# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
6月27日,“正和岛2025案例共学年会暨AI+先行者创新大集”在合肥继续进行,本次大会以“向新力”为主题,千余位企业家共同探讨AI时代下的组织变革与商业格局。
在大会上,科大讯飞董事长刘庆峰以《解放生产力释放想象力——通用人工智能技术进展及典型应用》为题,做了一场精彩的演讲。
在分享中,刘庆峰预判今年是全民AI和全行业AI的元年。面对美国对中国高端算力芯片的限制,中美在本轮大模型竞争中差距缩短至3到6个月,不会再形成代差。他认为国产自主可控比以往任何时候都更加迫切,我们必须坚定地在国产化平台上发展通用人工智能。
以下是刘庆峰在正和岛案例共学年会上的演讲全文,以飨读者,内容有删减。
口述:刘庆峰科大讯飞董事长
大模型在高考中的表现
我想跟大家聊一下关于人工智能,尤其是以大模型为代表的通用人工智能技术的最新发展和应用。
现在,人工智能的应用正在深刻地解放着千行百业的生产力,让人们更有时间去做更有想象力、更有意思的事情。
今天,大家都太忙、太辛苦了,各行各业如何借助人工智能技术,从这种无比紧张、过度饱满的工作中,释放出来,去做更有意义的事情,畅想更好的未来,这正是我们在2023年5月6日发布科大讯飞星火1.0时所秉持的基本理念。
如今,大家用人工智能各展所长,做自己最擅长的事情,而科大讯飞的理念始终如一,那就是希望通过人工智能技术的发展,真正解放生产力,释放想象力。
这个技术进步的怎么样?人工智能大模型在高考中的表现备受关注。这两日,高考成绩公布,这是莘莘学子历经十年寒窗苦读,第一次迎来人生最大时刻。语文考试一结束、作文揭秘时,上海报业集团旗下的界面新闻马上邀请了两位有高考经验的资深特级教师,对国内六家主流大模型进行高考作文评比,包括DeepSeek、豆包、文心一言、通义千问、腾讯元宝。
其中讯飞星火有幸得了第一名,作文满分60分,我们拿下了53分。在高考英语方面,6月9日作文题目公布后,新京报率先组织了评测,满分20分的情况下,讯飞星火得了19.5分。
首届供应链博览会,李强总理见到我时,第一句话就是:我们中国人做大模型,不能只在写诗作画等传统文化上还不错,自然科学领域到底怎么样?这才是国家真正需要的。
讯飞星火在数学的表现如何呢?6月8日高考数学卷一揭晓,IT之家便组织了6家主流大模型以及美国最新推出的OpenAI-O3进行测试。
OpenAI-O3的核心优势是在数学、科学、代码等方面有很大突破。而在今年高考数学一卷满分150分的测试中,7家模型里,讯飞星火和DeepSeek分别突破140分。
讯飞星火是4月20日的版本,DeepSeek是5月28日发布的,再加上DeepSeek没有多模态,而讯飞星火具备多模态能力,能通过OCR直接做数学题目,这很棒。
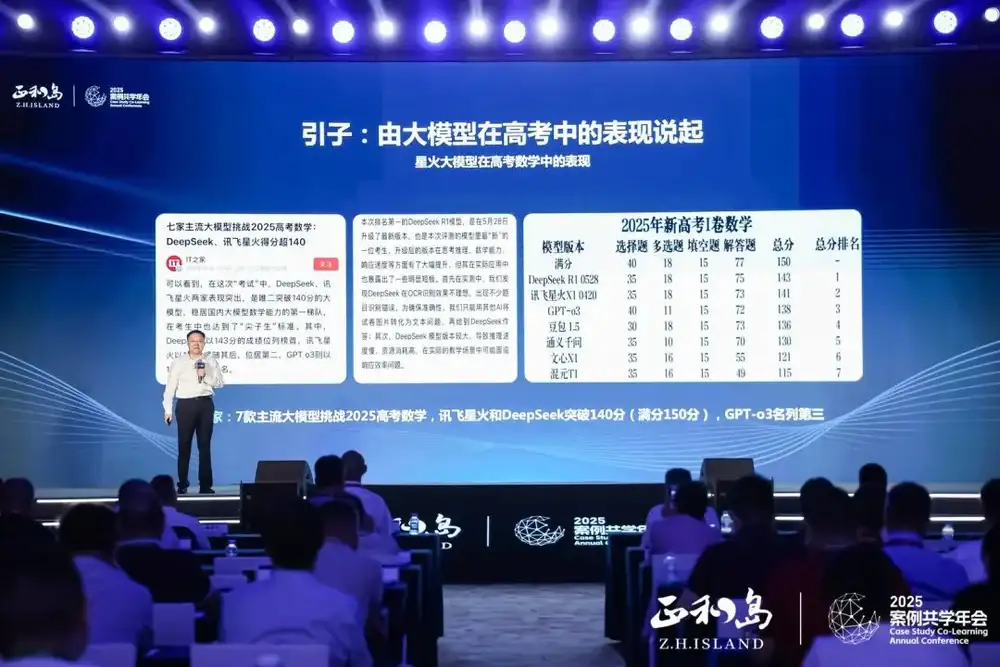
