# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
只需一眨眼的功夫,Mercury 就把任务完成了。
「我们非常高兴地推出 Mercury,这是首款专为聊天应用量身定制的商业级扩散 LLM!Mercury 速度超快,效率超高,能够为对话带来实时响应,就像 Mercury Coder 为代码带来的体验一样。」

刚刚,AI 初创公司 Inception Labs 在 X 上宣布了这样一个好消息。该公司的创始人之一 Stefano Ermon 实际上也正是扩散模型(diffusion model)的发明者之一,同时他也是 FlashAttention 原始论文的作者之一。Aditya Grover 和 Volodymyr Kuleshov 皆博士毕业于斯坦福大学,后分别在加利福尼亚大学洛杉矶分校和康乃尔大学任计算机科学教授。

Mercury 效果如何?我们先看一个官方 Demo:
视频显示,一位用户想要学习西班牙语。请求 Mercury 教他一些常见的问候语及其含义。几乎一眨眼的功夫,Mercury 就给出了一些常见的西班牙语问候语及其含义,速度确实非常快。
一直以来,扩散模型是图像生成和视频生成的主流方法。然而,扩散模型在离散数据上的应用,特别是在语言领域,仍然仅限于小规模的实验。与经典的自回归模型相比,扩散模型的优势在于其能够进行并行生成,这不仅可以大幅提高生成速度,还能提供更精细的控制、推理能力和多模态数据处理能力。
