# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如今,强化学习(Reinforcement Learning,RL)在多个领域已取得显著成果。
在实际应用中,具有长时间跨度和稀疏奖励特征的任务非常常见,而强化学习方法在这类任务中的表现仍难令人满意。
传统强化学习方法在此类任务中的探索能力常常不足,因为只有在执行一系列较长的动作序列后才能获得奖励,这导致合理时间内找到有效策略变得极其困难。
假如将模仿学习(Imitation Learning, IL)的思路引入强化学习方法,能否改善这一情况呢?
模仿学习通过观察专家的行为并模仿其策略来学习,通常用于强化学习的早期阶段,尤其是在状态空间和动作空间巨大且难以设计奖励函数的场景。
近年来,模仿学习不仅在传统的强化学习中取得了进展,也开始对大语言模型(LLM)产生一定影响。近日,加州大学伯克利分校的研究者提出了一种名为 Q-chunking 的方法,该方法将动作分块(action chunking)—— 一种在模仿学习中取得成功的技术 —— 引入到基于时序差分(Temporal Difference, TD)的强化学习中。
该方法主要解决两个核心问题:一是通过时间上连贯的动作序列提升探索效率;二是在避免传统 n 步回报引入偏差的前提下,实现更快速的值传播。

如下图 1 左所示,Q-chunking(1)使用动作分块来实现快速的价值回传,(2)通过时间连贯的动作进行有效探索。图 1 右中,本文方法首先在离线数据集上进行 100 万步的预训练(灰色部分),然后使用在线数据更新,再进行另外 100 万步的训练(白色部分)。
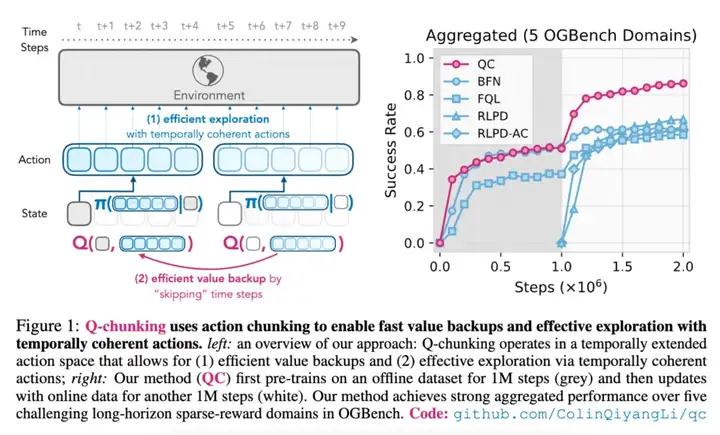
Q-chunking 旨在解决标准强化学习方法在复杂操作任务中存在的关键局限性。
在传统强化学习中,智能体在每一个时间步上逐一选择动作,这常常导致探索策略效率低下,表现为抖动、时间不连贯的动作序列。这一问题在稀疏奖励环境中尤为严重 —— 在此类环境中,智能体必须执行较长的、协调一致的动作序列才能获得有效反馈。
研究者提出了一个关键见解:尽管马尔可夫决策过程中的最优策略本质上是马尔可夫性的,但探索过程却可以从非马尔可夫性、时间上扩展的动作中显著受益。这一观察促使他们将「动作分块」这一原本主要用于模仿学习的策略引入到时序差分学习中。
该方法特别面向离线到在线的强化学习场景(offline-to-online RL),即智能体先从预先收集的数据集中进行学习,再通过在线交互进行微调。这一设定在机器人应用中尤为重要,因为在线数据采集成本高且可能存在安全风险。
Q-chunking 将标准的 Q-learning 扩展至时间扩展的动作空间,使策略不再仅预测单一步骤的动作,而是预测连续 h 步的动作序列。该方法主要包含两个核心组成部分:
扩展动作空间学习
传统方法学习的是针对单步动作的策略 π(aₜ | sₜ) 和 Q 函数 Q (sₜ, aₜ),而 Q-chunking 学习的是:
* 块状策略(Chunked Policy):π_ψ(aₜ:ₜ₊ₕ | sₜ)
* 块状 Q 函数(Chunked Q-function):Q_θ(sₜ, aₜ:ₜ₊ₕ)
核心创新体现在时间差分损失(TD loss)的构造上。块状 Q 函数的更新方式如下:
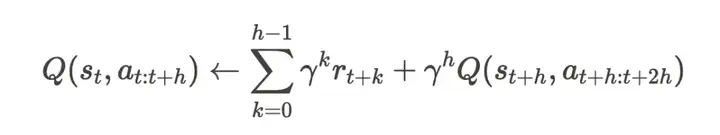
该形式实现了无偏的 h 步的值传播,因为 Q 函数以整个动作序列作为输入,从而消除了传统 n 步回报中存在的离策略偏差(off-policy bias)。
行为约束
为了保证时间上的连贯性探索,并有效利用离线数据,Q-chunking 在扩展动作空间中对学习到的策略施加了行为约束,使其保持接近离线数据分布。该约束表达如下:
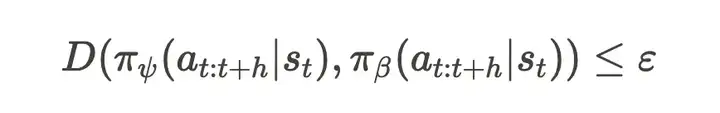
其中,D 表示一种距离度量方法,π_β 是来自离线数据集的行为策略。
研究者展示了Q-chunking框架的两种实现方式:
QC(带有隐式 KL 约束的 Q-chunking)
该分支通过「从 N 个中选择最优」(best-of-N)的采样策略,隐式地施加 KL 散度约束。其方法如下:
1. 在离线数据上训练一个流匹配行为策略 f_ξ(・|s)
2. 对于每个状态,从该策略中采样 N 个动作序列(action chunks)
3. 选择具有最大 Q 值的动作序列:a* = arg max_i Q (s, a_i)
4. 使用该动作序列进行环境交互与 TD 更新
QC-FQL(带有 2-Wasserstein 距离约束的 Q-chunking)
该实现基于 FQL(Flow Q-learning)框架:
1. 保持一个独立的噪声条件策略 μ_ψ(s, z)
2. 训练该策略以最大化 Q 值,并通过正则项使其靠近行为策略
3. 使用一种蒸馏损失函数,对平方的 2-Wasserstein 距离进行上界估计
4. 引入正则化参数 α 来控制约束强度
关于实验环境和数据集,研究者首先考虑 6 个稀疏奖励的机器人操作任务域,任务难度各不相同,包括如下:
来自 OGBench 基准的 5 个任务域:scene-sparse、puzzle-3x3-sparse,以及 cube-double、cube-triple 和 cube-quadruple,每个任务域包含 5 个任务;来自 robomimic 基准中的 3 个任务。
对于 OGBench,研究者使用默认的「play-style」数据集,唯独在 cube-quadruple 任务中,使用了一个规模为 1 亿大小的数据集。
