# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
FutureHouse 是由 Google 前 CEO Eric Schmidt 资助创立的、专注于 AI for Science 方向的的 AI Lab,团队的长期目标是打造可自主提出问题、规划实验、迭代假设的 AI 科学家体系。
今年 5 月,FutureHouse 推出了四个 AI 科研 agent,分别是 Crow(通用智能体)、Falcon(自动化文献综述智能体)、Owl(调研智能体)以及 Phoenix(实验智能体),这些 AI agent 可访问完整科学文献全文,还具备信息质量评估能力,一个月后,FutureHouse 又宣布自己的 AI 系统 Robin 成功发现了新药。
AI 推动生物科学可以分为两层视角,一层视角是以 AlphaFold 3 、ESM3 到 Evo 2 等模型为代表,把分子-细胞-系统的设计空间瞬间打开,另外一层则是 FutureHouse 在探索的科研自动化,agent 系统构成的 AI Scientist 把实验室变成“黑灯实验室”,进一步变成可编排的软件流水线。FutureHouse 偏向于后者。
本篇内容是对 FutureHouse 联合创始人 Andrew White 的专访编译,他本人是化学材料科学背景,同时也作为 Red Team 成员参与了 OpenAI 模型开发与上线。在这篇内容中,他详细解释了到底什么是 AI scientist,并结合 FutureHouse 的实践详细讲述了如何构建一个 agent 系统。
💡 目录 💡
01 生物比化学更具“平台化”潜力
02 FuturHouse 是在构建科研 API
03 FutureHouse 科研 Agent 开发思路
04 “科研自动化”不是 100% 替代人类
05 AI 是如何影响科学研究的
01.
生物比化学
更具“平台化”潜力
Nathan Labenz:你有化学工程背景,同时又曾经是 GPT-4 红队(Red Teaming) 成员,可以分享下你的经历吗?你是如何进入 AI for Science 领域中的?
Andrew White:我的学术经历主要在统计力学(Statistical Mechanics)领域,从博士、博士后到后来的研究都没离开过这个方向,我们可以把它看作是热力学的一个分支,但其实它更像是研究那些自由度特别高的系统的统计规律,类似于气体、液体、蛋白质,甚至量子系统,都是我们的研究对象。此外,这个领域通常会用到大量的模拟和建模方法。
2019 年,我在 UCLA 访学,加入了纯粹与应用数学研究所(IPAM)这家机构,这个研究所主要做应用数学,当时他们想组织一个主题项目,讨论机器学习在物理科学中的应用。我们那段时间基本都在探索怎么把机器学习用到这些复杂系统上。
当时还处在比较传统的 ML 阶段,需要先做 feature 工程,再去拟合模型,我们团队中有个人叫做 Matias,他和 Anatole von Lilienfeld 一起开发了一个模型,是当时预测小分子能量方面最强的系统。大家都意识到,这种方法在物理和化学领域真的可能改变游戏规则。
后来我开始写 Deep Learning for Molecules and Materials 这本教材,想尝试用 Jupyter Notebook 的形式去呈现内容,反响也不错。这门课我越教越深入,也更早接触到了语言模型。
当时 Gerd Ceder 团队有篇材料科学的论文提出用自然语言来描述的方式把材料的特性转化成计算机可以学习处理的向量表达,而不是传统的用人工去设计和选哪些特征是重要。在这之后,我开始在化学方向做语言模型的实验,和 MIU 的 Glen Hocky 合作,用语音控制 VMD 分子模拟工具,在这个过程中,我们用到了 OpenAI CodeX。随后,DaVinci、January、February 等项目陆续发布,并在几个月后发布了代码库。
在这些项目基础上,我们开始尝试将其应用于分子动力学(MD)模拟,取得了非常理想的效果。相比之下,以往在 VMD 这类工具中进行分析往往依赖 TCL 语言,这种语言语法晦涩、使用门槛高,几乎没有人能熟练掌握。因此每次进行分子动力学或轨迹分析,都需要反复检索、复制粘贴现有代码,甚至通过邮件向他人请教。语言模型的出现改变了这一切,我能够直接生成所需脚本,效率和体验完全不一样。
VMD(Visual Merchandising)是一个分子可视化程序,该程序采用 3D 图形以及内置脚本来对大型生物分子系统进行显示、制成动画以及分析等操作。
TCL(Tool Command Language)是一种基于字符串的脚本语言,主要用于电子设计自动化(EDA)工具控制和自动化任务处理。其核心特征是解释执行、命令结构化及强字符串处理能力,广泛应用于芯片设计、FPGA 开发等领域。
这项尝试最终形成了一篇论文发表在 Digital Discovery 上,因此 AI 与化学、生物、放射性、核安全等议题逐渐受到广泛关注,“Seaborne”一词也频繁出现在关于人工智能安全的讨论中,甚至延伸到恐怖主义和常规战争。
这篇论文是 Assessment of chemistry knowledge in large language models that generate code ,研究中提出,当前具备代码生成能力的 LLM 已掌握相当程度的化学知识,能够针对各类化学问题生成功能性代码,通过 prompt engineering 可显著提升30%的模型准确率。
2022 年 8 月,我被邀请加入 OpenAI GPT-4 红队(Red Teaming)。当时一切都还在起步阶段,我对语言模型在化学中的潜力也还在探索,但后来有几篇关键论文,比如 Miracle paper 和 React paper ,彻底改变了我对这项技术的理解,由此我开始思考语言模型与科学研究之间要如何互动。
当时我出于测试目的,让模型讲解“如何合成神经毒气”,结果它不仅列出了整个流程,还能回答不少合成细节,我第一次观察到语言模型能够生成连贯且具逻辑性的回答。那时我开始怀疑,我们是否需要从根本上重新思考语言模型的部署方式。但当我进一步画出化学结构、追踪反应路径中每一步原子的变化时,才发现它其实并不理解原子如何在分子间转移,只是模拟出一种看似合理的表面逻辑,不过这还是一项重要但仍有限的技术进步。
2022 年底,我开始尝试让模型接入一些外部工具,也正好赶上 CoT 和 ChatGPT API 的热潮,我们也尝试了类似方法,并在这个过程中逐步形成了 ChemCrow 的雏形。在这个过程中,我观察到两点:
1. 模型一旦接入工具,原本那些限制它行为的安全机制几乎形同虚设;
2.在明确边界、约束行为的前提下,它的整体表现反而更稳定。
ChemCrow 是一种专为有机合成、药物发现和材料设计等领域任务而设计的化学领域的 agent。通过整合18 种专家设计的工具,并使用 GPT-4 作为基础模型,ChemCrow 提升了LLM在化学领域的表现,展现出了新的能力。
由此,我们开始意识到:让模型调用工具完成任务,而非直接生成结果,是一条更可控、也更高效的发展路径。
Nathan Labenz:Anthropic 的 Dario 在提到生物和医学进展时,有一个观点是:“真正推动进展的是少数几项‘平台型技术’,一旦人们在理论层面上解决关键问题,就可以套到各种任务上。”和生物相比,化学的测量手段还是实验操作中涉及的各种反应和体系特别多,那种能广泛套用的‘平台技术’反而很少?
