# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最少只用2张图,AI就能像人类一样理解3D空间了。
ICCV 2025最新中稿的LangScene-X:
以全新的生成式框架,仅用稀疏视图(最少只用2张图像)就能构建可泛化的3D语言嵌入场景,对比传统方法如NeRF,通常需要20个视角。
团队一举攻克传统方法依赖密集视图的痛点,更将多模态信息统一在单一模型中,为空间智能领域打开了新大门。
这意味着,生成式模型能像人类一样,仅凭稀疏视觉输入构建融合语言理解的3D空间认知系统。

当前3D语言场景生成有以下3个核心困境:
密集视图依赖与稀疏输入缺失的矛盾
传统方法(如NeRF、Gaussian Splatting)高度依赖校准后的密集视图(通常超过20个视角),当输入视图稀疏(如仅2-3张图像)时,会出现严重的3D结构伪影和语义合成失真。例如,LangSplat和LangSurf在厨房场景中使用稀疏视图时,物体边界模糊率超过40%,而真实场景中获取密集视图往往成本高昂。
跨模态信息割裂与3D一致性缺失
外观、几何、语义三类信息通常由独立模块处理,导致模态间语义错位。现有视频扩散模型仅能生成单一模态,当需要同步生成法线和语义时,会出现物体表面法线与颜色不匹配等问题,在ScanNet测试中,传统方法的法线与RGB一致性误差平均达27.3°。
语言特征高维压缩与泛化能力的瓶颈
CLIP生成的512维语言特征直接嵌入3D场景时内存占用极高,且现有压缩方法需逐场景训练,无法跨场景泛化。例如,OpenGaussian在切换场景时文本查询准确率下降58%,严重限制实际应用。
TriMap视频扩散模型:稀疏输入下的多模态统一生成
四阶段渐进训练:先通过大规模网络数据训练关键帧插值能力,再用10K级3D一致视频数据学习几何一致性,接着注入法线和语义监督,最终实现RGB、法线、语义图的协同生成。该策略使模型在仅2张输入图像时,生成的法线与RGB一致性误差降至8.1°,语义掩码边界准确率提升63%。
层级化语义生成:利用视频扩散泛化能力,生成小(s)、中(m)、大(l)三种粒度语义掩码,例如在Teatime场景中可精准定位“红色马克杯”并区分细节。
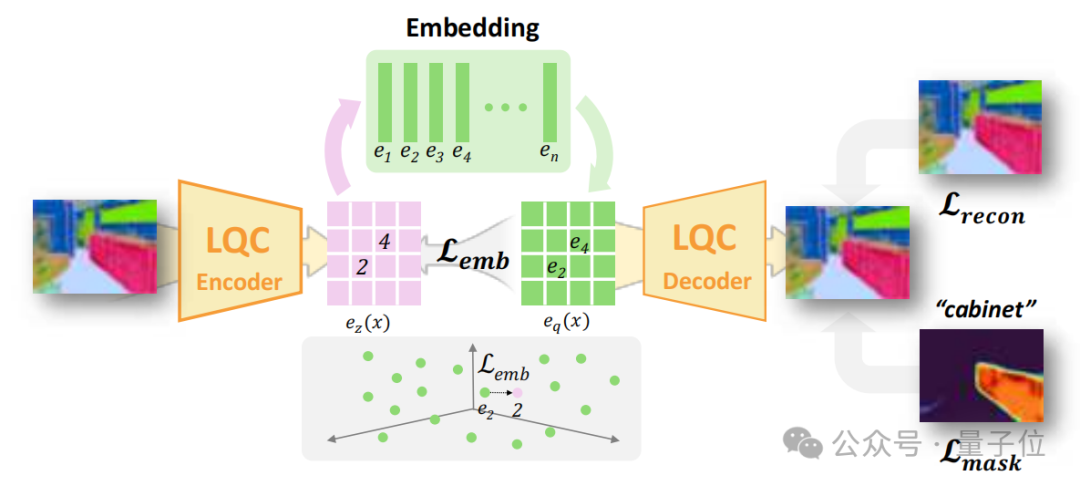
语言量化压缩器(LQC):高维特征压缩的泛化革命
向量量化+梯度桥接:通过可学习的嵌入表,将高维CLIP特征映射为3维离散索引,压缩后特征L2重建误差仅0.0001,较传统自编码器降低90%。
跨场景语义锚定:在COCO数据集预训练的LQC无需微调即可跨场景迁移,文本激活图边界锐利度比LangSplat提升2.3倍。
语言嵌入表面场:3D空间的语义-几何联合优化
渐进法线正则化:先通过DUSt3R初始化点云,再用生成的法线图分阶段优化几何表示,自动过滤不可靠区域,使3D表面重建误差大幅降低。