关于基线方法比较,研究者主要使用了以加速「价值回传」为目标的已有方法,以及此前表现最好的「离线到在线」强化学习方法,包括 BFN(best-of-N)、FQL、BFN-n / FQL-n 以及 LPD、RLPD-AC。
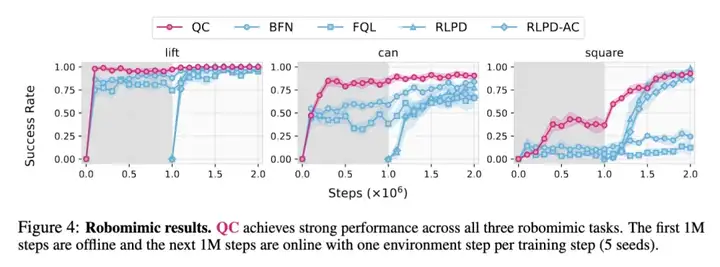
下图 3 中展示了 Q-chunking 与基线方法在 5 个 OGBench 任务域上的整体性能表现,下图 4 中展示了在 3 个 robomimic 任务上的单独性能表现。其中在离线阶段(图中为灰色),QC 表现出具有竞争力的性能,通常可以比肩甚至有时超越了以往最优方法。而在在线阶段(图中为白色),QC 表现出极高的样本效率,尤其是在 2 个最难的 OGBench 任务域(cube-triple 和 quadruple)中,其性能远超以往所有方法(特别是 cube-quadruple 任务)。
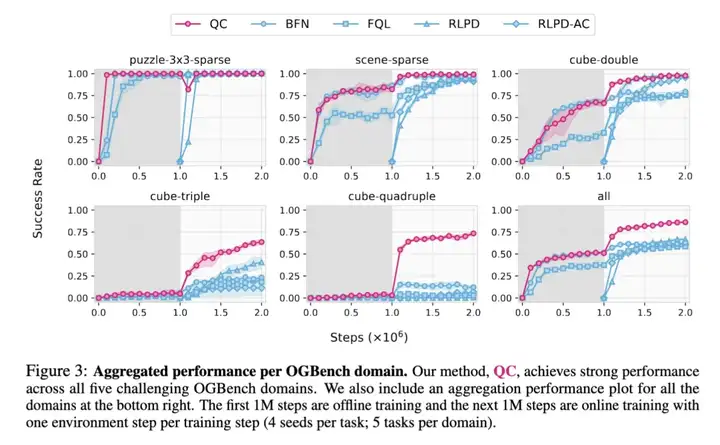
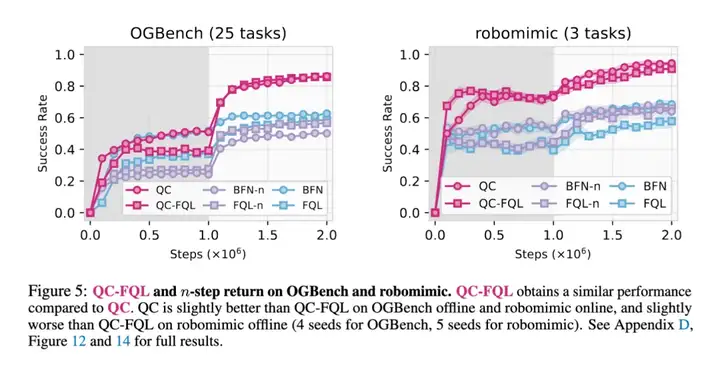
下图 5 为消融实验,比较了 QC 与其变体 QC-FQL、以及 2 种 n 步回报的基线方法(BFN-n 和 FQL-n)。这些 n 步回报基线方法没有利用时间扩展的 critic 或 policy,因此其性能显著低于 QC 和 QC-FQL。实际上,它们的表现甚至常常不如 1 步回报的基线方法 BFN 和 FQL,这进一步突显了在时间扩展动作空间中进行学习的重要性。
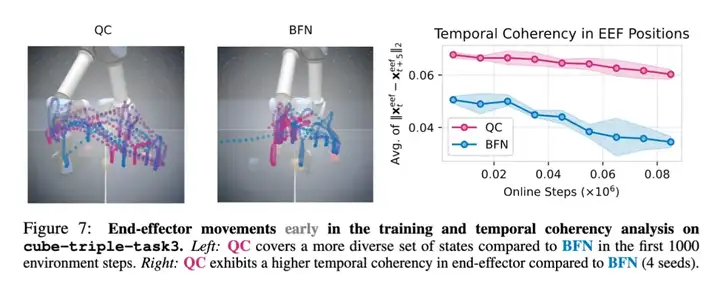
接下来探讨的问题是:为什么动作分块有助于探索?研究者在前文提出了一个假设:动作分块策略能够生成在时间上更连贯的动作,从而带来更好的状态覆盖和探索效果。
为了进行实证,他们首先可视化了训练早期 QC 与 BFN 的末端执行器运动轨迹,具体如下图 7 所示。可以看到,BFN 的轨迹中存在大量停顿(在图像中心区域形成了一个大而密集的簇),特别是在末端执行器下压准备抓取方块时。而 QC 的轨迹中则明显停顿较少(形成的簇更少且更浅),并且其在末端执行器空间中的状态覆盖更加多样化。
为了对动作的时间连贯性进行定量评估,研究者在训练过程中每 5 个时间步记录一次 3D 末端执行器位置,并计算相邻两次位置差向量的平均 L2 范数。如果存在较多停顿或抖动动作,该平均范数会变得较小,因此可以作为衡量动作时间连贯性的有效指标。
正如图 7(右)所示,在整个训练过程中,QC 的动作时间连贯性明显高于 BFN。这一发现表明,QC 能够提高动作的时间连贯性,从而解释了其更高的样本效率。
更多细节内容请参考原论文。
文章来自于“机器之心”,作者“杜伟、冷猫”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
