# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
您是否也曾经想过这样的场景:产品经理把idea直接扔给AI编程,然后就能得到完美能用的代码?来自德国弗劳恩霍夫研究所和杜伊斯堡-埃森大学的研究者们刚刚给我们泼了一盆冷水。他们深度访谈了14家公司的18位工程师,发现了一个让人不安的真相:没有任何一位工程师能够直接把需求文档"喂"给LLM并得到可用的代码。这项研究开展于2024年11月至2025年2月


研究者们找来了18位来自不同行业的工程师,包括汽车、银行、电商、航空航天等14个领域。这些工程师中有普通开发者、团队负责人、软件架构师,甚至还有产品负责人。访谈分为两个部分:他们会先问"不用LLM时,您是怎么把需求转化为代码的?",然后再问"用了LLM后,这个过程发生了什么变化?特别是提示词(prompt)里包含了什么内容。"
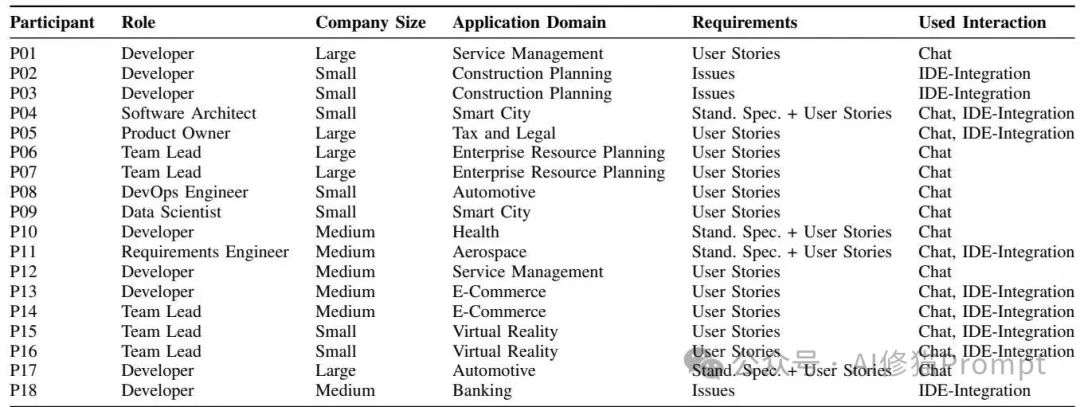
访谈参与者详细信息
结果所有18位工程师都说,传统的需求文档根本没法直接给LLM使用。有位来自健康领域的工程师这样描述他的经历:"我对GPT说'写一个Keithley万用表的命令接口',这个需求直接来自我们的需求目录,但我从来没有得到过可以直接使用的代码。"原因其实很简单:需求文档描述的是"要做什么",而LLM需要知道的是"怎么做"。感兴趣您可以看下这篇《第一性原理的Context Engineering工具、指南》
基于对18位工程师的深度访谈,研究者们提出了一个颠覆性的双重模型理论框架。这个理论揭示了一个残酷的现实:理想化的"需求→LLM→代码"根本不存在,真实的过程要复杂得多。这个框架包含两个核心模型:流程模型和内容模型。
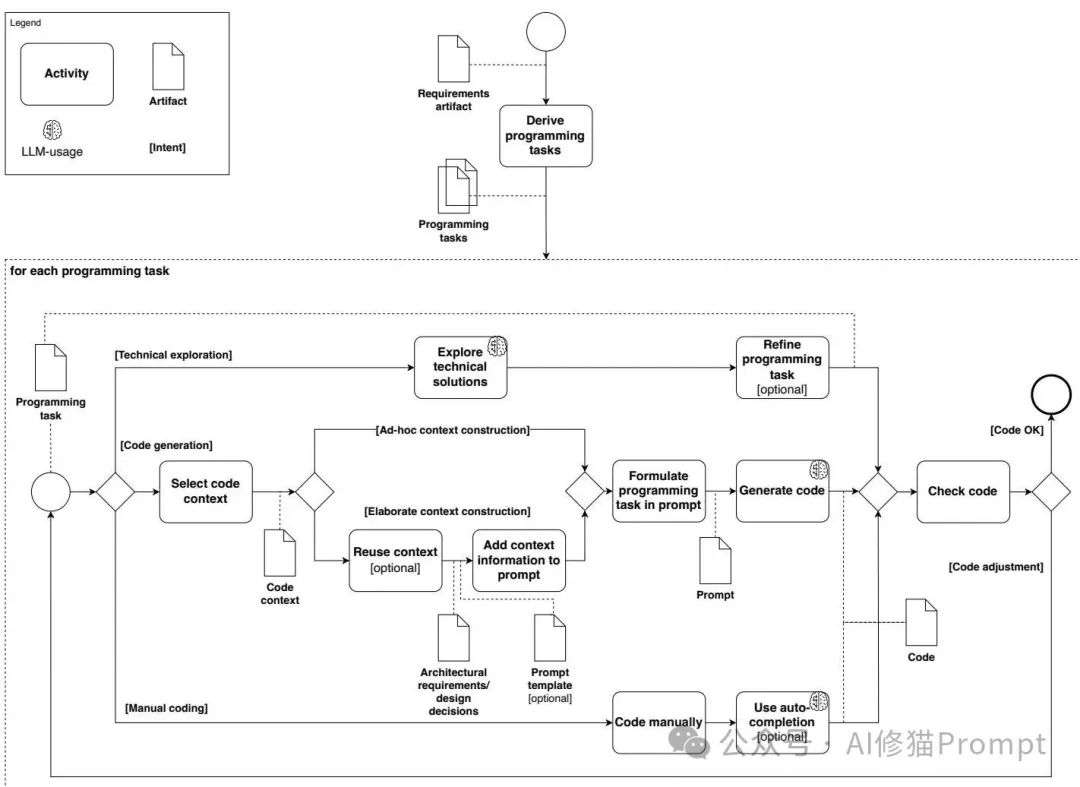
LLM辅助实现的流程模型,展示了从需求到代码的完整过程
第一步:手工分解是不可跨越的鸿沟
工程师们必须先把需求手工分解成具体的编程任务。来自大型企业资源规划公司的团队负责人P06解释他的工作流程:"程序的粗略草图,或者我想如何构建它,我会自己做。我思考剩余部分需要什么,然后考虑放入什么逻辑,需要调用哪个函数,如何连接数据库等等。"有趣的是,这个分解过程并不是LLM带来的新要求,而是传统软件开发就有的必要步骤。
第二步:三种实现模式的灵活组合
研究者们发现,工程师们会根据任务的熟悉程度选择不同的实现模式:
技术探索模式:主要用于不熟悉的任务,工程师会把LLM当作"智能搜索引擎"来了解可能的解决方案。来自服务管理领域的开发者P12称其为"更精准的谷歌替代品"。
代码生成模式:用于熟悉的任务,这时需要提供大量的代码上下文给LLM。来自大型服务管理公司的开发者P01描述她的典型工作流:"我经常复制我已有的代码,然后让模型添加这个功能。所以我已经有了工作代码,现在我希望当无效输入进来时,它能抛出错误。"