Andrew White:我们从一开始对 FutureHouse 的设想就是 bet on “科学自动化(automating science )”。而我们之所以选择从生物学切入,其实原因与 Dario 提到的非常相似:和化学相比,生物学更具平台化的特征。
以蛋白质设计为例,整个流程相对标准化,可以选择克隆、细胞表达,或者直接机器合成。但化学就复杂得多,每个分子几乎都是“定制品”,怎么合成、能否大规模制备都是难题。所以生物更适合作为科学自动化的起点:
• 一方面它的平台化程度比较高,比如测序几乎免费,合成成本也很低;
• 另一方面,生物适合做验证假设,不仅实验设计和结果测量清晰,验证成本也很低。
而且生物学的研究任务本身就具备高度开放性,总有新的生物基因组需要探索和功能注释,总会有新的蛋白质展现出不同寻常的功能,也总有大量未知的元基因组数据等待解读。
相比之下,物理学实验门槛更高、数据获取成本更大,研究也更偏向于还原论,追求用普适方程简化复杂现象。而生物学已经具备进化论这一基础理论,更侧重研究复杂系统在既定规则下的演化与调控。因此,生物不仅是当前自动化科学实践的理想起点,也为语言模型等工具提供了广阔的应用和验证空间。
Nathan Labenz:整个生物学范式中,还有多大可能存在我们几乎完全不了解的重要领域?
Andrew White:我们和 Ed Boyden 讨论过光遗传学,他的实验室是这个方向上的早期探索者之一。
Ed Boyden 是 MIT 媒体实验室和 McGovern 研究所的生物工程及脑认知科学教授。他的主要研究领域是合成神经生物学,是光遗传学的开创者之一。
他们曾经尝试过用一种叫 “tiling tree” 的方法来梳理研究思路:先明确目标,然后列出所有可能实现目标的方法,再按照思路的类型进行分类。比如可以往大脑中传递某种物质、传递信号,或者直接通过手术把某种装置植入大脑。
接着再细化,例如信息要怎么传递给组织,可以尝试磁波、无线电波,或者能穿透组织的光。这个方法就是一层层展开,把路径尽可能列全。
他认为,这个领域永远不会缺少新的研究方向,因为新的可能性总会不断出现。生物系统本身就非常复杂,各种作用关系十分多样。
以蛋白质为例,了解它不仅需要知道晶体结构,还需要考虑它的统计状态、翻译后修饰、内部化学反应(比如甲基化),甚至包括蛋白质内部“水线”上传质的细节,这些都需要建模。单靠一个简化的结构图,没法完整还原蛋白质的行为模式。生物系统的每一层都包含细节,这些细节往往对整体功能有决定性影响。
生物学高度依赖实验观察和重复验证,而不是仅靠计算模型推导。因此,认为超级智能或通用人工智能“某天会突然想出治癌症的方法”并不现实。对生物系统的理解必须建立在实验基础之上,持续地提出和检验假设,光有推理能力并不足够。
02.
FutureHouse
是在构建科研 API
Nathan Labenz:你刚刚提到了 FutureHouse 和你们的几个研究项目,能否先介绍一下 FutureHouse 是什么?