然而,将扩散模型扩展到现代 LLMs 的规模,同时保持高性能,仍然是一个未解决的挑战。
Mercury 就是为此诞生的,其是首个基于扩散模型的 LLM。与自回归(AR)模型相比,Mercury 模型在性能和效率上都达到了最先进的水平。
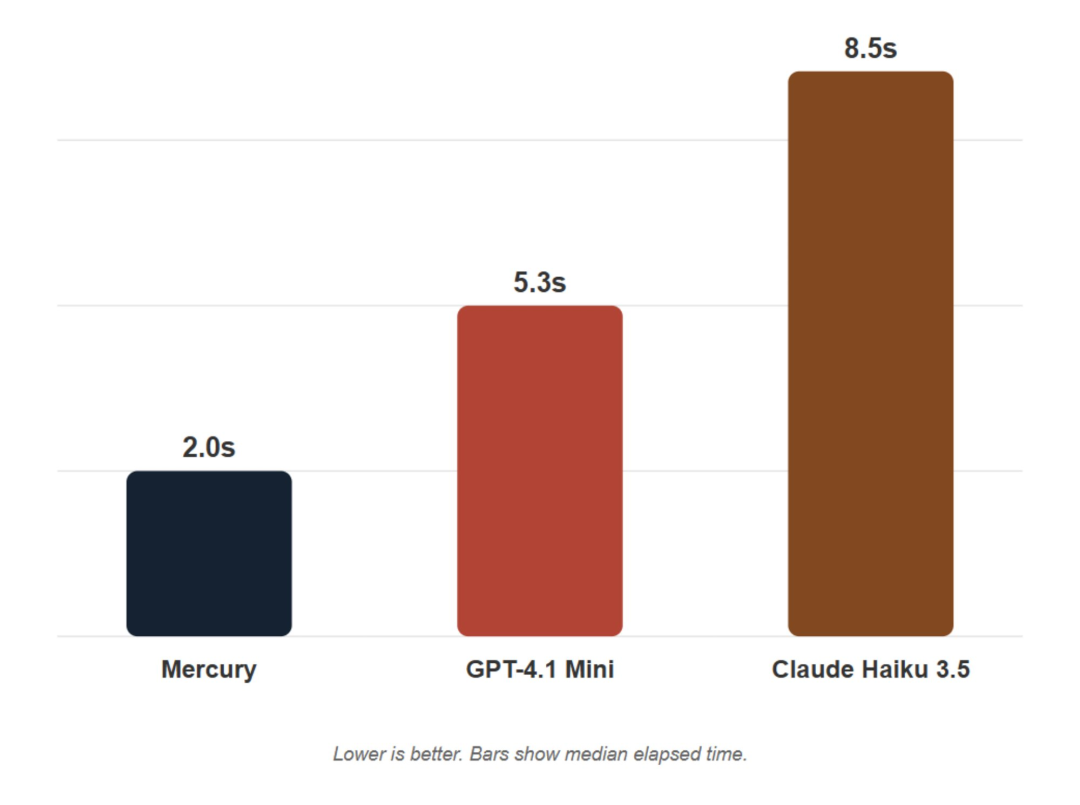
在性能表现上,根据第三方测评机构 Artificial Anlys 的基准测试数据显示,Mercury 可媲美 GPT-4.1 Nano 和 Claude 3.5 Haiku 等速度经过优化的前沿模型,同时运行速度提升超过 7 倍。