手工编码模式:工程师主要还是自己写代码,只是接受LLM的自动补全建议。来自银行业的开发者P18表示:"我要么继续写代码因为建议没有意义,要么我就使用自动补全建议并稍作调整。"
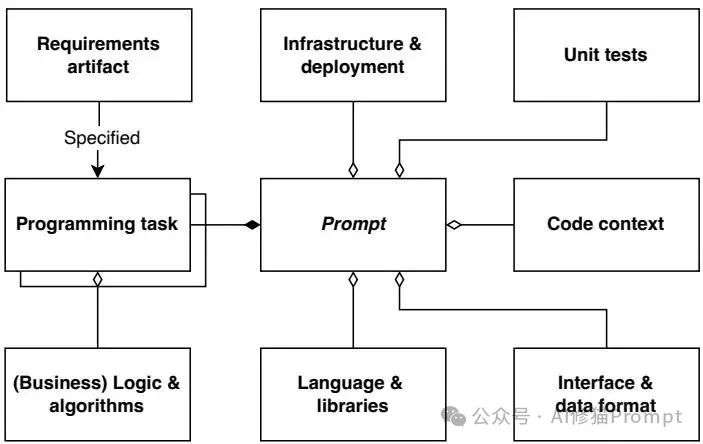
LLM辅助实现的内容模型,显示了有效提示所需的各种信息要素
上下文信息:成败的关键
想要LLM生成有用的代码,光有编程任务还不够,还必须提供大量的上下文信息。来自大型税务与法律业务公司的产品负责人P05,主要使用聊天界面和IDE集成工具,他这样描述公司的情况:"我们有特定的基础设施要求,必须以特定的方式满足,当然Copilot或者任何模型都不知道我们有什么规范。"
五大关键信息要素
研究发现,有效的提示词必须包含以下信息:
我之前写过一篇文章,专门详解在软件工程任务中表现最好的提示词技术,感兴趣您可以看下这篇《14种主流Prompt技术,顶级团队2000次实验,只有这几种真能打》这点我也会同步到我的Agent群员专属IMA知识库“AI修猫Prompt-上下文工程”当中,作为上下文工程体系的一部分,欢迎你来交流!
这个研究还揭示了一个新的技能要求:Prompt Engineering。工程师们现在需要学会如何构建有效的提示,如何管理聊天历史和上下文信息,如何平衡提示工程的投入与代码质量的产出。有趣的是,论文中显示目前没有任何一位工程师把“提示词”当作需要追溯和管理的重要工程产物,这在一些高要求的领域可能成为未来的隐患。
基于这些发现,研究者们指出了几个值得关注的未来发展方向。第一个是需求分解的自动化:能否用AI来辅助需求分解过程?第二个是上下文信息的智能管理:如何让LLM自动获取和管理项目相关的上下文信息?第三个是提示质量的量化评估:如何建立标准来评估提示的有效性?
对正在开发类似GitHub Copilot的产品,建议关注以下几个方面。不要过度宣传LLM的能力,而应该强调它的协作价值。产品应该更好地集成项目上下文,比如自动读取配置文件、API文档和架构约束。还需要提供更好的提示管理功能,让工程师能够保存、复用和优化他们的提示模板。
传统的软件工程活动在LLM时代不仅没有消失,反而至关重要。那种让没有技术背景的领域专家直接通过描述需求就生成完整复杂软件的愿景,目前来看仍然“遥不可及”。开发人员必须利用其专业的软件工程技能,手动进行需求的分解、细化,并为LLM提供精确的技术和架构上下文,才能使其发挥作用。它提醒企业,不能因为LLM的出现就忽视对工程师在需求工程和软件设计方面能力的培养。并且“提示词”目前并未被当作需要追溯和管理的重要工程产物,这在一些高要求的领域可能成为未来的隐患 。
文章来自于微信公众号“AI修猫Prompt”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