这次评测中,我们可以看到当前大模型做理科的能力水平,而且高考数学题目一定要专门封闭命题,不可能提前做训练,因此它完全展示了大模型对数理逻辑推理的表现。不仅在高考数学,在国外奥数、美国各类竞赛以及英语、数学、物理等科目上,国内大模型的表现都非常优秀。
今天,我们对大模型的期望不仅仅是高考考得好,讯飞做教育,希望通过大模型技术让试卷批改得更精准,为孩子提供更精准的学习资源推荐,让孩子们学得更愉快,心理更健康,它要做的是能够帮助我们构建更美好的未来。
过去同时期,它的数学最高分不到110分,一年之内进步明显,估计明年能接近满分。按照目前进度,预计两年内大模型的水平将超过诺贝尔奖级别。实际上,去年诺贝尔物理学奖、化学奖都给了AI4S(从事人工智能与科学交叉研究)的科学家们。
今年是全民AI元年
今天,AI到底发展到了什么阶段?
先来看一组数据。去年,人工智能领域的创业投资总额超过了1000亿美元,这还不包括英伟达、微软、谷歌等巨头的大规模投资布局,同比增长了80%。在全球经济发展不确定性的背景下,这个增长速度很快。
在中国,算力规模已经达到72.53万匹,增长了74%。大模型的公开招投标增长了十几倍。去年春节前,我国生成式人工智能的规模已经达到了2.49亿,占总人口的17.7%。
从技术发展的角度来看,大模型的应用已经到达了一个关键阶段。杰弗里·摩尔的《跨越鸿沟》,每次重读都会非常有启发,这本书直到现在还被硅谷奉为创业的经典教材。一个新技术出来,早期创新者占总人数2.5%,而有远见的长线者、极客主义者占13.5%。当这两波人跨越之后,就进入了实用主义用户阶段。
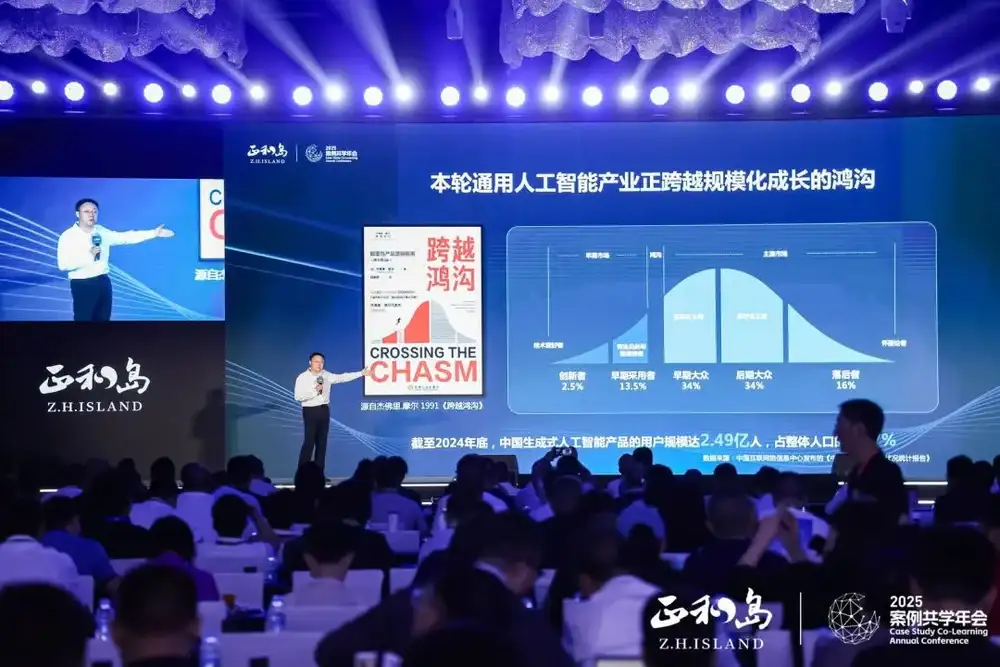
这种跨越鸿沟为什么一定是16%的统计概率?16%代表在人群中相互影响到了一定的浓度,每一桌吃饭8~10人中,总有一个人在用新技术,他会感染周围的人。无论从语音识别技术,手写识别等新技术的发展过程中,都经历了这样的阶段。如今,大模型的应用也基本达到了这一状态。
2025年将是全民AI和全行业AI的元年,大家或多或少都下载过大模型的各种应用,知道它能做什么,理解它对生活和生产带来的变革。
大模型是人工智能在通用人工智能发展的一个非常标志性的成果,大致可以分成几个维度:
一是运算智能。机器能存会算,这是支撑认知智能发展的基础;
二是感知智能。机器能听会说、能看会认。语音识别技术已经超过专业速记员;语音合成技术可以给中央电视台配音;机器翻译超过了99%的大学六级考生,已经通过国家翻译师资格考试。人类看不见的红外、紫外,听不见的超声、次声波,机器全都能感知到。
三是认知智能。科大讯飞在2017年新一代人工智能规划出台之后,承建了中国唯一的认知智能国家重点实验室。随着认知智能在多模态、具身智能等领域的进步,运动智能也相互呼应,推动了机器人行业的快速发展。未来,懂知识、能进化、能陪伴、善学习的机器人将进入到亿万家庭,进一步推动认知智能的极大进步。

