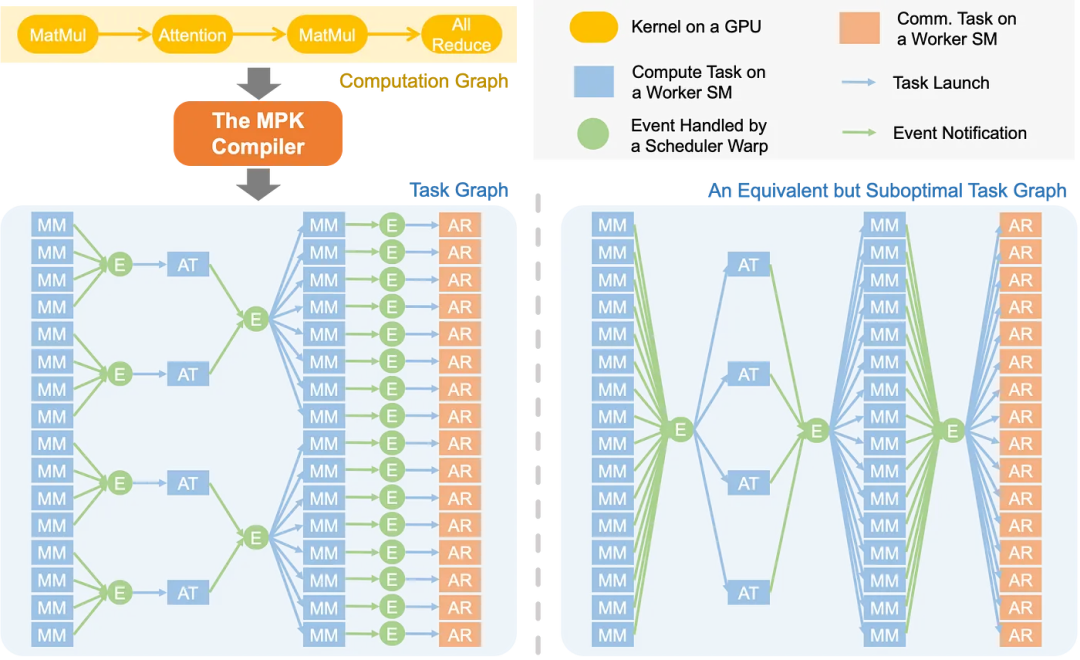
为了解决此问题,MPK 引入的编译器可将 LLM 计算图自动转化为细粒度任务图。该任务图在子内核级别显式捕获依赖关系,实现更激进的跨层流水线优化。
具体来讲,在 MPK 任务图中(如图 2 所示):
任务图使 MPK 能够发掘计算图中无法实现的 pipeline 优化机会。例如,MPK 可以构建优化任务图 —— 其中每个 all-reduce 任务仅依赖于生成其输入的对应 matmul 任务,从而实现分块执行与计算通信重叠。
除生成优化任务图外,MPK 还通过 Mirage 内核超优化器自动为每个任务生成高性能 CUDA 实现,确保任务在 GPU 流式多处理器(SM)上高效执行。
Part 2:运行时 —— 在巨型内核中执行任务图
MPK 包含内置 GPU 运行时系统,可在单个 GPU 巨型内核内完整执行任务图。这使得系统能在推理过程中无需额外内核启动的情况下,实现任务执行与调度的细粒度控制。
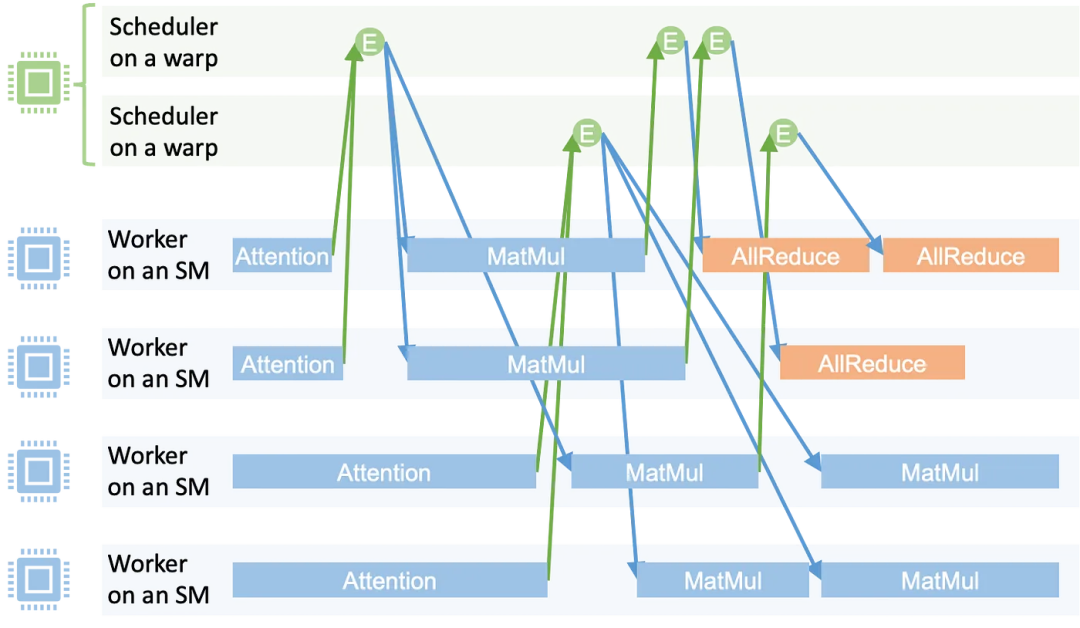
为了实现此机制,MPK 在启动时将 GPU 上所有流式多处理器(SM)静态分区为两种角色:即工作单元(Worker)和调度单元(Scheduler)。
工作 SM 与调度 SM 的数量在内核启动时固定配置,且总和等于物理 SM 总数,从而彻底避免动态上下文切换开销。
工作单元
每个工作单元独占一个流式多处理器(SM),并维护专属任务队列。其执行遵循以下高效简洁的循环流程:
该机制既保障了工作单元的持续满载运行,又实现了跨层和跨操作的异步任务执行。
调度单元
调度决策由 MPK 的分布式调度单元处理,每个调度单元运行于单个线程束(warp)上。由于每个流式多处理器(SM)可以容纳多个线程束,因此单 SM 最多可并发运行 4 个调度单元。每个调度单元维护激活事件队列,并持续执行以下操作:
这种分布式调度机制在实现跨 SM 可扩展执行的同时,最小化协同开销。
事件驱动执行
下图 3 展示了 MPK 的执行时间线,其中每个矩形代表一个在工作单元上运行的任务;每个圆圈代表一个事件。当一个任务完成时,它会递增其对应触发事件的计数器。当事件计数器达到预设阈值时,该事件被视为已激活,并被加入调度单元的事件队列。随后,调度单元会启动所有依赖于该事件的下游任务。
这种设计实现了细粒度的软件流水线化,并允许计算与通信之间重叠,比如
由于所有的调度和任务切换都发生在单一内核上下文内,任务间的开销极低,通常仅需 1-2 微秒,从而能够高效地执行多层、多 GPU 的 LLM 工作负载。
团队对 MPK 的愿景是使巨型内核编译既易于使用又具备高性能。目前,你只需几十行 Python 代码(主要用于指定巨型内核的输入和输出)即可将一个 LLM 编译成一个巨型内核。此方向仍有广阔的探索空间,目前正在积极攻关的一些关键领域包括如下:
团队相信,MPK 代表了在 GPU 上编译和执行 LLM 推理工作负载方式的根本性转变,并热切期待与社区合作,共同推动这一愿景向前发展。
该项目也在快速迭代中,非常欢迎有兴趣的伙伴加入contribute。

文章来自于微信公众号“机器之心”。