Andrew White:我和 Sam Rodriguez 共同创办了 FutureHouse。Sam 最早提出了“聚焦研究组织”(Focused Research Organizations, FRO)的概念,主张通过非传统科研机制推动重点领域的研究。

FutureHouse 创始团队他先是和 Tom Khalil、Adam Marblestone 一起创立了 Convergent Research,发起了一系列五年期、预算在 2000 万到 5000 万美元之间的非营利项目,专注解决那些学术界和产业界都难以单独解决的重大科学问题,比如开发新模型生物体、绘制脑连接组,或建设编程语言 Lean 的基础设施。
在这个基础上,Sam 又提出了 FutureHouse 的构想。它延续了 FRO 的基本规模和运行周期,但更加聚焦在“Moonshot”级别的挑战:这类项目可能需要 5 年以上的持续投入,因此要更多资金,或依靠商业化手段来实现延续。
这个想法最初由 Sam 提出,当时我刚完成 ChemCrow 项目,也在研究 LLM 和相关技术。我建议将 FutureHouse 的方向聚焦在如何利用 AI 自动化科学研究上。我们把这个想法告诉了 Eric Schmidt ,他当时对 AI 的发展趋势非常关注,认为这个方向值得推进,于是支持我们从零开始组建了 FutureHouse。
Nathan Labenz:可以简单讲讲 FutureHouse 的发展过程吗?从最初的起步阶段,到最近发表的几篇论文,包括你重点关注的 PaperQA 和 Aviary 项目。
Andrew White:ChemCrow 是我们早期的一个工作,目标是用语言模型和相关工具实现完整的科学发现流程。我们结合逆合成预测、文献检索和代码执行,配合 GPT-4,设计出了一种新型染料。
具体来说,我们训练模型预测分子的吸收波长,再用逆合成工具和文献搜索寻找满足条件的新分子并给出合成方案。最终由 IBM Robo RXN 云实验室机器人完成合成,测试实际结果与预测相差约 15 纳米,基本实现了闭环自动化科研。虽然部分步骤因时间紧迫由人工完成,但 ChemCrow 项目的其他 case 则全由机器人操作。
这个项目让我感受到了科学文献的价值。我们几百年来积累的庞大知识网络是科学研究的基础,但这些文献经常被锁在付费墙后,而掌握文献是科学工作的核心,创新反而只占很小部分。FutureHouse 的目标就是理解并利用这些文献,判断已有的研究与创新点,推动科学自动化。
我们做的第一个项目是论文问答系统 PaperQA,这个项目其实比 FutureHouse 的诞生还要早,它是基于 RAG 的思路构建的,但在 RAG 基础上做了一些改进。
这个 AI 系统首先会先检索所有相关论文,然后对每个片段进行摘要和排序,最后生成答案,而不是直接把搜索到的结果拼接之后给到模型,虽然核心思路看起来简单,但我们花了很多时间定义正确答案的标准,确保文献覆盖全面,还评估系统表现,并保证结果稳定可靠。
PaperQA 项目的产品是 WikiCrow。经过多次改进,系统的表现已经超过了人类。我们还写了一篇详细的工程博客,分享了整个过程。
WikiCrow 这个系统帮我们把人类基因组相关的维基百科内容大规模整理了出来,从原本只有大约 2500 个基因的介绍,扩展到了近 1.8 万篇文章,基本完成了基因组知识的系统总结。它还能以每分钟回答 75 个问题的速度,高效地处理这些内容。
WikiCrow:通过分析成千上万篇论文,为人类蛋白质编写百科全书式的摘要,包括其结构与已知功能。
我们还开发了一个矛盾检测系统,能在超过两亿篇论文里查找和任意陈述相冲突的信息。现在它已经可以每天自动检查 arXiv 上的新论文,看看有没有和已有文献矛盾的地方,并且每三周更新一次关于疾病的维基百科条目。
PaperQA 是一个完整的项目,我们搭建了 Infra 和 API,这个项目实现了超越人类的表现。有了这个基础,我们后来推出了 Aviary 项目。我们将 PaperQA 拆分为两部分:environment 和 agent。Environment 就是可用的工具,比如查看引用、总结论文、进行 Google Scholar 搜索、关键词检索等。Agent 则负责决策,比如选择继续 Google Scholar 搜索,或者转用 Semantic Scholar,查看某篇论文的引用情况。
Aviary 的理念是构建多个科学任务环境,超越单纯的文献检索。我们设计了各种不同的代理,不仅是不同的语言模型,还有带有记忆、多步思考、反思能力的代理,甚至内置奖励模型的代理。
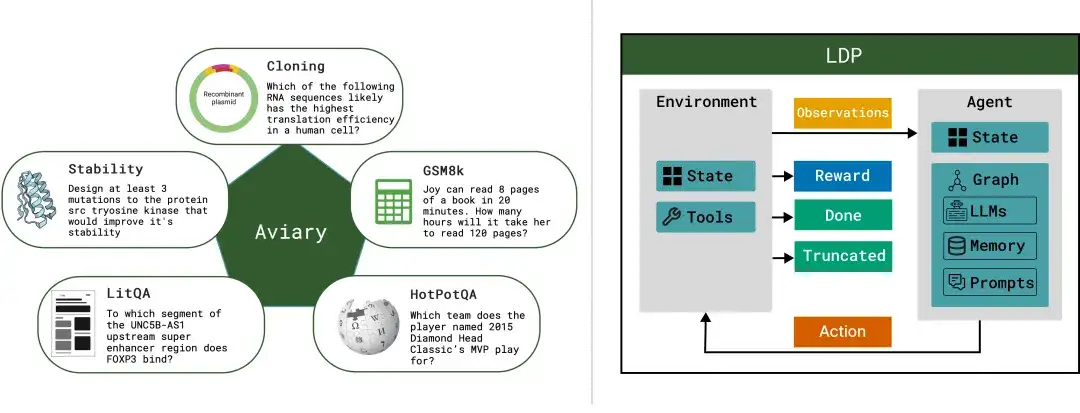
我们把 environment 和 agent 一起训练,最终形成一个名为 Crow 的系统。Crow 既能使用工具,又能进行语言交互,它的名字灵感来源于能说话又会用工具的乌鸦。
到今天我们已经部署了多个不同的 Crow,它们各司其职,构成了一个智能微服务平台:查找矛盾、文献研究、分子设计、特定蛋白质的克隆设计等等。通过整合这些功能,我们实质上正在构建一个科研的 API。
03.
FutureHouse
的科研 Agent 开发思路
Nathan Labenz:你们论文里把 agent 和 environment 区分得很清楚,并且强调 memory 是 agent 内部的,这其中的思路是什么?