从技术角度看,大模型的发展经历了几个阶段:2017年,生成式预训练方法推出;2018年就有了GPT1.0,这种预训练的方法,强化学习的出现使得机器在数学考试中的得分从100分左右提高到140分;之后,技术从强化学习、慢思考进入到世界模型发展,更真实地理解客观世界,所以技术在不断快速发展。
在发展过程中,讯飞的语音合成技术不仅为中央电视台配音,还支持80多种语言翻译,覆盖200多个国家和地区,这些系统参数在几百万到2000万之间。
大模型是什么概念?GPT刚推出来时,是1750亿的浮点参数,这种超大规模的深度神经网络,一般都是千亿以上参数,再用海量多元多模态的文本、视频、语音等各种数据送进去训练,在一定程度上,让机器具备跨领域的智慧涌现。其核心能力包括文本生成、语言理解、知识问答、逻辑推理、数学能力、代码能力以及多模态能力等七个维度。
2023年,长三角人工智能产业链联盟和中科院人工智能产学研联盟联合设计通用人工智能的评测体系和技术维度,对七大维度给出400多项细分任务类型,今天已扩展至1000余项细分任务。
而这些能力就会带来专家级的虚拟助手,颠覆传统的编程方式,成为科研加速器,颠覆整个科研范式以及改变信息分发、获取、内容生产和人机交互的模式。
中美AI大模型差距,缩短至3到6个月
中国的高考只是观察人工智能发展的一个切面。在国际上,如国外的奥数等赛事中,人工智能的应用也十分广泛。不过,从整体技术发展情况来看,在本轮以GPT框架预训练到强化学习为代表的大模型竞争中,中美之间的差距正在不断缩短。
美国如OpenAI、Anthropic等头部公司慢慢聚焦,把那些数学、物理等领域的天才们,培养成人工智能研究专家,所以在科学模型的构建上,美国独树一帜。
中国也挺卷,“百模大战”卷到头部企业最多只剩下5~10家。去年9月13日,OpenAI推出深度思考模型,在做数学、深度推理上大幅度提升。今年1月,我们推出非常小的13B深度推理模型,由于算力限制,我们必须研发很小的模型,国产算力才能支撑得住。
此后,DeepSeek、豆包、阿里等企业一路你追我赶,在通用大模型这一波竞争中,中美两国的实力已经非常接近,差距仅在3到6个月之间,绝对不会再形成代差。
在此背景下,美国对我们限制了什么?当DeepSeek一出来,美国非常震惊。因为此前他们集体对中国大模型和科技创新能力有误判,突然看到,中国发展速度离美国这么近,所以美国进一步加大对算力的限制。
2022年10月7日起,美国对支撑我们大模型和人工智能芯片限高限宽。限高是指单芯片算力不能超过312T;限宽是指大模型数据交换带宽不能超过400G。后来,美国又进一步宣布全面禁售,连阉割版的芯片都不给了。
今年美国的新规定是,所有出口管制扩展到了三星、台积电等芯片代工厂十几纳米芯片的出口管控,之前我们可以用堆叠工艺变成7纳米,现在这些路径全部被堵死了。
在这样的限制下,中国大模型和人工智能基础设施上,与美国差距仅在3到6个月之间,但我们的算力支撑到底怎样?我想告诉大家,刚才说到的高考语文、英语和数学的主流模型中,只有讯飞一家是基于国产算力训练的。而DeepSeek和豆包等企业全是基于英伟达芯片训练的,国产算力训练大模型压力非常大。
