# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
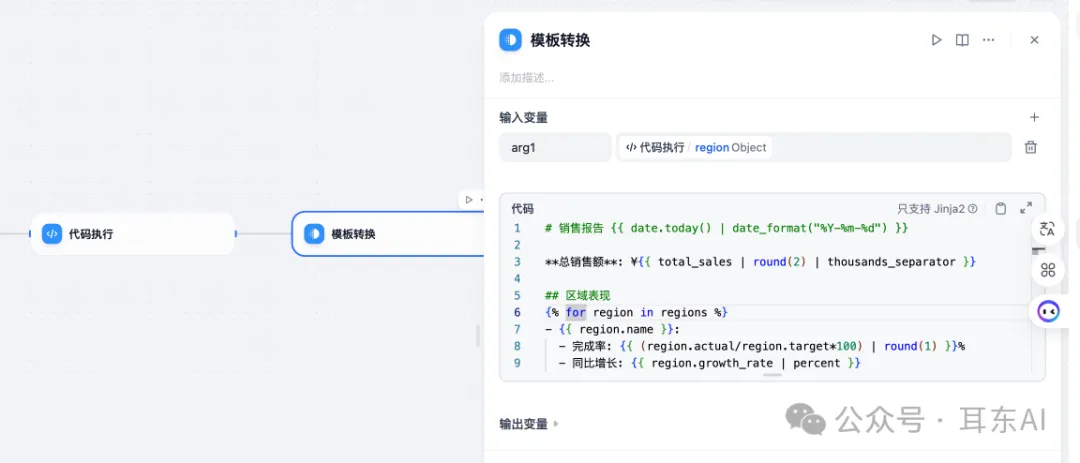
Dify的模板转换节点,是基于Jinja2模板引擎,为用户提供灵活的数据转换能力。借助Jinja2,可以在Dify工作流中快速完成文本拼接、格式转换、数据结构重组等操作,实现"多源数据的无缝衔接与随心转换"。
本文将展开介绍Dify模版转换节点的设计引擎——Jinja2,同时,也将展示介绍Dify模版转化节点的8种典型应用场景,包括:多源文本合成、知识检索结构化、动态表单生成、动态数据报告、智能邮件生成、API数据转换、多语言内容渲染、系统告警模板。
介绍Dify模版转换节点8种应用场景之前,我们先来了解一下Dify模版转换节点的设计引擎——Jinja2。
Jinja2 是一款成熟、功能丰富、安全且高效的 Python 模板引擎。它通过优雅的语法、强大的模板继承和宏系统、丰富的过滤器以及良好的可扩展性,完美地实现了业务逻辑与展示逻辑的分离。
它的主要作用是分离应用程序逻辑(通常是 Python 代码)和展示逻辑(HTML、XML、配置文件等)。实现将动态内容嵌入到静态的文本模板中。
遵循 “Don't Repeat Yourself” 原则,提供强大的工具(如模板继承、宏)来避免代码重复,使模板更易于维护和重用。
3. Jinja2主要应用场景
4. 安装与使用
Dify模版转化节点的8种典型应用场景,包括:多源文本合成、知识检索结构化、动态表单生成、动态数据报告、智能邮件生成、API数据转换、多语言内容渲染、系统告警模板。
将分散的标题、摘要、正文内容组合成完整文档:
代码实例:
{{ title }}
{{ intro }}
{{ body }}

将知识检索节点获取的信息及其相关的元数据,整理成一个结构化的 Markdown 格式:
代码实例:
{% for item in chunks %}
### 知识片段 {{ loop.index }}
**相关度**: {{ item.metadata.score | default('未评分') }}
#### {{ item.title | trim }}
{{ item.content | replace('\n', '\n\n') }}
---
{% endfor %}
代码解释:
{% for item in chunks %}
### 知识片段 {{ loop.index }}
**相关度**: {{ item.metadata.score | default('未评分') }}
#### {{ item.title | trim }}
{{ item.content | replace('\n', '\n\n') }}
{% endfor %}
### 知识片段 1
**相关度**: 92
#### 机器学习基础
监督学习需要标注数据...
无监督学习发现数据内在结构...
---
### 知识片段 2
**相关度**: 未评分
#### 神经网络原理
神经元模拟生物神经细胞...
反向传播算法优化权重...