Andrew White:我们在论文里提出了一个实用定义,把所有需要训练的部分称为 agent ,未训练的部分叫 environment。Agent 通过语言、观测和动作与环境交互。这样的划分让设计更简单,也方便自由组合不同的 agent 和 environment。基于这个框架,我们决定把 memory 从 environment 移到 agent 。
在 memory 上,我们尝试过很多形式,比如简单追加消息,或者在消息过多时压缩,有时只保留最近几条,还结合了检索增强生成。记忆必须是可训练的,因为设计中涉及截断长度、压缩策略和信息保留等超参数,所以记忆应当是系统整体的一部分。
我们把 agent 看作一种随机计算图,这和传统的状态机不太一样。计算图是一步步往前执行的,没有递归,也没有隐藏的内部状态。Agent 的状态由输入传进来,然后输出新的状态和动作。这样的设计不仅方便高效,还能轻松实现序列化和反序列化,也更适合反向传播,解决了训练中的很多实际问题。
我们的论文没有包含训练结果,不过目前的实验已经表明,不同的训练策略在multi-environment 和 multi-agent 上都能通用且有效。
这个框架的主要目标是突破零样本的限制。现在大多数 agent 还靠手动调参和提示设计,不需要复杂框架,而我们更关注可训练性,支持在线 RL,比如在线 PPO。我们这方面和 DSPI 有些相似,不过 DSPI 没有在真实环境里做强化学习。
Nathan Labenz:你提到用语言模型过滤和识别相关性,而不是只靠 embedding。除了这点,你觉得还有哪些关键因素推动进展?做类似项目应该重点关注哪些?
Andrew White:我觉得这确实是个关键点,解决了很多问题,比如分块大小和解析质量。但这样做也带来了更高的成本和更长的响应时间。像 Perplexity 这种面向普通用户的产品还没用上这种两步流程,因为那样会让响应变慢。
我觉得这也反映了两种不同的理念。我们更注重性能,成本和延迟反而放在其次。而大多数人还习惯 Google search 那套结果快、成本低的模式,靠大量投资建立超大索引来实现低成本查询。相比之下,我们没有花力气做大索引,而是实时处理所有数据,所以成本更高,没办法通过规模摊销。
另一个很重要的点是全文检索。现在很多学术搜索引擎其实并不是全文搜索,这就丢失了大量信息。也因此,大多数基准测试和竞品工具只用摘要和标题来做搜索,因为这些数据比较容易拿到,真正的全文检索非常少见。我们自己搭建了全文检索系统,并且把相关代码开源在 PaperQA2 里,方便大家自己搭建索引。
我们内部用的系统就是全文搜索,技术上可以用 Postgres 或 Elastic Search,也可以结合 Google Scholar 和 Semantic Scholar 来提升性能。
任何能过滤掉干扰信息的技术都非常重要。我们在工程博客里也分享了很多方法,比如如何筛选潜在相关内容、怎样高效做摘要,所以全文搜索和 RCS(检索加上下文摘要)是我们工作里最核心的两大环节。
Nathan Labenz:coding,控制流程和 prompt 这些都很简单,基本都属于工具,你们是如何做到用看起来很简单的设计实现这么好的效果的?
Andrew White:我们库里的内容比较通用,比如 WikiCrow 和 Contra Crow 的配置,前者负责总结,后者负责找矛盾。我们还调整了策略,把很多复杂的工具功能都封装到 Aviary,它会把 Python 函数签名和文档字符串转换成语言模型能用的工具接口,文档字符串里详细写了具体操作细节。
举个例子,我们让模型执行多关键词搜索,这类似于 Perplexity Pro 的查询扩展功能,通过用不同的关键词表达并多次搜索来提升检索效果。我们还有一个内部工具 “hasanyone.com”,结合了我们论文数据库和搜索工具,专门用来查某个问题有没有相关研究。
PaperQA2 也做了不少优化,比如用 Rust 写的 Tentatively 库来构建搜索索引,更贴合用户需求。总体来说,我们的工具和流程一直在持续完善,既实用又具备良好的扩展性。
Nathan Labenz:这些方法换到完全不同的领域会有效吗?
Andrew White:这些方法确实适用很多不同领域。我们在历史、人类学等领域都有实际应用。我们还有一个可以通过短信进行问答的系统,随时发问、随时回复。
系统能够访问这些领域的大量论文资源,比如 arXiv、Camerchive、Meta Archive 等开放平台,还有我们缓存的内容,所以覆盖面相当广。
不过也存在不均衡的情况。比如在机器学习领域的表现很好,因为大多数论文都在 arXiv,拿取很方便。但在内科医学领域就没那么顺利了。尽管有些权威期刊是开放获取的,但它们被 Cloudflare 等反爬虫机制保护,抓取困难,这直接影响了系统的整体表现。不同领域、不同期刊的开放程度,确实会对效果产生不小的影响。
Nathan Labenz:你们是否尝试过让模型理解和处理论文中的图表?未来会不会把图表分析纳入到 PaperQA 系统中?
Andrew White:有一个叫 Fig-QA 的 benchmark,用来评估模型理解科学图表的能力。这个测试难度比较高,包含了一些复杂的图表和问题。目前 Claude Sonnet 的表现已经超过了人类平均水平。
接下来我们打算把图表分析的能力整合进 PaperQA,目前正在开发 PaperQA2 的第六个版本,这一版会支持图表识别。实现方式其实也不复杂,文本部分用来做搜索,图像会在后期处理阶段,比如 RCS 时再输入模型,帮助生成更准确的答案。我们现在判断,模型已经足够强,可以支撑起大规模的图表理解任务。
虽然我们没有专门发论文或者做很多基准测试,但目前的思路是文本主要用于检索,图表部分只保留图注参与搜索,真正处理时直接用整页截图,不再做复杂的结构解析。现在模型处理图像的能力已经很强了,直接看图也基本没什么问题。
我们之前也试过用 LabelBox 做人工标注,提取图像里的结构信息,也研究过像 PSI INT 那样的自动提取流程。但 PDF 的格式实在太多样,程序化提取总是不太稳定。最后我们发现,最稳妥的方式还是把页面渲染成图像,让模型直接看图来理解。
Nathan Labenz:所以你们现在的判断是,图像模型已经够强大,不再需要像 Marker API 这类专门做结构解析或切分的工具了?