2022年11月30日ChatGPT推出时,美国对中国的芯片限制已经限高限宽,华为的910B芯片算力为113T,与美国的基本一致,带宽规定不能超过400G,而中国实际为392G。
理论上,中国应该能达到A100或A800芯片80%到90%的性能。可那时候,同样的硬件技术下,我们在训练大模型的效率上只有30%。
任正非在华为组建了有史以来最高规格的特战队,到2023年10月,我们联手把训练效率做到95%。因此,2024年1月30日,我们推出了第一个基于国产算力训练的中国千亿大模型——讯飞星火3.5,为国家兜了底。
去年9月13日,DeepSeek R1深度思考模型的技术很出圈,由于我们有很多积累和基础,仅用一个月时间,我们就复现了所有技术。
但当我们使用国产算力训练时,原本在原有算法中达到95%的效率却降到了25%,我们又花了三个多月的时间,将效率提升到了73%。在高考中,这一技术得到了验证。今天中国的大模型训练一定是在全国产算力的基础上,用更少的算力、更小的模型参数,训练出与全球对标的技术,我们才有可持续发展的底气。
为什么能做到?我们的模型是70B,如果一个岛亲机构要用满血版的R1,需要两张卡,而如果要深度训练,R1无法做到,你要自己用开源模型训练,这可能需要512张卡。而我们使用星火X1,32张卡就可以了。OpenAI O1的规模更大,可能要上万张卡。能做到这一点,是因为中国有自己的算法创新。
快思考是迅速给出答案,而慢思考通过深度推理反复验算,给出最好的模型。但V3和R1是分别单独训练的,一个企业要安装两套系统。我们在国内率先使用一个框架,企业装一套系统,可以自由切换快思考和慢思考模式,想用快的用快的,想用慢的用慢的。
正因为有这些技术创新,才使我们能够在自主可控的通用底座上快速训练出行业模型,从而进入到企业场景。通常,一个新技术的规模化应用的技术门槛要达到89%到90%的准确率。
例如,手写识别在摩托罗拉做到89%后,所有人开始用手写识别;语音识别在手机上的识别准确率达到90%后,用户数量从几十万增长到上亿,如今其准确率已达到98%。
大模型的典型应用场景
今天,通用大模型在初步使用中常出现幻觉问题,有很多“讨好型人格”特征,平均准确率约78%左右。相比之下,行业模型经过精准训练后,准确率可达80%以上,场景定义清晰,准确率能达到95%。
这个基本框架下,前提是什么?我们是否有全自助可控的平台上训练出自己的底座模型。比如教育,因为有自主可控的模型,可以把机器的思维链转化为教师的教学思维链,以问题导向,打造中小学教师助手,这些性能指标明显优于GPT4.5。
在医疗领域,我们的大模型已通过国家职业医师资格考试,超过了99%的考试学生,我们与葛均波院士合作的心内科应用,以及与安徽医科大学校长翁建平教授合作的糖尿病专业应用,均已达到超越主治医师水平的成效。随着深度推理技术的出现,今年的大模型在多个专科领域实现了顶级水平的突破,就是因为有了一种快速的行业训练工具链。