2D/3D聚类监督:通过语义损失和特征分布对齐,强制语言高斯紧密附着在物体表面。例如,“冰箱”查询中激活区域与真实表面重合度达91.7%,远超LangSurf的65.3%。
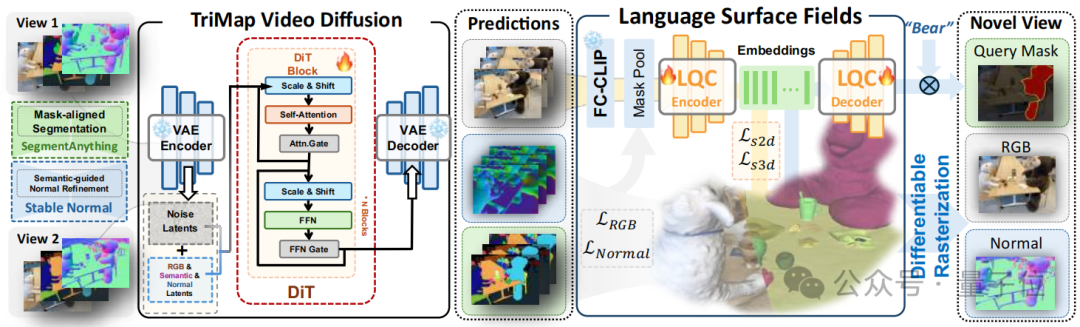
统一模型:单模型统合多模态,告别“模块化”低效
传统3D重建往往需要分别处理外观、几何和语义信息,不仅流程繁琐,还难以保证跨模态一致性。LangScene-X创新性地提出TriMap视频扩散模型,通过渐进式多任务训练策略,一次性生成RGB图像、法线图和语义分割图,将三大模态信息无缝整合。
这种“大一统”架构不仅省去多模型协同的复杂流程,更通过视频扩散的强生成先验,确保了生成内容在3D空间中的一致性,精准补全重建中看不见的视角。
搭配语言量化压缩器(LQC),LangScene-X还解决了高维语言特征压缩的难题。无需针对每个场景单独训练,就能将512维的CLIP特征高效编码为低维离散索引,在减少内存开销的同时,保持语言特征的本质属性,真正实现跨场景的泛化能力。
空间智能:让机器像人类一样“理解”3D世界
LangScene-X还通过语言嵌入表面场技术,将文本prompt与3D场景表面精准对齐。比如在“Teatime”场景中输入“stuffed bear”,模型会生成聚焦相关区域的关联图,真正实现用自然语言直接查询3D场景中的物体。
这种能力源于对空间智能的独特设计:模型从稀疏视图中提取多模态知识,再通过语义引导的法线优化和2D/3D聚类损失,将语言信息牢固锚定在3D空间中。
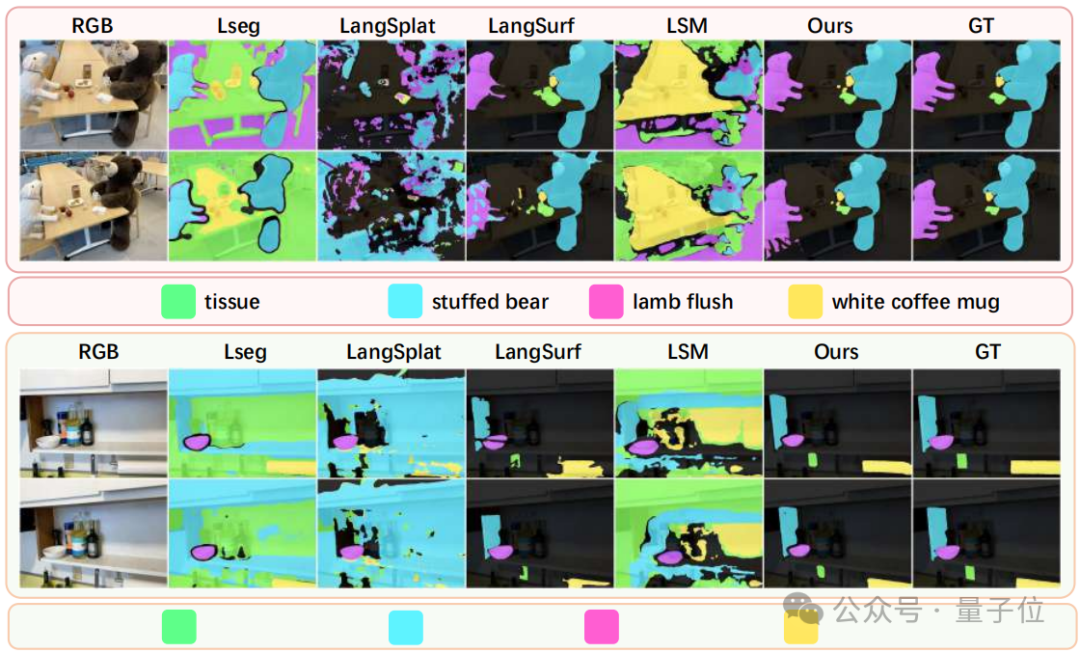
实验显示,在LERF-OVS和ScanNet数据集上,LangScene-X的开放词汇定位准确率和语义分割IoU均大幅超越现有方法,拥有接近人类水平的空间理解能力。
在LERF-OVS数据集上,LangScene-X的整体mAcc达80.85%,mIoU达50.52%,较最优基线分别提升31.18%和10.58%;在ScanNet上,整体mIoU更是达到66.54%,超越现有方法14.92%。可视化结果显示,其分割掩码边界更锐利,连“Cabinet”等复杂物体的预测都能超越真实标注。

无论是VR场景构建还是人机交互,LangScene-X有潜力成为核心驱动力,并为自动驾驶、具身智能等场景提供底层技术范式。
论文地址:
https://arxiv.org/abs/2507.02813
项目主页:
https://liuff19.github.io/LangScene-X/
Github仓库:
https://github.com/liuff19/LangScene-X
文章来自于微信公众号“量子位”。


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