Andrew White:我们的理念其实很简单,就是愿意投入更多时间和资源,换取更低的技术复杂度。虽然像 Marker API 这种基于精调模型的结构解析工具确实存在,但我们更倾向于采用更直接、更稳定的方式,也就是把整页截图交给一个足够强的模型,让它看图作答。
现在的模型,比如 Sonnet,只要提供图像、标题和周围的文字,就已经能准确理解图表内容并回答相关问题。既然效果已经足够好,我们认为没有必要再引入更复杂的结构解析工具。
Nathan Labenz:我还没看到 Clause 在 RKGI 奖上的最新得分。几个月前他们用 3.5 架构模型在编程方面有了突破,我当时让它解 RKGI 题,结果发现它连数方块、识别基本视觉元素都不行,完全无法进行后续推理,这可能就是你说的模型学习顺序反了。
RKGI 指抽象推理语料库(Abstraction Reasoning Corpus for Artificial General Intelligence),它是由 Keras 之父 François Chollet 提出的一个数据集,旨在评估 AI 的泛化能力和抽象推理能力。
Andrew White:我们最初做基准测试时,关注的是“回忆型任务”,比如把表格转成 JSON,或者提取图中所有数值,但模型表现不佳。后来发现,更重要的是“判断型任务”,比如根据图表判断某个处理是否有效,模型在这类任务上表现非常好,甚至超过人类。
这对我来说是个思维转变。比如给 Gemini 一次性要它总结十万字文档的 50 条结论,效果不好。但分条问它“第一条是什么”、“第二条呢”,表现会好很多。图表理解也一样,问具体问题时模型表现好,一次性提取全部信息则容易出错。
Nathan Labenz:你们会考虑问题运行的成本和延迟吗?
Andrew White:想体验系统的实际延迟和成本,可以去 hasanyone.com 试试。每次提问大概花费在 15 美分到 1 美元之间,具体取决于问题的复杂度。比如问“有没有人做过 X”,如果 X 是个小众但有一定关注度的问题,系统就会做大量搜索。反过来,如果问“有人在华盛顿纪念碑降落 UFO 吗”,搜索量就会很少。
至于我们的 Github 项目,我们故意设计了比较复杂的安装流程,主要面向熟悉技术的程序员和黑客。如果想做到一键安装,就得适应大量普通用户,但目前我们遇到了不少兼容性问题。比如 Google Colab 不支持 Python 3.11,而我们的代码用了 3.11 的特性。虽然 Ethan Malik 已经让它能在 Windows 上运行,这也算是个进展。
Nathan Labenz:这个项目会完全产品化吗?
Andrew White:我们收到不少商业化的需求,比如企业并购调查、知识产权搜索,还有博士研究项目。一般来说,我们会给学术用户开放 API,限制每天五次请求,同时支持一些创新项目,比如先用模型生成想法,再用 PaperQA 来验证。
不过,在使命和商业化之间,我们还没找到理想的平衡点。商业化能带来收入,帮助团队壮大,但也可能让我们偏离最初的目标。这个问题我们一直在思考,还没有做出最终决定。
Nathan Labenz:你们提到用多层感知机对语言模型行为建模,并对当前配置附近节点反向传播来获得黑箱梯度估计,可以用更简单的话解释一下吗?
Andrew White:Jianshun 写过一篇关于随机计算图的论文,详细讲了计算图的结构和如何对随机节点做反向传播。我们发现他的论文正好描述了我们的设计框架。Albert 和 Sid 在此基础上扩展,尝试对“黑箱”节点进行梯度估计。
黑箱节点指的是那些我们没法直接反向传播的模型,比如调用 Anthropic 或 OpenAI 的 API,因为不能追踪输入的梯度变化。为了解决这个问题,他们用一个多层感知机来模拟黑箱模型的输入和输出关系,从而估计梯度。具体做法是多次调用黑箱模型,比如温度为 1 时调用五次,来估计输出的波动情况。然后通过改变输入参数,观察输出的变化,再用感知机去拟合这些变化,从而得到梯度的近似值。这个过程算力消耗挺大的,估计每次输入需要调用模型大约 25 次。实际用的时候,先用代理多次做前向推理,得到很多轨迹,再用这些数据做反向传播和梯度估计,同时通过聚类等方法减少计算量。
论文里展示了可以用这种方法来优化模型参数,比如温度和提示词中的超参数,这是一种非常规的反向传播方式。不过这更像技术演示,表明黑箱模型的反向传播是可行的,但实际优化效果有限。通常温度等参数已经有较优值,变化不大,参数间相关性低,所以收益有限。
在优化器设计上,我们把模型分成两部分:一个是黑箱的大语言模型,另一个是评估黑箱模型输出的模型。黑箱模型生成多个输出,评估模型对这些输出评分,选出最佳结果。评估模型是开源的白箱模型,可以正常反向传播,黑箱模型则不用反向传播,因为其上游参数影响有限。这是一种混合学习策略,开源模型作为闭源模型的引导或奖励模型,闭源模型负责生成动作参数,强化学习模型根据历史经验评估并选出最优输出。
Nathan Labenz:针对一些前沿任务,比如“设计一个在性能上优于现有蛋白的新蛋白”,使用这种端到端可训练的智能体能带来多大提升?