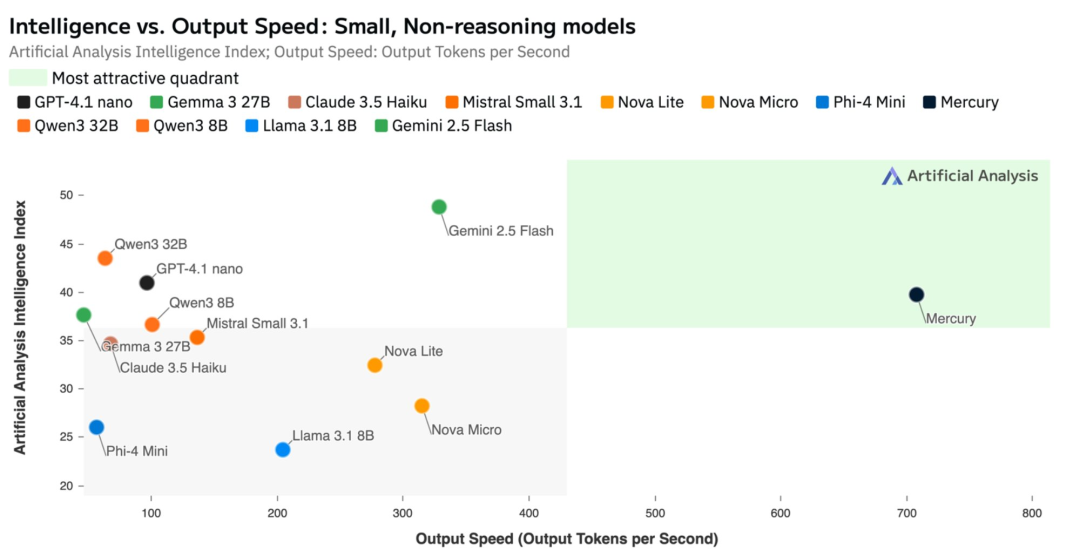
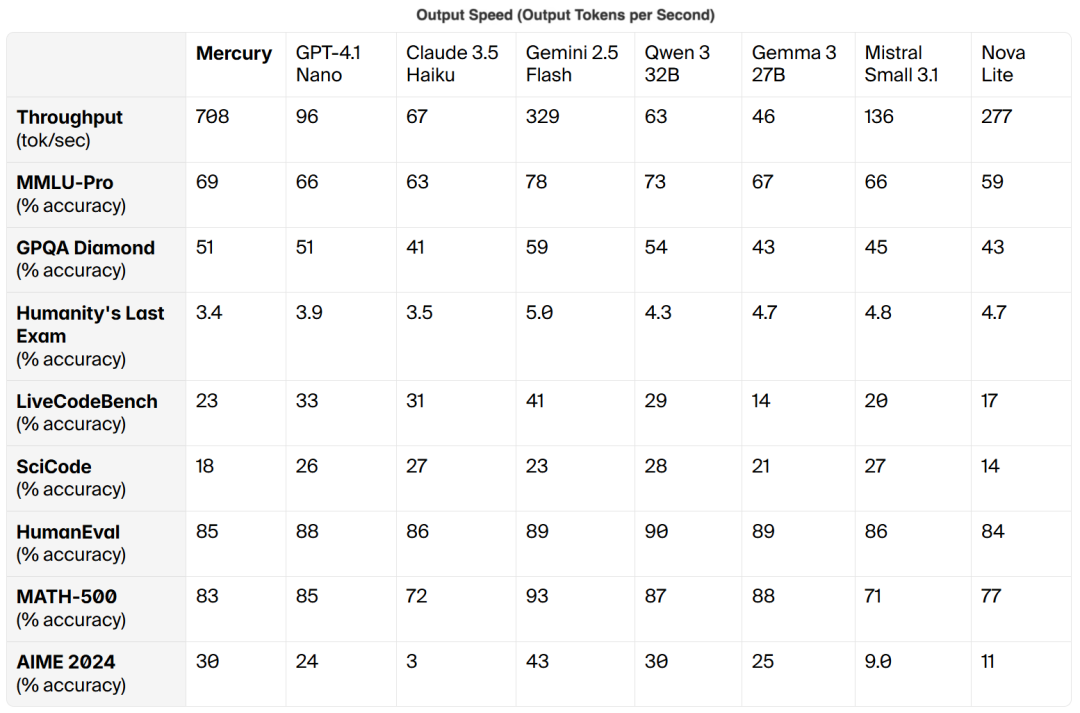
在其他场景下,Mercury 也展现出超强的能力。
首先在实时语音方面。Mercury 凭借其低延迟特性,能够为各类实时语音应用提供支持,包括翻译服务和呼叫中心代理等场景。在实际语音指令测试中,基于标准 NVIDIA 硬件运行的 Mercury,其延迟表现优于在 Cerebras 系统上运行的 Llama 3.3 70B 大模型。
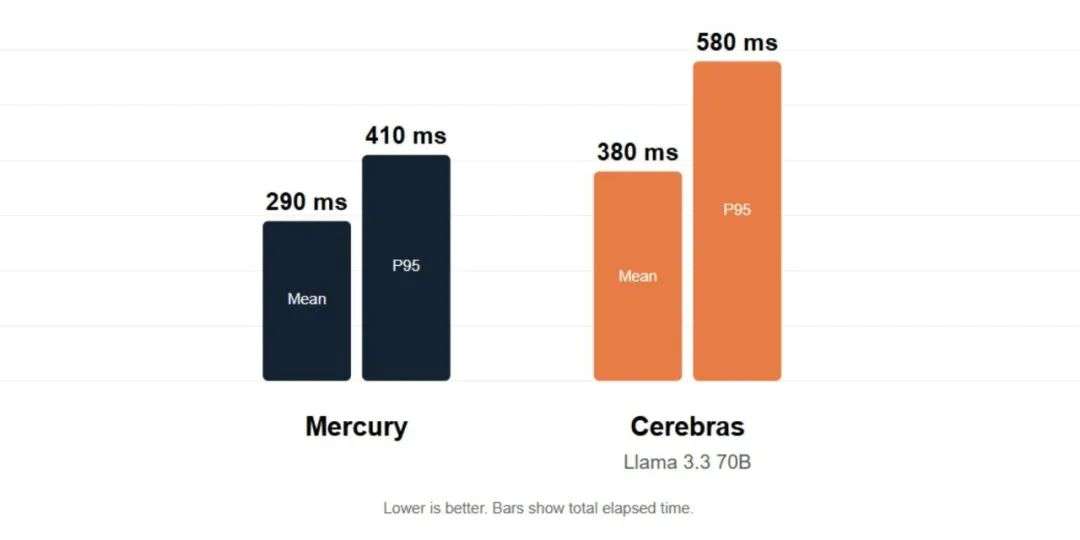