---
创建支持多种数据格式的交互式表单:
代码实例:
<form data-format="json">
<label>用户登录</label>
<input type="text" name="username" placeholder="请输入账号">
<input type="password" name="password" placeholder="请输入密码">
<label>内容编辑</label>
<textarea name="content"></textarea>
<div class="datetime-group">
<input type="date" name="schedule_date">
<input type="time" name="schedule_time">
</div>
<button data-variant="primary">提交</button>
</form>
将数据库查询结果转换为可视化报告:
代码实例:
# 销售报告 {{ date.today() | date_format("%Y-%m-%d") }}
**总销售额**: ¥{{ total_sales | round(2) | thousands_separator }}
## 区域表现
{% for region in regions %}
- {{ region.name }}:
- 完成率: {{ (region.actual/region.target*100) | round(1) }}%
- 同比增长: {{ region.growth_rate | percent }}
{% endfor %}
代码解释:
# 销售报告 {{ date.today() | date_format("%Y-%m-%d") }}
**总销售额**: ¥{{ total_sales | round(2) | thousands_separator }}
{% for region in regions %}
- {{ region.name }}:
- 完成率: {{ (region.actual/region.target*100) | round(1) }}%
- 同比增长: {{ region.growth_rate | percent }}
{% endfor %}
假设数据为:
regions = [
{"name": "华东", "actual": 85, "target": 100, "growth_rate": 0.15},
{"name": "华北", "actual": 42, "target": 50, "growth_rate": 0.08}
]
生成的报告内容:
# 销售报告 2023-10-05
**总销售额**: ¥1,234,567.89
## 区域表现
- 华东:
- 完成率: 85.0%
- 同比增长: 15%
- 华北:
- 完成率: 84.0%
- 同比增长: 8%
根据用户行为生成个性化邮件内容:
代码实例:
尊敬的{{ user.name }}:
{% if last_login_days > 30 %}
我们注意到您已有{{ last_login_days }}天未登录,为您准备了专属回归礼包!
{% elif unpaid_orders %}
您的订单#{{ unpaid_orders[0].id }}尚未支付,点击完成支付:
{{ unpaid_orders[0].pay_link }}
{% else %}
根据您的浏览记录,为您推荐以下商品:
{% for item in recommended_items %}
- {{ item.name }}(同类用户评分:{{ item.rating }}/5)
{% endfor %}
{% endif %}
将内部数据结构转换为标准API响应:
代码实例:
{
"status": "success",
"data": {
"userInfo": {
"userId": "{{ user.uid | string }}",
"displayName": "{{ user.first_name }} {{ user.last_name[:1] }}.",
"membershipLevel": "{{ 'VIP' if user.points > 1000 else '普通' }}"
},
"features": [
{% for feature in enabled_features %}
{
"name": "{{ feature.name }}",
"config": {{ feature.config | tojson }}
}{{ "," if not loop.last }}
{% endfor %}
]
}
}
根据区域设置动态切换展示内容:
代码实例:
{% set lang = request.headers.get('Accept-Language', 'en')[:2] %}
{% if lang == 'zh' %}
欢迎回来,{{ user.name }}!您有{{ notification_count }}条未读消息
{% elif lang == 'ja' %}
{{ user.name }}様、未読通知が{{ notification_count }}件あります
{% else %}
Welcome back, {{ user.name }}! You have {{ notification_count }} unread messages
{% endif %}
{{ _('current_balance') }}:
{{ balance | currency(locale=lang) }}{{ _('current_balance') }}: {{ balance | currency(locale=lang) }}
生成可定制的监控告警信息:
代码实例:
[{{ alert.level | upper }}] 系统告警
**触发时间**: {{ alert.timestamp | datetimeformat('%Y-%m-%d %H:%M:%S') }}
**影响服务**: {{ alert.services | join(', ') }}
{% if alert.metrics %}
## 监控指标
{% for metric in alert.metrics %}
- {{ metric.name }}:
- 当前值: {{ metric.value }}
- 阈值: {{ metric.threshold }}
- 持续时间: {{ metric.duration }}分钟
{% endfor %}
{% endif %}
{% if alert.suggestions %}
## 处理建议
{{ alert.suggestions | bulleted_list }}
{% endif %}
文章来自于“耳东AI”,作者“耳东AI”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