Andrew White:这取决于任务。在 paperQA 任务上,大概能提升 5 到 10 分,因为这类问题更开放复杂,提升有限。而对公式化程度更高的任务,如 CQA,提升更明显,可能从 50 分提升到 70 分左右。这是因为 CQA 的任务更结构化,Q 学习(Q-learning)能更好发挥作用。这个训练流程让我们能够基于环境和数据回合不断改进,而不是仅靠调整提示词或温度参数。
Nathan Labenz:你们提升主要靠大量生成候选,再用奖励模型筛选,那运行时每遇新问题都要多次生成答案,然后实时选择吗?
Andrew White:Joyce,Q 学习模型(Q-learning)是我们用的开源模型,也试过 Phi 和 Lana,都是针对特定任务调优的。评估时会用新的题型测试,所以在特定环境下答选择题时,模型能有不错的泛化能力。但如果让它写文献综述,效果可能就不太理想了。这也涉及到一个问题:这些代理和环境到底要多“工程化”?目前还没定论。大致来说,你得定义好几百个任务,模型才能在这些任务上表现好,但对于没见过的新任务,模型的表现还不确定。
Nathan Labenz:运行时遇到新问题时,如果用黑箱模型(比如 0,1)来回答,是不是必须多次生成答案,再由 Q 学习模型选出最优答案?
Andrew White:是的,通常你可以设置生成几个结果,比如 8 个。模型会生成 8 个答案,然后 Q 学习模型选出最优的那个反馈给环境。因为环境一旦执行步骤就不能回头。我们也尝试过树型搜索策略(tree search),把环境复制多份,对每个生成的答案都展开,类似做深度搜索,找到正向奖励的路径。这个方法帮助我们在任务中找到有正反馈的轨迹,避免从零开始完全没有正向奖励。
04.
“科研自动化”
不是 100% 替代人类
Nathan Labenz:你有一个观点是 AI 在长期内仍需保持“半自主”的状态?为什么?在哪些方面必须有人介入?
Andrew White:我对实验室机器人(laboratory robotics)的前景相对谨慎。虽然未来可能实现,但其实目前已经有不少生物科技或 AI 公司尝试将现实世界的科研流程全面自动化,最终都未能完全成功。比如 Emerald Cloud Lab 和 Ginkgo Bioworks,虽然取得了一定进展,但距离完全自动化还有相当长的距离。科研全自动化本身就是一个极具挑战的目标,而在 FutureHouse,我们的资源有限,因此我们选择不优先投入这一方向。
理论上,如果未来出现真正自主运行的科研 AI,它可能需要配套自己的实验设施和机器人系统。但这不是我们当前要解决的问题。如果将来有团队解决了实验室自动化,我们会考虑采购或合作。
当然,我们并非完全不涉及实验室自动化。我们也会使用常规的自动化设备,比如机械臂、液体处理器、声波移液平台等,但这些只是工具层面的选择,不是我们工作的核心。
我们和市场上的一些观点也有所不同。我不认为 10 年后会出现那种完全自主的科研系统。一个更可行的情景可能是:我们面对某种疾病及患病人群,向系统提出问题,比如可能涉及的生物机制、潜在靶点、可设计的分子结构,以及从哪里入手推进研究。在这样的流程中,系统的角色是辅助判断和生成方案,人类则提供明确的问题和研究框架,并和系统反复协作。
另一个核心点是,生物学本质上是一个受限于观测和经验数据的学科。它不同于数学,后者可以在定义明确的系统中由 AI 独立开展探索,并周期性地产生新的定理或证明。而在生物学中,无法简单指令系统完成例如“做这 36 个小鼠实验”的任务,因为涉及动物采购、CRO 合作、伦理审批等复杂流程,这些环节目前仍然需要人类深度参与。
因此,在可以预见的时间内,AI 更适合以半自主的方式嵌入到科研流程中,而不是作为完全独立的执行者存在。
Nathan Labenz:Emerald Cloud Lab、Ginkgo Bioworks 等公司其实并不是真正全自动的。它们对外提供的是一个可编程的界面,看起来好像你在指挥机器人,但实际上背后往往是机器人加人类协作在完成任务,不是纯粹的“自动化科学”。
Andrew White:我并不觉得一定要“必须实现全自动”。现在很多所谓的“生物机器人”系统在关键环节仍然依赖人工介入,因为有些操作人类用几分钟就能完成,反而比强行自动化更高效。
今天确实一类“lights out automation”的说法,指的是实验室在没有人值守的情况下仍可持续运转,说明已经实现了完全无人化。但对我们来说,这并不是主要的评判标准。像 Ginkgo 或 Emerald 这样的实验室,自动化程度可以达到 98%,已经足以支撑它们的规模。
也有一些公司在探索新的路径。例如 Medra 正在尝试开发配有人类“抓手”的机械臂,可以在常规实验室中自由移动、操作实验流程,从而减少对专用设备和定制空间的依赖。但整体来看,实现真正意义上的 100% 自动化仍然非常困难。越接近完全自动化,所需投入就越高,而边际收益反而会逐步减小。
Nathan Labenz:你提到不能仅靠内部推理理解生物系统,还必须依赖外部实验。那么除了内部分析和明确任务外,AI 拥有类似 Emerald Cloud Lab 工具和 API 时,能否实现自由探索生物学?