其次是可交互性。Mercury 是微软 NLWeb 项目的合作伙伴。与 Mercury 结合使用时,NLWeb 能够提供闪电般快速、自然的对话。与其他注重速度的模型(例如 GPT-4.1 Mini 和 Claude 3.5 Haiku)相比,Mercury 的运行速度更快,确保了流畅的用户体验。
与此同时,Inception Labs 还发布了 Mercury 技术报告,感兴趣的读者可以前去了解更多内容。

我们不难看出,Mercury 是迈向基于扩散语言建模未来的下一步,它将用极其快速和强大的 dLLM 取代当前一代的自回归模型。
既然 Mercury 主打速度快,效率高,那么真实体验效果如何呢?机器之心上手体验了一把。
首先测试一下 Mercury 的推理能力,两个经典的问题「9.11 和 9.9 哪个大」「"Strawberry" 中有几个字母 'r'?」都回答正确。
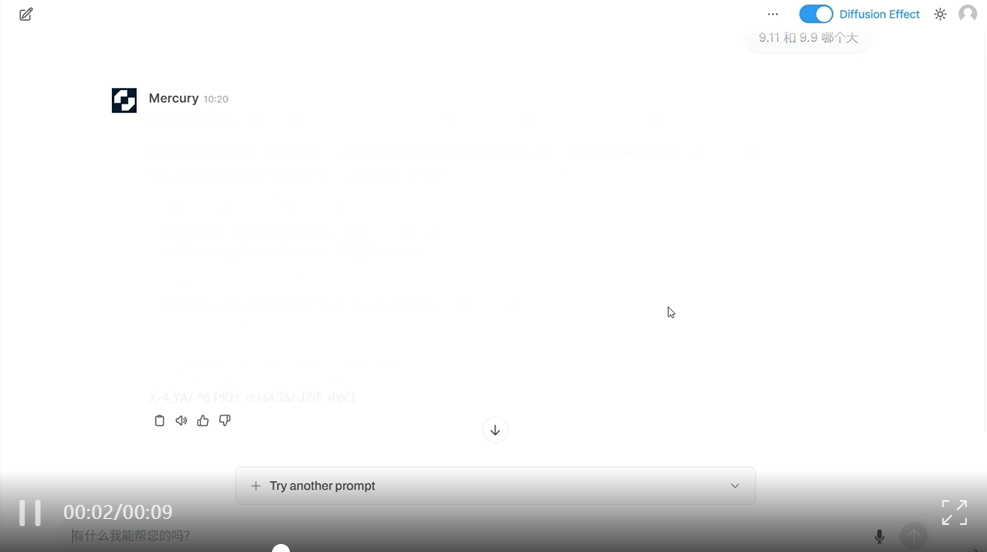
但在「红绿色盲女孩的父亲为什么崩溃」这个问题上败下阵来。
接下来我们测试一下代码能力,我们用 Mercury、Gemini 2.5 Flash、GPT 4.1 mini 生成同一个脚本任务,看看他们表现有什么区别。
「 生成一个 1000 字的 TypeScript 游戏脚本,包括角色类、攻击逻辑、敌人 AI、UI 模块初始化。 」
Mercury 生成过程:
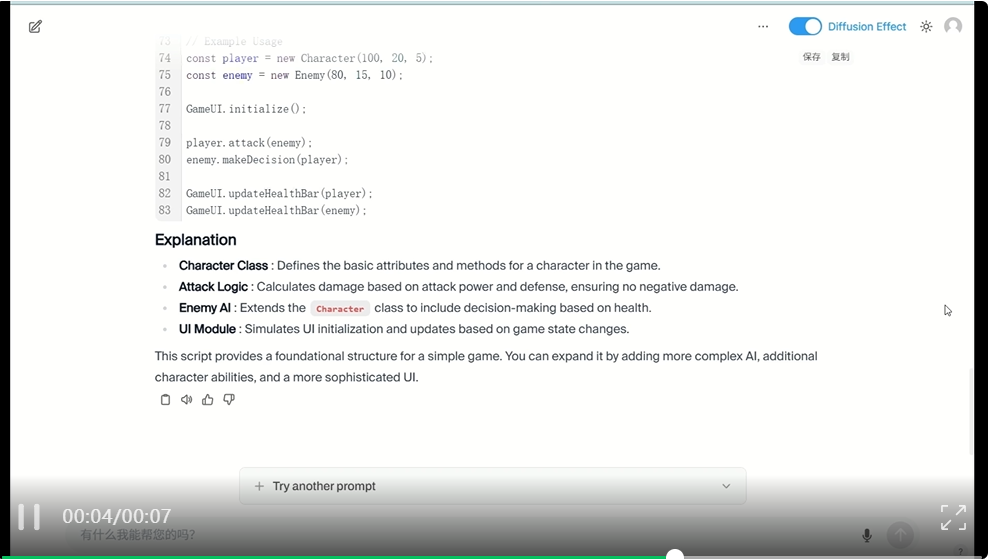