今年两会后,最高人民检察院引入人工智能技术,用大模型来推动司法的公正,做类案推送、法条对应、辅助量刑和文书生成等十项能力,我们用专业模型,准确率能提升到83%,很多领域超过90%。前两天,工信部在能源领域的碳排放评估测试中,大模型在48名考生中位列第五,跻身前20%。
这些技术进步推动了大模型在多个领域的广泛应用。
在教育领域,大模型可担任口语、科学、编程教师及心理辅导员。在医疗领域,已支持近4亿次电子病历和10亿次辅助诊断,纠正了170万次不合理诊断和9000多万次不合理处方,并致力于个人健康助手的开发。在翻译领域,大模型在大学六级考试中超越99%的考生,其应用场景从旅游扩展到商务谈判和合同签订支持,尤其在抗噪、远距离交互、离线翻译和专业领域表现出色。
此外,我们还开发了图片文案生成和视频制作工具,支持多国语言,助力农产品和工业产品出海。
与岛亲出海相关的,比如在翻译领域,大模型在大学六级考试中超越99%的考生,今天翻译机主要变化是,不再是出国旅游、聊天、点菜之类的,还支持商务谈判和合同签订,离线状态下,英语、俄罗斯语、法语、德语等都有。
一个增长较快的场景是,中国企业出海建厂,在工厂有噪声环境下可以抗噪,并支持远距离交互,这是非常大的突破。此外,我们还开发了一些工具,无论是农产品出海,还是工业产品出海,给出几张图片、一个要求,可以直接生成文案或视频,同时配上所需要的任何国家的语言。
我们发布了业界第一个同传大模型,自己录一段中文,可以自动生成各国语言,且跟视频文本、手势都要对齐。今年,东盟博览会上正式发布面向东盟电商的自动翻译支持平台。
在办公领域,打造每个人的办公助手。今天会议,如果拿着讯飞办公本,可以全程录音,并自动转写成文字,自动生成会议纪要和代办事项。这个软件到了什么程度?今年总用户数过了9000万。即便是三五个人的小型会议,用手机录到后台,也能马上提炼每个人的观点,并形成综合结论。
此外,我们与中国移动合作,大家经常在开车或走路时,接到领导的工作电话,申请这个功能后,电话一挂断,会议纪要就出来了,这些功能大家都很欢迎。
在工业领域,今天大模型能支持研产供销服管几乎每个环节,我们通过前端的麦克风阵列和语音芯片、视频芯片,让所有设备“能听会说、能看会认”,再结合后端的大模型,实现设备“能理解、会思考”。
在家电领域,第一个大模型招标的是海尔,我们中标了,其后又与TCL、美的等家电企业积极合作。2022年,我们在家电行业的芯片出货量达到1300多万片,2024年增至4000多万片,预计今年将突破6000万片。
人机物万物智能互联时代正在到来。在这个基础上,无论是产业数字化还是数字产业化,其实都需要用代码来连接现实世界和虚拟世界,今天用软件来大幅提效,已经成为行业共识。
今年计算机和软件专业首次出现就业率和工资下滑的情况,OpenAI说ChatGPT已经通过了Google二级程序员测试,这个岗位年薪18万美金,这是代码的进步。
再举几个例子,讯飞内部的智慧黑板、智慧课堂产品,从Windows系统迁移到Linux系统需要三个月的开发周期,现在一个月就搞定了。