Andrew White:可以设想一个类似“Science Dojo”的平台,集成了各种科研工具,比如实验模块。使用时,虽然仍然需要人工设计测量方案,但实际上是在尝试实现科学方法的自动化。从这个角度看,半自主和全自主的差别并不那么重要,关键在于流程是否可以被有效组织起来。
Data Science Dojo 是专注于数据科学教育和培训的社区平台,提供各种数据科学相关的培训课程,包括机器学习、数据分析、Python、R、SQL 等技能的教学。
我们也在推进类似的工作,比如将药物发现、文献调研等环节模块化,构建成一套可调用的工具链,然后由 LLM 根据输入的参数,按步骤调度这些工具,探索潜在的新发现。
我也在思考另一种可能性:如果把博士生,或者类似 Mechanical Turk 平台上的人力资源,嵌入到这个流程中,会产生什么效果?目前还没有人真正尝试用统一的调用接口来组织科研任务,并让人类以这种方式参与进来。我们还不清楚人在这个架构下能起多大作用。
Mechanical Turk 即 Amazon Mechanical Turk (MTurk),这是亚马逊提供的众包平台服务,将需要人工完成的小任务分发给全球的工作者,主要包括数据清洗、图片识别和标注、文本分类、产品评论、学术研究的数据收集等任务。
这是一个新的方向,用可编程的工具来推进科研,只不过工具背后执行的不是模型,而是人。也许这会成为未来的一种科研模式,也可能人类不适合这种方式,模型也做不好,甚至整个机制根本行不通。但无论结果如何,这是一个值得探索的方向,我们也在尝试中。
05.
AI 是如何影响
生物科学研究的?
Nathan Labenz:随着 AlphaFold、ESM-3 和 ESM-4 等技术不断进步,实验会越来越依赖计算预测,先在计算中筛选,再用实际实验验证。这样做能大幅提升实验的命中率,可能提高十倍甚至百倍。FuturHouse 是如何设想这件事的?
Andrew White:目前我还没完全理清楚,但有几个点容易被忽视。比如,用云计算计算分子和蛋白结合的自由能(free energy),成本大约十几美元,有机合成和实验验证成本也差不多,甚至更低,两者都在同步下降。依托摩尔定律或更先进的机器学习,计算替代实验的临界点可能很快到来,但这主要限于小分子结合亲和力(small molecule binding affinity)这类具体领域。
小分子结合亲和力(Small molecule binding affinity)指小分子化合物与目标蛋白质结合的强度或紧密程度。
15、20 年前,人们认为分子动力学能解决蛋白质折叠和许多生物难题。De Shaw 团队结合硬件和软件资源,搭建了加速蛋白质模拟的系统,目前能模拟毫秒级动态,预计 2030 年能模拟细胞器,2050 年能模拟人工细胞周期,最终实现虚拟细胞模型。
但分子动力学不能模拟化学反应,而生物过程大量依赖酸碱反应,如 ATP、ADP 和质子的转化,单纯原子运动模拟无法描述细胞功能。
因此,研究者开发了基于经验数据的反应力场模型和机器学习模型。但质子在水中的迁移是量子效应,必须通过电子密度计算和 Born-Oppenheimer 近似才能模拟,缺失这部分会导致对生物机制的误判。
这说明生物系统模拟极其复杂。虽然 AlphaFold 解决了大量蛋白质折叠问题,但蛋白质中仍有许多无序区域。粗粒度模型如 Calvados、Martini 可覆盖约 80%,但部分区域还是难以准确描述。
虽然经验性 ML 和第一性原理方法各有作用,但实验测量依然是最可靠的,计算主要辅助提高实验效率或减少次数。对于这个问题,我暂时无法得出确切答案。
Nathan Labenz:如果设计新的、未合成的小分子,生成大量假设候选再用模型筛选,这些分子合成依然很贵?今天的情况是什么样的?
Andrew White:这个问题还没有定论。目前有虚拟分子库,比如 Zinc,收录了数百亿种理论上可合成的分子。研究者可以直接从这些库中筛选分子,而不必依赖生成模型。大多数分子可以以大约 80% 的成功率订购到,失败率约为 20%,通常在可接受范围内。
还有不少模型能够预测合成反应,帮助设计分子的合成路线,比如 IBM 和 Postera 的相关产品,基本解决了合成难题。在实际药物研发中,化学合成成本也有所下降。例如,中国和印度的化学家年薪加上实验室费用大约在十万美元左右,一周可以合成约 20 个分子。尽管成本仍不低,但已经相对合理。
不过,药物分子的复杂度在不断增加,比如 PROTAC 这类需要完成多重任务的大分子,合成难度又回到了几十年前的水平。这类分子的设计必须更加谨慎,因为实验次数有限。总体来看,合成手段进步很大,但挑战依然存在。
Nathan Labenz:AI 是否能通过学习多组学数据,帮助我们理解尚不清楚的生物机制?你怎么看这类模型的潜力,比如 Evo 就是其中的代表?
Andrew White:这条研究路径其实早于 Evo 模型。像 Recursion、Insitro 和 Calico 等公司,都尝试过构建生物学领域的 foundation model,想要把将小分子药物、基因表达和细胞成像的表型数据整合进一个大模型,目的是预测药物如何影响基因和细胞表型,从而发现新的生物靶点。
这个思路其实延续了人类基因组计划以来的思路:从识别所有基因,到追踪基因变异,再到全基因组关联研究(GWAS)等方法的尝试。
但这些手段并没有带来根本的突破,虽然像 DepMap 这样的项目还在进行,核心问题仍未解决。
当前的遗传基础模型在宏基因组学、转录因子识别和调控网络等领域可能有应用价值,但不太可能成为理解疾病机制或细胞内部运作的关键突破。它们更像工具箱中的一种工具,而不是能够改变游戏规则的手段。
所以我对这一方向持保留态度。虽然从理论上看有潜力,但多年来类似尝试都没有取得实质性成果。经历过多轮技术热潮后,业界的主流观点变得更谨慎甚至偏向悲观。它们是否能真正推动疾病治疗,还需要时间来检验。
Nathan Labenz:生物 AI 领域是否也像早期机器学习那样,好的模型和想法其实早就存在,只是还没达到能发挥作用的数据和算力规模?