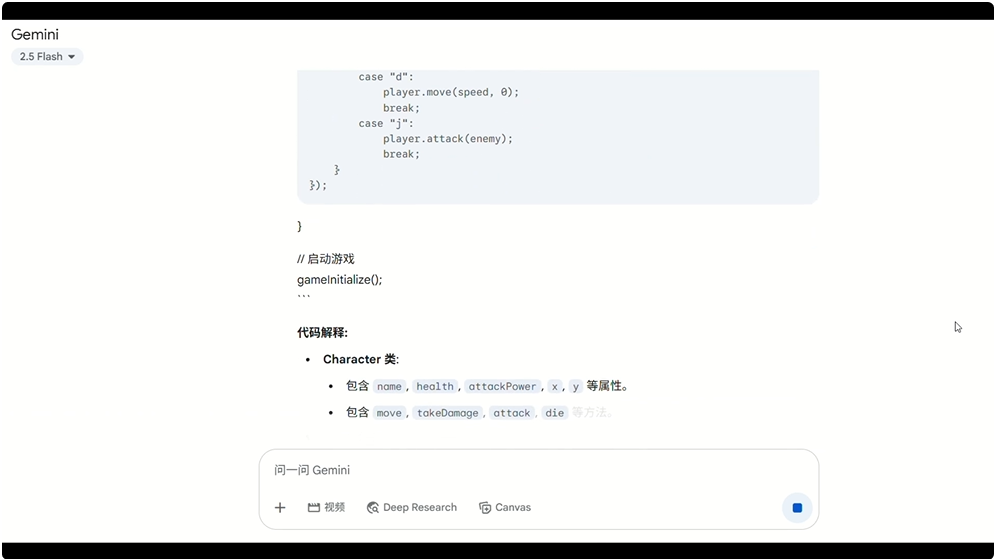
Gemini 2.5 Flash 生成过程:
GPT 4.1 mini 生成过程:
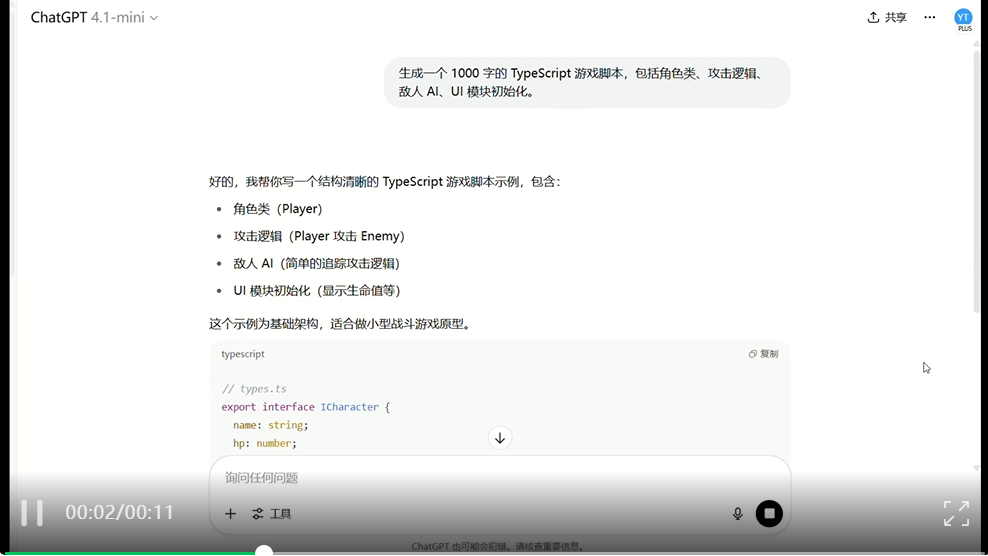
可以看到,Mercury 确实生成速度非常快,在短暂几秒停顿后,大量文本同时出现,任务完成仅仅用时几秒,而 Gemini 和 GPT 生成的文字像打字机一样一个接一个地流出,总耗时较长。
再来检查一下生成质量怎么样,这里邀请 GPT o3 作为评委老师。
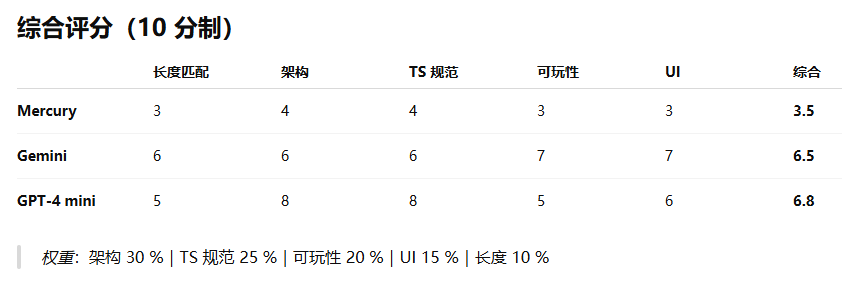