这种效率的提升,不仅加快了软件开发的速度,还降低了技术门槛,使得每一个不会用编程、不懂技术的员工,只需要洞察岗位需求,直接下指令,能让模型帮你完成相应的工作,从而创造一个又一个智能体,极大地丰富了创新创造的可能性,不再受限于技术门槛,关键在于我们是否有想象力。
在招投标系统中,利用人工智能技术,不再只是简单写一篇文章,好玩有趣,还可以精准解读非常严肃的标书,读懂标书的关键要求和评标方法,然后自动检测标书是否存在造假或雷同问题,并提出自动替换建议、查找预警信息,甚至生成砍价建议。最近国家发改委决定全国推广,在合肥市招投标中心的实践中,大模型将专家评审一致性从75%提升到95%。
今天,大模型的应用场景非常多,然而,最重要的是要将通用大模型成功转化为行业模型并实现落地,需要解决一系列关键问题。
例如,一定要知道怎么建算力,是利用国产平台又或是结合国产和英伟达的混合算力调度平台。又怎么整理数据,用自动化工具,效率提升至24倍。怎么训模型,企业是用一个小的几千万参数的模型,还是要用大模型上千亿参数,这要根据实际情况做专门的对应,落到场景里,保证安全。最后,用看得见、摸得着的场景和统计数据,证明大模型应用的实际效果。
我们只要告诉智能体一段话或一句话,智能体会把这个事情分解成多个任务,找到需要调用的工具,并查找所需内容,然后把每一个完成的任务完串在一起,最终完成整体目标,这叫智能体。
以中石油为例,5000多名员工参与岗位提升大赛,1000多支队伍开发了2000多个智能体,其中100多个获奖。目前,这些智能体在中石油的100多个办公应用和300多个生产和销售过程中产生了实实在在的效果。
今天大模型时代,绝不是单个企业的竞争,而是整个生态体系的繁荣,要让我们的技术给到更多的企业应用,要让更多的创新者去开发。
在讯飞人工智能平台上,去年一年新增了170万开发者团队,做出来近100万新应用。这中间最大特点是,以前的应用大部分是以社交、娱乐为主的APP,现在54%的应用与工业相关。
中国大模型在这一波红利中,与美国的差距已缩小至3到6个月,在行业应用的红利,中国一定会更率先拿到。
作为产业的开发者和创新者,我们需关注源头技术创新,与美国的差距越来越近更理性地看,这是原创与追赶的差距,我们在学习它,它是原创。如果我们不能从源头基础上对人工智能进行更长远的布局,未来很难最终胜出。
前天我们在讨论合肥这座城市的特点,这座城市正在布局GPT框架人工智能计算方法,怎么与量子计算深度结合,从而彻底解决算力焦虑问题。又怎么利用人工智能助力可控核聚变技术,将原本需要10天的模拟试验缩短至1天,准确率从93%提升至97%。如果可控核聚变技术,能输入1度电产生超过1度电,实现能量正输出时,将彻底解决能源问题。
我们期待跟大家一道,在正和岛年度大会上深入交流,共同面向未来,解放生产力,释放想象力。谢谢大家!
文章来自公众号“正和岛”,作者“刘庆峰”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