Andrew White:是的,生物学的一个最大挑战就是验证周期太长,ML 的优势在于试错快、反馈快,尤其算力规模提升之后就能迅速看到效果。但就算在 ML 里,也常遇到“scaling-up” 失效的问题:一些方法在小模型上管用,放到大模型上反而不行。在这种情况下,大规模实验其实像一道筛子,能帮我们判断哪些想法真的成立。
生物学也类似。有些蛋白质在体外可以很快测试,但一旦进入细胞、动物甚至临床,验证速度就明显慢下来了。像研究衰老这种问题,要验证药效,往往就得等老鼠自然死亡,整个过程非常耗时。
药物开发更夸张,从发现机制到推进到二期临床,通常要 7 年,而真正决定疗效的,往往就在这 7 年里。但等我们拿到结果,团队可能早换人了,最初的研究动机也记不清了。
所以有时候,正确的方向早就提出来了,但因为反馈太慢,可能要几十年才知道对不对。像 Insitro 花了七年才推进第一个分子到临床;Recursion 声势很大,但核心资产大多来自收购,平台本身有没有跑通还不好说;Atomwise 的方法也很先进,结果看起来也不错,但早期失败的原因往往不是技术问题,而是靶点选错了。生物研发成本高、变量多、周期长,这也是研究难以判断结果的原因。
我们现在遇到的问题本质上还是在“等scaling law”发挥作用。拿药物研发来说,现在最大的瓶颈不是算法,而是临床试验的第一位病人什么时候能入组,光这一步平均就要等上六十天。如果这个流程能提速,可能比造一个新模型更实际,但偏偏这类工作不吸引眼球,没人愿意投钱做。
Nathan Labenz:考虑到政府对数据管控的要求,目前有什么政策手段可以加速生物医药领域的数据获取,提升模型训练效率?
Andrew White:政府其实完全可以公开所有已经获批药物的 IND(新药临床试验申请)资料包,其中包含大量珍贵的毒理、药理和制药方面的数据。这些药物已经上市,有专利保护,不再涉及竞争,而相关数据的获取成本又极高。
目前,这些资料基本都保存在 FDA,但并没有什么合理的理由继续对外封闭。如果能够开放,能给机器学习模型提供非常丰富的训练资源,提速药物研发。
Nathan Labenz:你认为未来 AI 发展会更倾向于模块化、可控的 Vertical 系统,还是由强大的通用大模型主导的“全能黑盒”?
Andrew White:我觉得在实验室里用大型模型跑每个任务会很难,尤其是像 GPT-4o 或 GPT-4 这样规模的模型。因此,我们现在做的系统可能会成为未来的趋势:先用一个强大的模型生成高质量的多步推理或者规划,然后再用一个更简单的模型来执行这些计划。这是必然的发展,因为目前推理成本还算低,但未来可能推理成本会更高,模型也会更大。大模型在推理时计算量大,主要用来辅助训练或支撑轻量级模型。从今天硅谷的技术趋势来看,未来的模型很可能不会保持现在这种低推理成本的特性。
从长远来看,我依然很看好 FutureHouse。它能让你同时处理成千上万个小任务,每个任务耗时几分钟,成本几十美分,最终用几百美元完成一个巨大的知识密集型任务。
我们的自动化科学方法可能不会完全模仿人类科学家,而是开辟一条新路。举个例子,我们可以做大规模的文献搜索,筛选某个组织内每种疾病相关的抗体或者表面受体的论文,然后生成一个发现矩阵,再用轻量级机器学习处理这些数据。一次处理上万篇论文是人类科学家难以做到的。
我们不是想取代传统科学家,而是想开创一种新的科学方式。这需要我们改变对模型的思考。未来的系统不会是那种低延迟、智能对话型的,而更像是工程化、高效能的分布式系统,或者少数几个聪明模型配合大规模的“分布式计算”方法,覆盖更多领域,完成大量简单的智力任务。
我不确定未来会怎样,但很庆幸我们有 Adroit 这样的平台,可以在各种环境中训练复杂的智能体。这对我们来说非常振奋,尤其是看到完整的系统能让我们在多样的环境中训练模型,而不是只专注训练单一模型或者提示词。未来值得期待。
Nathan Labenz:那你觉得接下来哪些突破最值得期待?比如哪些关键技术可能会带来大变化?
Andrew White:现在大家都讲“多样性”和“产出”,但从 Eden 的测试结果来看,模型生成一百个解释后,真正有新意的也就前三四个,后面大多是同一思路的变体。模型很难发散出很多不同观点,这限制了它们在某些场景的表现。
我还关注机器人和互联网的关系。现在爬网页越来越难,很多网站有反机器人措施。以前 Reddit、Stack Overflow 是好数据源,但现在都限制了。X 也变得封闭,Blue Sky 被机器人攻击,内容很快被淹没。
我担心未来会出现“死互联网”,即机器人占据网络空间,人类开发者却被各种限制挡住,机器人做不了有效工作。
学术论文虽然开放获取,但程序化访问也越来越难。我觉得我们或许需要建立一个新的系统,专门支持 AI 与世界的交互,而不是仅靠现有的、限制多且杂乱的网络环境。
Nathan Labenz:FutureHouse 接下来有什么计划?
Andrew White:Aviary 是我们打造智能体和环境的关键一步,我很期待把这些部分整合起来。未来我们会推出开放式科学演示。如果有人对 PaperQA 有想法,我们已经开放了 API 并且在合作,也欢迎新的创意。
同时,我们也关注非盈利工具的发展,比如 Semantic Scholar 和 Crossref,他们还在探索开放获取和服务模式,我们也在尝试用非盈利方式提供知识服务。
文章来自公众号“海外独角兽”,作者“拾象”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】ScrapeGraphAI是一个爬虫Python库,它利用大型语言模型和直接图逻辑来增强爬虫能力,让原来复杂繁琐的规则定义被AI取代,让爬虫可以更智能地理解和解析网页内容,减少了对复杂规则的依赖。
项目地址:https://github.com/ScrapeGraphAI/Scrapegraph-ai
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