可以看到,虽然 Mercury 生成速度很快,但生成质量还有待提高。
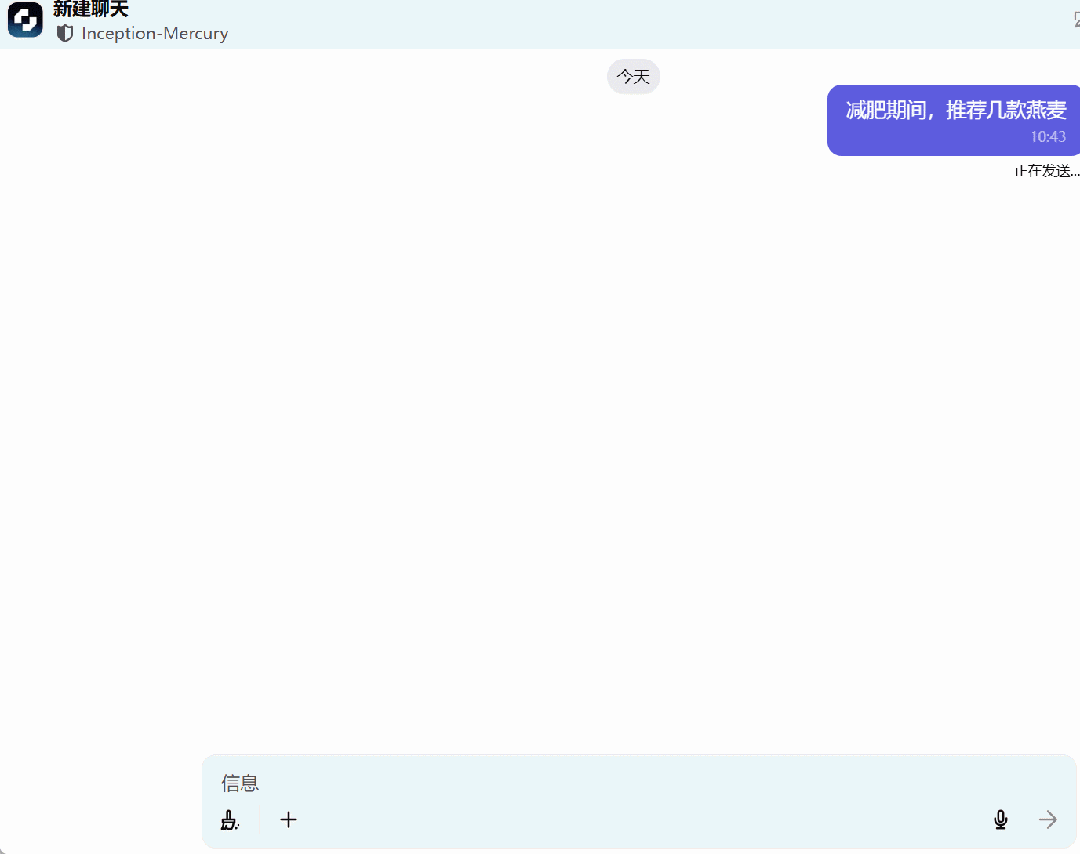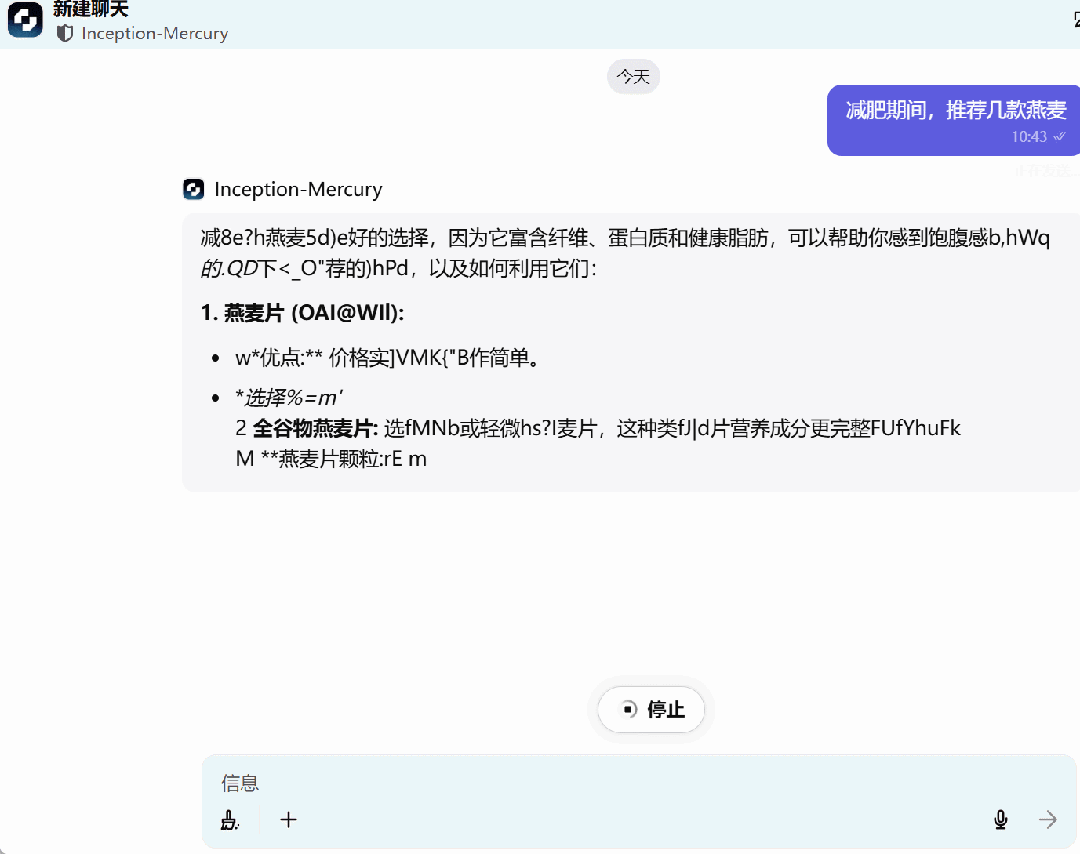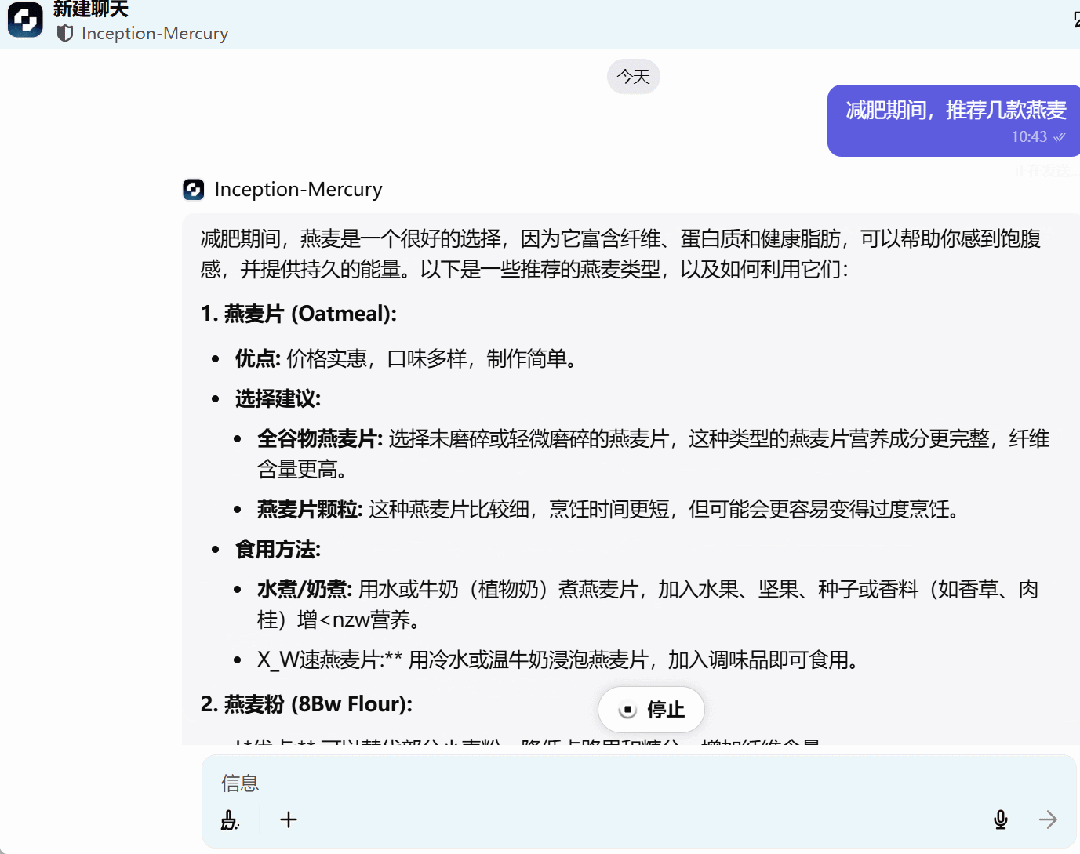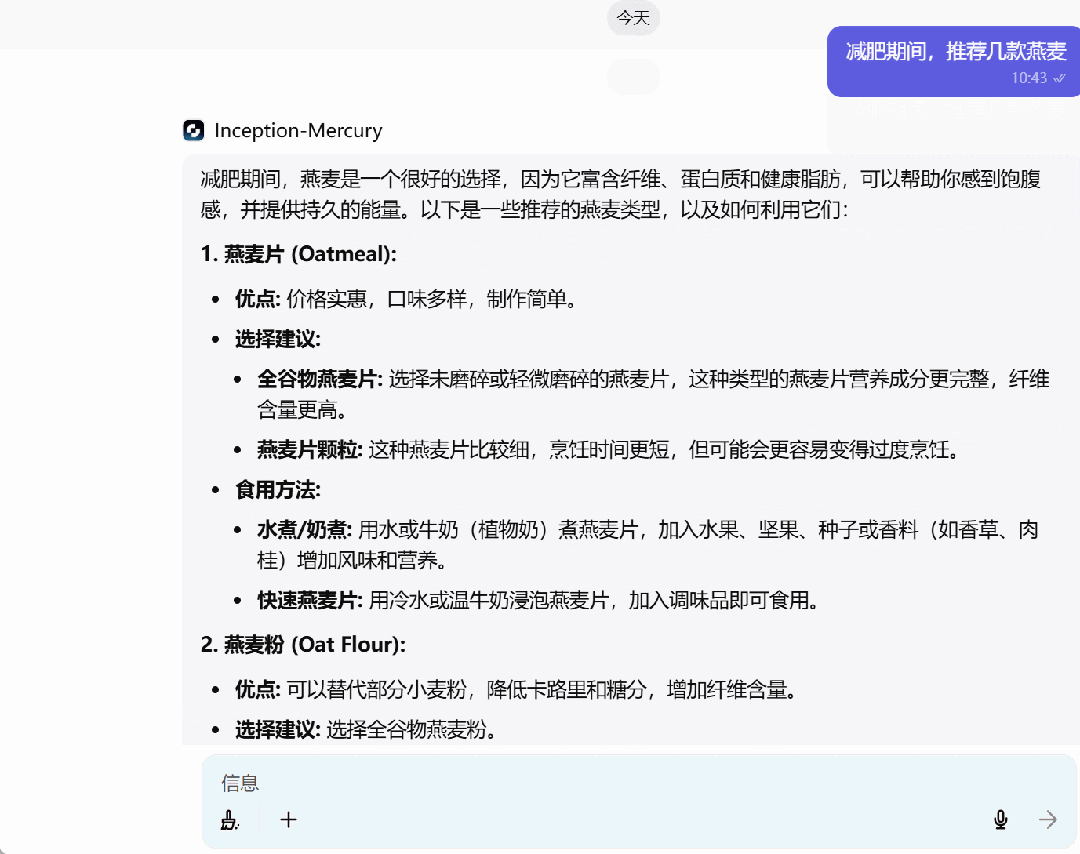
最后,我们还问了 Mercury 一些日常问题,回答速度非常快。
还没体验的小伙伴,可以去试一试了。
文章来自于微信公众号“机器之心”。


【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
